My 2990WX
Message boards :
Number crunching :
My 2990WX
Message board moderation
Previous · 1 · 2 · 3 · 4 · 5 · 6 · 7 · Next
| Author | Message |
|---|---|
 Keith Myers Keith Myers Send message Joined: 29 Apr 01 Posts: 13164 Credit: 1,160,866,277 RAC: 1,873 
|
I'm in the middle of testing another approach to the memory bandwidth issue. I just switched from UMA mode to NUMA mode on my 2920X and the biggest difference is in the memory latencies. I went from 99ns down to 60ns which is what my memory latencies are with the Ryzen 2700X. The memory bandwidth halved as expected from 96Mb/sec to 48MB/sec but the peak memory transfers went from 86MB/sec to 99MB/sec. Since I rarely use more than about 3-4GB of memory for running the desktop, background apps and BOINC, I shouldn't have to need memory bandwidth. I am more interested in how fast the cpu tasks can access memory for their computations. After I have finished my memory stability testing I will put the host back online and see if my cpu task completion times come down and match my Ryzen 2700X times. Before this change, I was running cpu tasks in around 48 minutes. I'm hoping to get the cpu tasks down to the same 30 minutes time of the 2700X. The differences in memory clocks is only 400Mhz and probably does not matter that much. I guess I will find out. Seti@Home classic workunits:20,676 CPU time:74,226 hours   A proud member of the OFA (Old Farts Association) ID: 1970200 · |
|
ML1 Send message Joined: 25 Nov 01 Posts: 20291 Credit: 7,508,002 RAC: 20 
|
Please excuse me if I'm reading you wrong: Don't get too hung up on the completion times for individual WUs? The significant factor is what total throughput is achieved for an aggregate of WUs... Typically, using HT/SMT will slow down individual tasks, but can give a small overall speedup for multiple tasks interleaving their execution across the CPU resources... Personal experience suggests a maximum speedup with Intel HT of about +30% over multiple tasks (throughput of 130%) over that of running non-HT (throughput a nominal 100%). However, if the CPU cache becomes overloaded/poisoned, or if there is contention for a CPU resource, then you can see some drastic slowdowns in trying to use HT! I've not acquired any recent hardware to test comparable effects for AMD. Good sleuthing! Happy cool crunchin', Martin "HT" (Intel "Hyper Threading") is Intel's Marketing jargon for "SMT" (Simultaneous Multi-Threading) as is now utilised by AMD for their Zen CPUs: where a single physical CPU core is shared (multiplexed) between two CPU tasks. See new freedom: Mageia Linux Take a look for yourself: Linux Format The Future is what We all make IT (GPLv3) ID: 1970210 · |
|
Keith Myers Send message Joined: 29 Apr 01 Posts: 13164 Credit: 1,160,866,277 RAC: 1,873
|
