Panic Mode On (106) Server Problems?
Message boards :
Number crunching :
Panic Mode On (106) Server Problems?
Message board moderation
Previous · 1 . . . 24 · 25 · 26 · 27 · 28 · 29 · Next
| Author | Message |
|---|---|
 Keith Myers Keith Myers Send message Joined: 29 Apr 01 Posts: 13164 Credit: 1,160,866,277 RAC: 1,873 
|
No, I am doing the exact same thing on the FX rigs. I haven't been able to fathom why the 8370 has fallen so far behind the 8350. That is the likely scenario but I haven't detected a large difference in the Arecibo/GBT mix of work between the two systems at casual glance. I haven't conducted an extensive forensic analysis with antenna origin cataloging. The same here with mostly Arecibo work on all three systems with brief spurts of GBT work. The 8370 is SLOWLY coming back to its normal RAC. How is the project RAC determined? I always thought the project pulled the stats for the host out of the statistics_setiathome.berkeley.edu.xml file on each computer. And that file is what is used to plot the statistics curve on the Statistics tab in the Manager. As I stated, my Statistics curve has been flatlined at 50K for the last month. It never showed the precipitous plummet in my RAC that the project is showing on my Host numbers for the 8350 host. 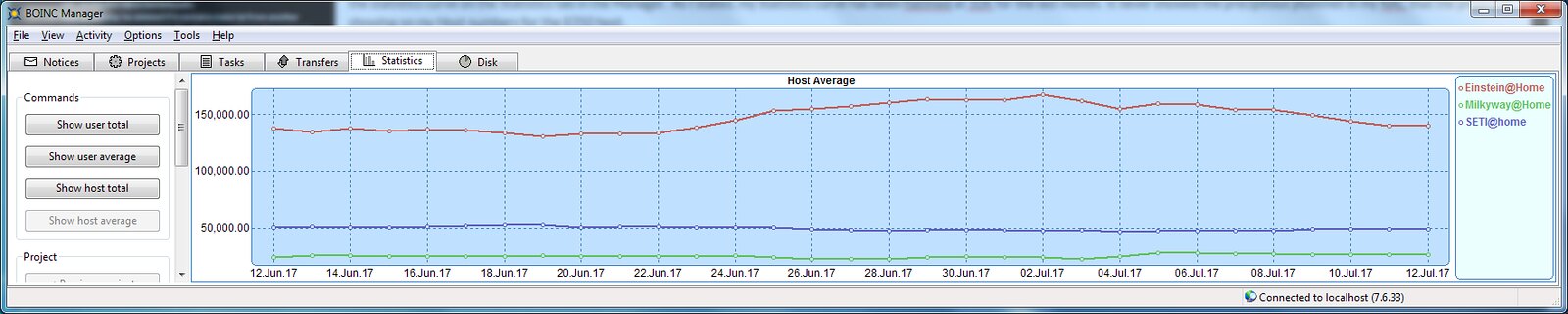 Keith-Windows7 statistics Keith-Windows7 statisticsSeti@Home classic workunits:20,676 CPU time:74,226 hours   A proud member of the OFA (Old Farts Association) ID: 1877900 · |
|
HAL9000 Send message Joined: 11 Sep 99 Posts: 6534 Credit: 196,805,888 RAC: 57
|
No, I am doing the exact same thing on the FX rigs. I haven't been able to fathom why the 8370 has fallen so far behind the 8350. BOINC updates recent average credit "RAC" when new credit is granted. A decay value is factored in so that it is "recent". function decay_average($avg, $avg_time, $now = 0) {
$M_LN2 = 0.693147180559945309417;
$credit_half_life = 86400 * 7;
if ($now == 0) {
$now = time();
}
$diff = $now - $avg_time;
$weight = exp(-$diff * $M_LN2/$credit_half_life);
$avg *= $weight;
return $avg;
}Sometimes I think the decay function pulls numbers out of nowhere when I see a host RAC drop 50% for seemingly no reason. I believe that each time the BOINC client does a project update it also updates the statistics_PROJECT.xml file. Then BOINC Manager will read the xml and make a neat little graph based on the stored values. If you want you can read the expavg values directly from the xml file. <daily_statistics> <day>1499731200.000000</day> <user_total_credit>168746186.262877</user_total_credit> <user_expavg_credit>60883.935743</user_expavg_credit> <host_total_credit>11508519.704933</host_total_credit> <host_expavg_credit>6851.901127</host_expavg_credit> </daily_statistics> At