Panic Mode On (78) Server Problems?
Message boards :
Number crunching :
Panic Mode On (78) Server Problems?
Message board moderation
Previous · 1 . . . 4 · 5 · 6 · 7 · 8 · 9 · 10 . . . 22 · Next
| Author | Message |
|---|---|
Richard Haselgrove  Send message Joined: 4 Jul 99 Posts: 14650 Credit: 200,643,578 RAC: 874 
|
I'm starting to get the hang of this. If your cache is a long way below normal, it helps to reduce your cache size settings - that way you're not asking for so much in one go. When you're recovering from dehydration, take small sips of water, not great big gulps. ID: 1302310 · |
 Fred J. Verster Fred J. Verster Send message Joined: 21 Apr 04 Posts: 3252 Credit: 31,903,643 RAC: 0 
|
I'm starting to get the hang of this. If your cache is a long way below normal, it helps to reduce your cache size settings - that way you're not asking for so much in one go. So very truth, (in both cases), a smaller, f.i. 3 (or less) and an additionel 2 (or 1) days does work better, also has a shorter turn around time. Less work to report in one go and less work needed per day, if we * all* ask for 10 + 10 days, we're shure in for SERVER trouble... :-\ In Holland we have a saying : a donkey doesn't hit the same stone twice. ID: 1302324 · |
|
tbret Send message Joined: 28 May 99 Posts: 3380 Credit: 296,162,071 RAC: 40 
|
I've just had a note back from Eric: Richard, The LAST thing I want to do is get into some sort of trouble, but I read this several hours ago and it's been bugging me ever since. Does Eric know you couldn't report 6 tasks any better than you could report 6,000? I'm not talking about "limiting" the reporting to 6 at a time. I'm saying that if all I had was 6 tasks, I couldn't report them. If there's some really esoteric reason limiting a machine to 20 work units means that another machine would be able to report 6, I can't fathom it. I can't even make-up a story that sounds plausible. Nor do I understand why using a proxy would eliminate the problem with reporting. I can't invent a reason that this would be better or worse restricting work units in progress. I already KNOW I don't know what I'm talking about, but it would make me feel better if someone would explain in layman's terms how Eric's fix might fix a problem that can be overcome by using a proxy. Methinks Eric "knows" what the problem is; but he really doesn't. ID: 1302394 · |
kittyman  Send message Joined: 9 Jul 00 Posts: 51468 Credit: 1,018,363,574 RAC: 1,004
|
Well, the kitties won't be happy having their caches limited, but I guess if that's what it takes to right the ship........ "Freedom is just Chaos, with better lighting." Alan Dean Foster 
ID: 1302396 · |
|
tbret Send message Joined: 28 May 99 Posts: 3380 Credit: 296,162,071 RAC: 40
|
Well, the kitties won't be happy having their caches limited, but I guess if that's what it takes to right the ship........ You know what? I've just edited this message away. It doesn't matter. The obvious doesn't matter, the occult doesn't matter, it just doesn't matter. ID: 1302401 · |
|
kittyman Send message Joined: 9 Jul 00 Posts: 51468 Credit: 1,018,363,574 RAC: 1,004
|
I didn't say I agreed with it, or understand the logic behind it. But, I am not Eric. Things went south after last Tuesday's outage. And personally, I don't see what cache sizes have anything to do with it. All was working fine with AP out of the picture. Caches were filled, comms were good, all appeared to be well. AP fired up, and everything went to Hades in a handbasket. Could be coincidence, I dunno. Splitters are off now, and the bandwidth is probably gonna stay maxxed resending ghost tasks for quite a while. And I stand corrected, tbret.... It does appear that there is a gremlin in the scheduler, and bandwidth is NOT the only problem right now. "Freedom is just Chaos, with better lighting." Alan Dean Foster
ID: 1302403 · |
|
Keith White Send message Joined: 29 May 99 Posts: 392 Credit: 13,035,233 RAC: 22
|
Well all's right with the world now. Ghosts have been downloaded, scheduler requests are working. Okay there aren't any new units being made right now but the odd updating behavior and ghost generation is fixed at least for now. Just waiting for the cricket graph to drop off as the download backlog is cleared up. Edit: My only problem now is I have a full 6 day queue for my ATI MB cruncher but only about 2 days for the CPU MB cruncher. "Life is just nature's way of keeping meat fresh." - The Doctor ID: 1302404 · |