I still use SMT. No changes there. Still running the same number of tasks and threads. Just running with local NUMA mode memory instead of UMA mode memory access. If I complete two tasks per hour per thread at 30 minutes each instead of two tasks per 90 minutes at 45 minutes each, my aggregate for the day goes up. Seti@Home classic workunits:20,676 CPU time:74,226 hours A proud member of the OFA (Old Farts Association) ID: 1970213 · |
|
Tom M Send message Joined: 28 Nov 02 Posts: 5124 Credit: 276,046,078 RAC: 462 |
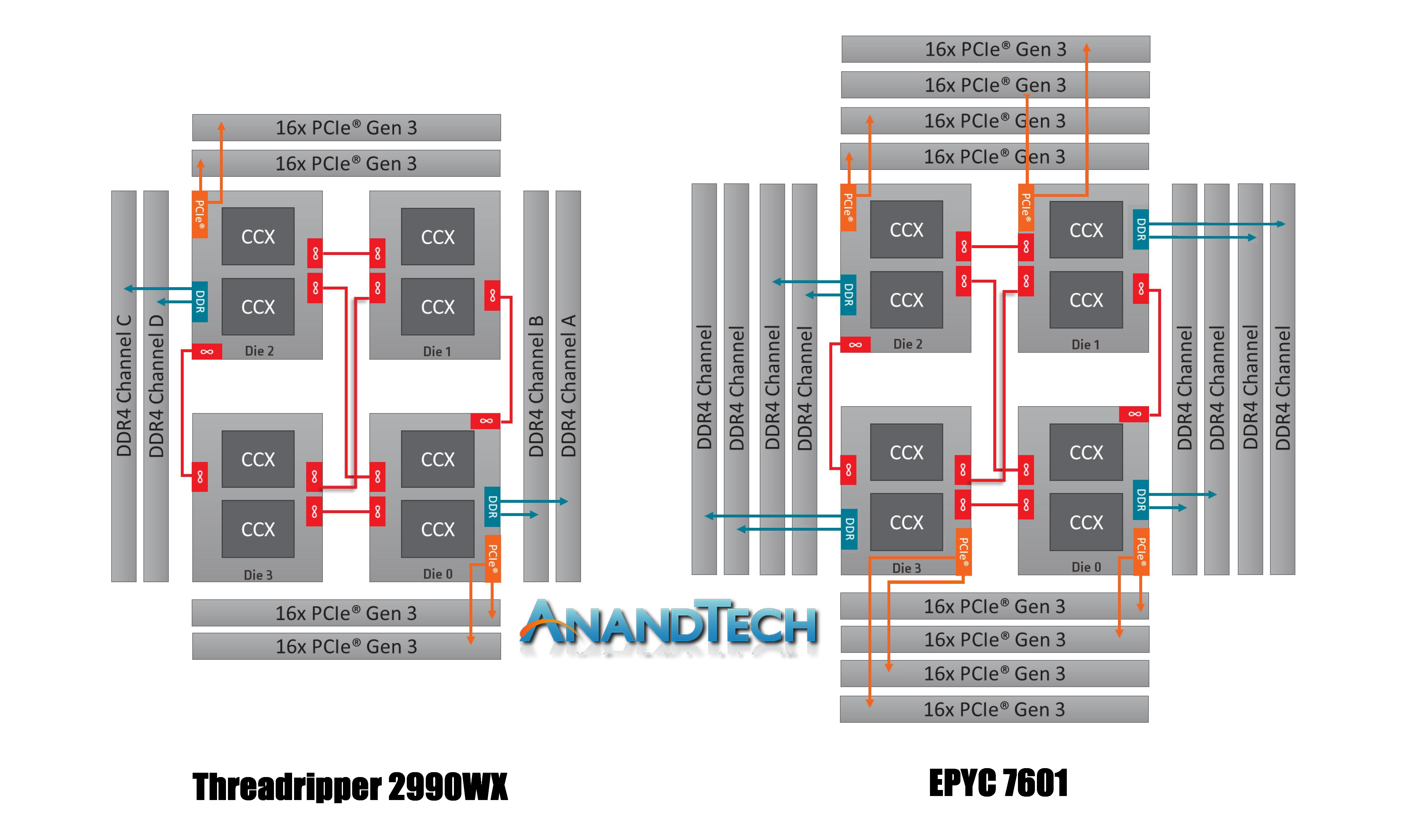
Please excuse me if I'm reading you wrong: The Threadripper 2 (and 1, I guess) suffer from a memory model that causes 1/2 of the cpus to not have direct access to the ram. The article I posted above seems to do a good job of explaining the issue. And as such it is a hardware limitation that can only be changed by a redesigned cpu/cpu socket. Since AMD promised to not change the TR2 socket for 2 years, I don't expect to get out of this particular design limitation soon. The times I quote are the "average" estimated completion times. I have had averages north of 2 hours for 56-60 cores down to someplace near 47 minutes for 30 cores. After taking a short look at 40 cores again and not seeing much improvement for a short run with the faster ram I am back at 30 cores (25 cpu, 3 gpu). I am still looking for the "best" sweet spot but it appears to probably be near 30 cores. Tom A proud member of the OFA (Old Farts Association). ID: 1970268 · |
|
Keith Myers Send message Joined: 29 Apr 01 Posts: 13164 Credit: 1,160,866,277 RAC: 1,873
|
No, only your chip the 2990WX and the 2970WX suffer from half the dies not having direct access. My chip, the 2920X and the 2950X have both dies with direct access to memory. Only the 4 die TR suffer from one pair of dies with no direct memory access. Look at the second diagram in your link showing the 2950X TR. Seti@Home classic workunits:20,676 CPU time:74,226 hours A proud member of the OFA (Old Farts Association) ID: 1970270 · |
|
ML1 Send message Joined: 25 Nov 01 Posts: 20291 Credit: 7,508,002 RAC: 20
|
I am still looking for the "best" sweet spot but it appears to probably be near 30 cores. Unless the NUMA scheduling works to give some advantage, then you might see the best results are with disabling the SMT to run natively one thread per core with minimum overhead/latency...? I'm guessing that running non-SMT will also make best use of all of the CPU cache for a speedup also. Good sleuthing! Happy cool fast crunchin', Martin See new freedom: Mageia Linux Take a look for yourself: Linux Format The Future is what We all make IT (GPLv3) ID: 1970291 · |
|
Tom M Send message Joined: 28 Nov 02 Posts: 5124 Credit: 276,046,078 RAC: 462 |