the super compressed scale of your image each one of the vertical lines in the chart would possibly be a difference of ~5000. So it looks like on 2017-07-04 your RAC was ~45,000 & on 2017-06-18 it was ~55,000. SETI@home classic workunits: 93,865 CPU time: 863,447 hours  Join the [url=http://tinyurl.com/8y46zvu]BP6/VP6 User Group[ Join the [url=http://tinyurl.com/8y46zvu]BP6/VP6 User Group[
ID: 1877909 · |
|
Keith Myers Send message Joined: 29 Apr 01 Posts: 13164 Credit: 1,160,866,277 RAC: 1,873
|
Thanks for the explanation on how RAC is calculated Hal. Yes, you are correct. I never considered the compression in the vertical height in the graph to fit all projects. I remembered that you can plot individual projects separately. I did in fact hit the low spot you mention. 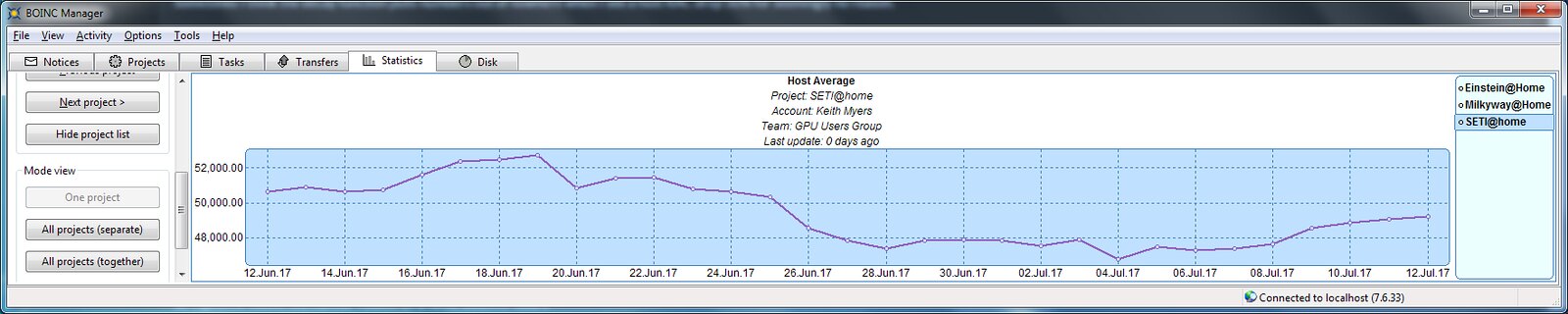 SETI statistics SETI statisticsI guess I just had a particularly poor paying mix of work on that host compared to the 8350 host over the last month. Seti@Home classic workunits:20,676 CPU time:74,226 hours A proud member of the OFA (Old Farts Association) ID: 1877918 · |
|
HAL9000 Send message Joined: 11 Sep 99 Posts: 6534 Credit: 196,805,888 RAC: 57
|
Thanks for the explanation on how RAC is calculated Hal. Yes, you are correct. I never considered the compression in the vertical height in the graph to fit all projects. I remembered that you can plot individual projects separately. I did in fact hit the low spot you mention. With all the different factors it is sometimes hard to determine which of them cause the short term ups and downs. So use a script to average the values in the stats file. Right now I read all of the values so it looks like this. Host 8130144 Average: 26897 for 244 days I think I'm going to add some other output as well. Like averages for the 30, 60, & 180 days as well as the total credit gained for each time period. SETI@home classic workunits: 93,865 CPU time: 863,447 hours Join the [url=http://tinyurl.com/8y46zvu]BP6/VP6 User Group[
ID: 1878043 · |
|
Grant (SSSF) Send message Joined: 19 Aug 99 Posts: 13797 Credit: 208,696,464 RAC: 304 
|
Just took over a minute for the web site to come up, and the last couple of Scheduler requests timed out with a "Couldn't connect to server" error. EDIT- Now the Scheduler is responding, but it won't give me any more work. EDIT- And then a whole load came down. The randomness of WU allocation makes me suspect it's tied in with the randomness of Credit New's determination of credit to allocate to each WU. Grant Darwin NT ID: 1878337 · |
|
Grant (SSSF) Send message Joined: 19 Aug 99 Posts: 13797 Credit: 208,696,464 RAC: 304
|