|
musicplayer Send message Joined: 17 May 10 Posts: 2430 Credit: 926,046 RAC: 0 |
I get the sense that there are currently many tasks which have been returned to the server which lists as "Completed, waiting for validation". Meaning that a wingman or two still has not completed his or her task and therefore the task in question is unable to become validated. Anyway, deadlines in this project are quite generous, at least when comparing with PrimeGrid, where you are expected to complete a 10 hour task (CPU-time that is) within 2 days. Would shortening or perhaps extending the deadlines even further help alleviate or reduce the problem or problems? My best guess is that if there are tasks readily available for processing, I would eventually get these tasks the usual way. If many tasks have been returned but are still awaiting validation, I assume that there may be difficulties at receiving new tasks even if such are currently available. ID: 1302410 · |
|
rob smith Send message Joined: 7 Mar 03 Posts: 22202 Credit: 416,307,556 RAC: 380
|
I doubt that the number of tasks awaiting validation is an issue -there is plenty of disk space, and the server doing the validation is well up to it. Just now there are about 10,000,000 tasks "out in the field", and about 7,6000,000 tasks awaiting validation, and no new tasks being created as all the splitters are down for one reason or another. What is bemusing is the fact that the query rate is sitting at about 1200qps against the norm of 700-800qps and has been sat around there since the last outage... Bob Smith Member of Seti PIPPS (Pluto is a Planet Protest Society) Somewhere in the (un)known Universe? ID: 1302411 · |
|
Mad Fritz Send message Joined: 20 Jul 01 Posts: 87 Credit: 11,334,904 RAC: 0 
|
On a side note - suddenly I have around 2900 WUs with timed out errors... Anyone else experienced the same? ID: 1302418 · |
|
Grant (SSSF) Send message Joined: 19 Aug 99 Posts: 13736 Credit: 208,696,464 RAC: 304 
|
On a side note - suddenly I have around 2900 WUs with timed out errors... Not yet, but it will happen when VALRs get re-issued to the CUDA device instead of the CPU. Grant Darwin NT ID: 1302421 · |
|
Grant (SSSF) Send message Joined: 19 Aug 99 Posts: 13736 Credit: 208,696,464 RAC: 304
|
I've just had a note back from Eric: So does that mean it will take 10 minutes for it to timeout now? I figure if it's not going to respond within 5 minutes it's as good a time as any for it to timeout. Usually when it did respond when the timeouts were at their worst it was within a couple of minutes; when things are going well most responses are within 20 seconds or so. Do we know why the Scheduler is having such a hard time keeping up with the load- more RAM required, faster disk subsystem? New system? Grant Darwin NT ID: 1302424 · |
|
Mad Fritz Send message Joined: 20 Jul 01 Posts: 87 Credit: 11,334,904 RAC: 0
|
Not yet, but it will happen when VALRs get re-issued to the CUDA device instead of the CPU. Hmm, but they were all initially sent as CUDAs to me as I don't ask for CPU-work. ID: 1302425 · |
|
Grant (SSSF) Send message Joined: 19 Aug 99 Posts: 13736 Credit: 208,696,464 RAC: 304
|
Not yet, but it will happen when VALRs get re-issued to the CUDA device instead of the CPU. Might be worth posting a link to a few of them so those that know about these things can have a look. Grant Darwin NT ID: 1302426 · |
|
Tron Send message Joined: 16 Aug 09 Posts: 180 Credit: 2,250,468 RAC: 0
|
so much for trying to heat the greenhouse with seti power tonight..hope my plants don't freeze .. empty cache on the antique ibm watthog ID: 1302428 · |
|
Mad Fritz Send message Joined: 20 Jul 01 Posts: 87 Credit: 11,334,904 RAC: 0
|
Might be worth posting a link to a few of them so those that know about these things can have a look. http://setiathome.berkeley.edu/results.php?hostid=6167352&offset=0&show_names=0&state=6&appid= Pick one ;-) Hope it helps... ID: 1302432 · |
|
Richard Haselgrove Send message Joined: 4 Jul 99 Posts: 14650 Credit: 200,643,578 RAC: 874
|