I am still looking for the "best" sweet spot but it appears to probably be near 30 cores. For my bios, NUMA appears to be turned on by default. I think I tried a short run with UMA on CL16 ram that seemed to show it was slower. But I also think I was running 40 cores. So another experiment could be SMT turned off (so now max is 32 threads/cores) and UMA turned on. On the grounds of theory, I would always assume UMA would be slower. If the test load is still 26 threads, then a whole lot more of the processing is being done on non-direct memory access cpus which should slow things down. When you add UMA which means even the direct access cpus are going to be accessing memory in a slower way, it "oughta" be slower. Sigh, yet another test :) Tom A proud member of the OFA (Old Farts Association). ID: 1970306 · |
|
ML1 Send message Joined: 25 Nov 01 Posts: 20291 Credit: 7,508,002 RAC: 20
|
I am still looking for the "best" sweet spot but it appears to probably be near 30 cores. Hey! One change at a time! ;-) So... What is actually being done to what effect with the BIOS NUMA/UMA control? If your system really is NUMA-aware, then my guess is that the combination of no-SMT + NUMA should give the lowest latencies and maximise the best use of CPU cache... But that's just a guess upon reality... ;-) Happy cool crunchin', Martin See new freedom: Mageia Linux Take a look for yourself: Linux Format The Future is what We all make IT (GPLv3) ID: 1970315 · |
|
Keith Myers Send message Joined: 29 Apr 01 Posts: 13164 Credit: 1,160,866,277 RAC: 1,873
|
My mobo defaults to UMA. I had to change off Auto to Channel mode to enable NUMA. Seti@Home classic workunits:20,676 CPU time:74,226 hours A proud member of the OFA (Old Farts Association) ID: 1970334 · |
|
Tom M Send message Joined: 28 Nov 02 Posts: 5124 Credit: 276,046,078 RAC: 462 |
I thought that too. I first read that "channel" mode enabled NUMA, then I read some place else that channel mode disabled NUMA :( So I am basing my claim that I have NUMA turned on, on that. Hmmmmm..... I remember where I got the "channel" but I don't remember where I got the contradiction. Tom A proud member of the OFA (Old Farts Association). ID: 1970347 · |
|
Tom M Send message Joined: 28 Nov 02 Posts: 5124 Credit: 276,046,078 RAC: 462 |
Just found direction for turning NUMA on in the MSI forum, said "channel" so I have turned it on. Now to run it long enough to see what changes. Since we are now getting tasks with tasks with more varied run times this may take a while to see how it shakes out. Tom A proud member of the OFA (Old Farts Association). ID: 1970354 · |
|
Keith Myers Send message Joined: 29 Apr 01 Posts: 13164 Credit: 1,160,866,277 RAC: 1,873
|
A real easy check is to run the Intel Memory Latency Checker or MLC. First set the BIOS to run UMA mode and notice the MLC output describes the run as UMA with distributed memory nodes. Then change to Channel and run MLC again and you will see the output described as NUMA and the nodes are local to each die. You should see a big change in the latencies between the two modes. Intel Memory Latency Checker Installation Intel® MLC supports both Linux and Windows. Linux Copy the mlc binary to any directory