Just took over a minute for the web site to come up, and the last couple of Scheduler requests timed out with a "Couldn't connect to server" error. And now back to not sending tasks. Grant Darwin NT ID: 1878341 · |
|
Iona Send message Joined: 12 Jul 07 Posts: 790 Credit: 22,438,118 RAC: 0 
|
As a fairly recent user of using an NVidia GPU for the project (my first NVidia card was actually a new Riva TNT - that's a while ago!), the thing that annoys me most, is when a GPU task or even several tasks are completed and then I get a load of CPU tasks sent and no GPU tasks. I then end up, having to suspend GPU work, change to 100% CPU use, to deal with the ever increasing number of CPU tasks, periodically. I'd rather have no more CPU tasks being sent! More frustrating still, are the messages from the server that say that AMD/ATI GPU tasks are available, but my preferences are set not to accept them....why would I accept them if I don't have an AMD/ATI GPU in the thing? Yes, I also get the same message about the Intel GPU, but obviously, using that was not going to involve a 'free lunch'. Don't take life too seriously, as you'll never come out of it alive! ID: 1878433 · |
Brent Norman  Send message Joined: 1 Dec 99 Posts: 2786 Credit: 685,657,289 RAC: 835 
|
Iona, If you use app_config to limit the number of running cores (reserve) while GPU tasks are running, the CPU cores will automatically be free to start crunching when GPU tasks run dry. ID: 1878438 · |
|
Iona Send message Joined: 12 Jul 07 Posts: 790 Credit: 22,438,118 RAC: 0
|
Ah, thanks for that, Brent. That's useful to know. Don't take life too seriously, as you'll never come out of it alive! ID: 1878443 · |
|
Brent Norman Send message Joined: 1 Dec 99 Posts: 2786 Credit: 685,657,289 RAC: 835
|
Hmm, they're latter than normal for maintenance this week. ID: 1878924 · |
|
Iona Send message Joined: 12 Jul 07 Posts: 790 Credit: 22,438,118 RAC: 0
|
Famous last words, eh, Brent? Don't take life too seriously, as you'll never come out of it alive! ID: 1878925 · |
|
Brent Norman Send message Joined: 1 Dec 99 Posts: 2786 Credit: 685,657,289 RAC: 835
|
Yeap, very soon after that .... POOF ID: 1878932 · |
|
Speedy Send message Joined: 26 Jun 04 Posts: 1643 Credit: 12,921,799 RAC: 89 
|
Shortest data tape I have seen in a while 28ja08aa 2.76 GB. I wonder whether or not it will be full of shorties because of the short tape. I doubt it will be. Man would be funny if it was though 
ID: 1879003 · |
|
rob smith Send message Joined: 7 Mar 03 Posts: 22327 Credit: 416,307,556 RAC: 380
|
It will be the end of a tape that has already been part-processed. As recorded the tapes are 50Gb, but if the processing get stalled part way through for any reason and then re-started the tape will appear to be under-sized. Bob Smith Member of Seti PIPPS (Pluto is a Planet Protest Society) Somewhere in the (un)known Universe? ID: 1879011 · |