So, how are we all doing this fine morning? I found these graphs instructive. I've made a fixed copy - I don't know whether the site is happy about live linking - so this is a snapshot of the position just after 12:00 UTC today (graph times are UTC+1). 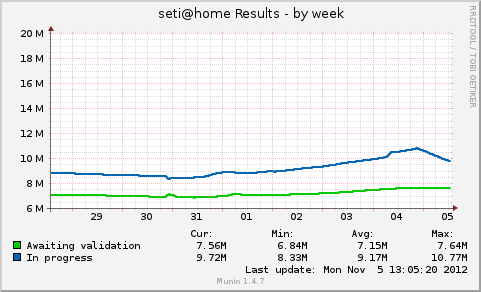 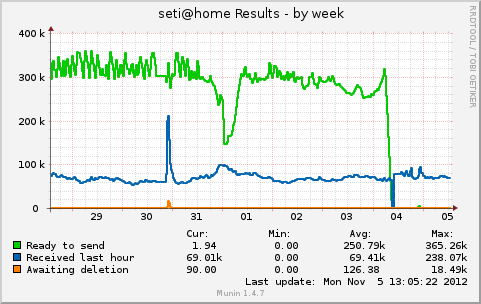 We've brought down 'Results in Progress' by over a million overnight, which can only be good for the health of the servers. We can also see clearly how we got into such a mess yesterday. Somewhere round about 5am UTC Sunday morning (late Saturday evening in Berkeley), some 300,000 tasks suddenly jumped from 'Ready to Send' to 'Results in Progress'. My guess is that they all became ghosts, but I've no idea why - late halloween party in the server closet, perhaps? I'd love to be a fly on the wall in this morning's staff meeting while they scratch their heads over that one. Anyway, back to the present. I'm finding that for hosts which have ghosts in the database (mainly fast hosts with large caches), I'm able to get them resent reasonably easily - provided I don't ask for too much at once. Large work requests are still hitting the timeout. But slower hosts or hosts with smaller caches - which haven't got any ghosts - aren't able to get any new work at all. Mark Sattler posted an interesting theory yesterday. He wondered whether asking Synergy to run the Scheduler, several MB splitters, and several AP splitters all at the same time might have been too much, and caused the inital slowdown we saw after maintenance last week. Sounds plausible to me. I've passed it on to the staff, and suggested that they might consider restarting the splitters on Lando - two of each - to provide a trickle of new work for smaller users who are currently getting nothing, while the power users amongst us work our way through the rest of the lost results. We'll see what they make of it. ID: 1302467 · |
|
juan BFP Send message Joined: 16 Mar 07 Posts: 9786 Credit: 572,710,851 RAC: 3,799 
|
Mark Sattler posted an interesting theory yesterday. He wondered whether asking Synergy to run the Scheduler, several MB splitters, and several AP splitters all at the same time might have been too much, and caused the inital slowdown we saw after maintenance last week. Sounds plausible to me. Richard Congrats, now you are in the right path, i was talking about that months ago. The problem always returns when the AP splitters starts. Maybe a clue, put less AP splitters to work for a while and see what happens, we all could be surprise on results. Another clue, during the last problem, i was able to DL (>150kpbps)/UL and report all with the help of a proxie with no problem (without a proxie DL(<1kpbs) and UL Ok report NO), thats interesting because thats point not for a bandwidth problem (the proxie uses the same bandwith). Talk about that with the others on the lab this could show another path to follow to. Have a good week. 
ID: 1302468 · |
|
fscheel Send message Joined: 13 Apr 12 Posts: 73 Credit: 11,135,641 RAC: 0
|
Success!!! I have now cleared my ~2000 lost tasks. Life is good. Frank ID: 1302476 · |
|
Fred E. Send message Joined: 22 Jul 99 Posts: 768 Credit: 24,140,697 RAC: 0
|
Success!!! I also cleared my 476 lost tasks overnight and earlier this AM. Tried Richard's suggestion on lowering the cache settings, but it didn't help in my case. Couldn't get scheduler for 5-6 hours after the splitters were disabled. I went back to my normal 5.75 days and eventually got them. There's another issue besides the timeouts. Why did Scheduler keep assigning work when we already had lost tasks? In the past, it has always filled those first. When mine came down, I was still getting the "no tasks available" (empty feeder) message at the end of each batch of 20, suggesting it was still trying to assign new tasks. Think that may need some looking - it was the potential for very large numbers that got me worried. As to the timeouts, I've also been in the "too much load on Synergy" camp, but I'm not so sure now after seeing how long it took me to connect after the splitters were disabled. I don't buy the bandwidth argument as a sole cause, but it certainly contributes, and some packet dumping router may have a role after the load gets heavy. Is there another possibility - database contention or something like that? I freely admit I don't know much about the issue, just that it sometimes caused problems with strange symptoms during my working years. Another Fred Support SETI@home when you search the Web with GoodSearch or shop online with GoodShop. 
ID: 1302482 · |

©2024 University of California
SETI@home and Astropulse are funded by grants from the National Science Foundation, NASA, and donations from SETI@home volunteers. AstroPulse is funded in part by the NSF through grant AST-0307956.