on your system Intel® MLC dynamically links to GNU C library (glibc/lpthread) and this library must be present on the system Root privileges are required to run this tool as the tool modifies the H/W prefetch control MSR to enable/disable prefetchers for latency and b/w measurements. Refer readme documentation on running without root privileges MSR driver (not part of the install package) should be loaded. This can typically be done with 'modprobe msr' command if it is not already included. Install the msr-tools package and then modprobe msr. Then go to the directory with the unpacked MLC and open a root terminal and start the app with ./mlc. Seti@Home classic workunits:20,676 CPU time:74,226 hours A proud member of the OFA (Old Farts Association) ID: 1970357 · |
|
Tom M Send message Joined: 28 Nov 02 Posts: 5124 Credit: 276,046,078 RAC: 462 |
A real easy check is to run the Intel Memory Latency Checker or MLC. Thank you. Sorry for the delay in replying. I am already in the NUMA mode and haven't decided if I want to switch back yet. I finally got all the directions read, everything installed and got a test run w/o seti processing. I have already run it once using SUDO so this is also in root mode. tom@EJS-GIFT:~/Downloads$ cd ml_test
tom@EJS-GIFT:~/Downloads/ml_test$ cd Linux
tom@EJS-GIFT:~/Downloads/ml_test/Linux$ ./mlc
Intel(R) Memory Latency Checker - v3.6
Measuring idle latencies (in ns)...
Numa node
Numa node 0 1 2 3
0 67.0 - 106.0 -
1 108.7 - 105.1 -
2 105.9 - 66.9 -
3 105.2 - 108.7 -
Measuring Peak Injection Memory Bandwidths for the system
Bandwidths are in MB/sec (1 MB/sec = 1,000,000 Bytes/sec)
Using all the threads from each core if Hyper-threading is enabled
Using traffic with the following read-write ratios
ALL Reads : ^C
Exiting...
If I am inferring correctly, the intersections of 0,0 and 2,2 are the two cpu chips with direct memory access and the latency reports. So pretty much anything but the direct access is going to be nearly the exact same slowdown. I have a little time right now. I will re-boot and reset the memory channel to interweave. Tom A proud member of the OFA (Old Farts Association). ID: 1970511 · |
|
Tom M Send message Joined: 28 Nov 02 Posts: 5124 Credit: 276,046,078 RAC: 462 |
Actually, I reset it to "auto" and got this result. om@EJS-GIFT:~/Downloads/ml_test$ cd Linux
tom@EJS-GIFT:~/Downloads/ml_test/Linux$ ls
mlc mlc_avx512 redist.txt
tom@EJS-GIFT:~/Downloads/ml_test/Linux$ sudo ./mlc
[sudo] password for tom:
Intel(R) Memory Latency Checker - v3.6
Measuring idle latencies (in ns)...
Numa node
Numa node 0 1 2 3
0 67.7 - 105.8 -
1 108.8 - 105.2 -
2 105.9 - 67.4 -
3 105.1 - 108.6 -
Measuring Peak Injection Memory Bandwidths for the system
Bandwidths are in MB/sec (1 MB/sec = 1,000,000 Bytes/sec)
Using all the threads from each core if Hyper-threading is enabled
Using traffic with the following read-write ratios
ALL Reads : ^C
Exiting...