|
Speedy Send message Joined: 26 Jun 04 Posts: 1643 Credit: 12,921,799 RAC: 89
|
It will be the end of a tape that has already been part-processed. Thank you for the above information. Another piece of information would great to know when tape started to be split and when it ended/What tape is going to be split next. I cannot see the speech have been added anytime soon as probably not a lot of people would be interested in this information
ID: 1879018 · |
|
Cosmic_Ocean Send message Joined: 23 Dec 00 Posts: 3027 Credit: 13,516,867 RAC: 13
|
Well, that was a fun run of APs for a couple weeks there. Looks like we're back to 2008 tapes again, so the 16 and 17 tapes seem like they're probably done. Can you tell it's been a while since we had any of them? 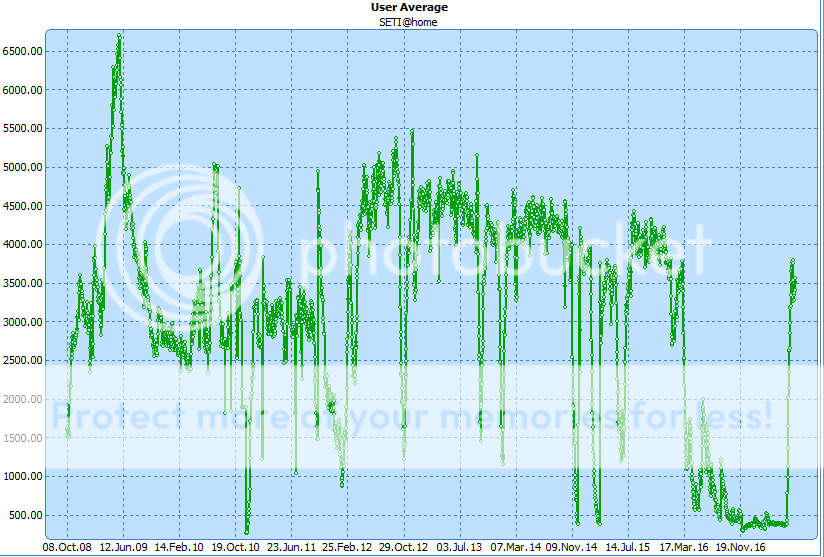 Linux laptop: record uptime: 1511d 20h 19m (ended due to the power brick giving-up) ID: 1879097 · |
|
Keith Myers Send message Joined: 29 Apr 01 Posts: 13164 Credit: 1,160,866,277 RAC: 1,873
|
OK, am I imagining this or did the project put more validators online this Tuesday? I was used to seeing about a 400 task difference between Valid tasks and Pending tasks. Now, on all three crunchers, the Valid tasks are almost equal to the Pending tasks. Is this just circumstance or did something change with the servers? Seti@Home classic workunits:20,676 CPU time:74,226 hours A proud member of the OFA (Old Farts Association) ID: 1879144 · |
|
Brent Norman Send message Joined: 1 Dec 99 Posts: 2786 Credit: 685,657,289 RAC: 835
|
I noticed that too awhile ago, but never really paid much attention to what the numbers were before, but definitely higher. As I watch now, my numbers are going up again. ID: 1879160 · |
|
Keith Myers Send message Joined: 29 Apr 01 Posts: 13164 Credit: 1,160,866,277 RAC: 1,873
|
I noticed that too awhile ago, but never really paid much attention to what the numbers were before, but definitely higher. Nope, you are correct. Things are going back to normal with about 400 tasks difference. Must have just been a happy convergence between the two functions for a brief moment. Seti@Home classic workunits:20,676 CPU time:74,226 hours A proud member of the OFA (Old Farts Association) ID: 1879169 · |
|
bluestar Send message Joined: 5 Sep 12 Posts: 7184 Credit: 2,084,789 RAC: 3 |
Guess such a thing is a "Probability" issue. ID: 1879208 · |

©2024 University of California
SETI@home and Astropulse are funded by grants from the National Science Foundation, NASA, and donations from SETI@home volunteers. AstroPulse is funded in part by the NSF through grant AST-0307956.