tom@EJS-GIFT:~/Downloads/ml_test/Linux$ ^C
tom@EJS-GIFT:~/Downloads/ml_test/Linux$
Which implies that the NUMA mode is the "default". I think? It has about 4 choices including auto, channel and something about chip etc. Tom A proud member of the OFA (Old Farts Association). ID: 1970516 · |
|
Keith Myers Send message Joined: 29 Apr 01 Posts: 13164 Credit: 1,160,866,277 RAC: 1,873
|
This is what I get in Auto or UMA mode. root@Numbskull:/home/keith/Downloads/Utils/MLC# ./mlc Intel(R) Memory Latency Checker - v3.5 Measuring idle latencies (in ns)... Memory node Socket 0 1 0 98.9 98.8 1 98.9 98.8 This is what I get in Channel or NUMA mode. root@Numbskull:/home/keith/Downloads/Utils/MLC# ./mlc Intel(R) Memory Latency Checker - v3.5 Measuring idle latencies (in ns)... Numa node Numa node 0 1 0 60.6 99.8 1 102.3 61.1 But I ran for a half day yesterday in NUMA mode with its better memory latency speeds and higher transaction speeds . . . but I failed to notice a single improvement in any of my cpu or gpu task times. Plus, the system locked up at 3:30AM this morning and was down until I got up and noticed it. So I reverted back to my previous and stable Auto memory configuration in UMA mode since it apparently has no positive or negative effect on task times. Seti@Home classic workunits:20,676 CPU time:74,226 hours A proud member of the OFA (Old Farts Association) ID: 1970531 · |
|
Tom M Send message Joined: 28 Nov 02 Posts: 5124 Credit: 276,046,078 RAC: 462 |
This is what I get in Auto or UMA mode. Unless I run into some spare time earlier I will try out each of the options I found in the bios menu that includes "channel" on monday and see if any of them cause it to not display the "numa" title. Otherwise I may be looking in the wrong location in the bios. But that is the only "channel" I have found. Tom A proud member of the OFA (Old Farts Association). ID: 1970623 · |
Brent Norman  Send message Joined: 1 Dec 99 Posts: 2786 Credit: 685,657,289 RAC: 835 
|
Numa node 0 1 2 3
0 67.7 - 105.8 -
1 108.8 - 105.2 -
2 105.9 - 67.4 -
3 105.1 - 108.6 - With only 2 sticks of CL14 RAM with the 2990WX, you could very well be better off with your 4 sticks of CL16 in it.Go back to your Diagram and see that only 1/4 of the cores have direct memory access now. 
ID: 1970633 · |
|
Tom M Send message Joined: 28 Nov 02 Posts: 5124 Credit: 276,046,078 RAC: 462 |
That's odd. I have 4 sticks of CL14 ram. I haven't read the docs. So I hadn't realized that something about this info seemed to indicate that I only had 2 sticks. Both the bios and the task manager agree that I have 32 MB of ram. And the bios is recognizing 4 sticks. Tom A proud member of the OFA (Old Farts Association). ID: 1970675 · |
|
Brent Norman Send message Joined: 1 Dec 99 Posts: 2786 Credit: 685,657,289 RAC: 835
|
OK, sorry. I misread the chart in my early morning blurry eyed state as being channel 0,1,2,3 being not fully occupied. ID: 1970685 · |
|
Tom M Send message Joined: 28 Nov 02 Posts: 5124 Credit: 276,046,078 RAC: 462 |
OK, sorry. I misread the chart in my early morning blurry eyed state as being channel 0,1,2,3 being not fully occupied. I have looked at the directions/manual and I would, based on the examples, come to the same conclusion as you. The columns across the top appear to be Numa clusters that I would have assumed meant banks of memory. The MB manual claims I have a quad channel MB. So I am confused. It seems like each pair of memory channels is being treated as a single NUMA resource. Since each direct access cpu chip has 2 channel lines coming out of it in the block diagram I can see how it might come up that way. I have even loaded the defaults for the bios and got the same format (it probably was a bit slower though :) There are about 3 other settings I haven't tried yet. And I want to see if they generate different node results in the ml test. Back in a bit. Tom A proud member of the OFA (Old Farts Association). ID: 1970758 · |
{kind=link}

©2024 University of California
SETI@home and Astropulse are funded by grants from the National Science Foundation, NASA, and donations from SETI@home volunteers. AstroPulse is funded in part by the NSF through grant AST-0307956.