GBT ('guppi') .vlar tasks will be send to GPUs, what you think about this?
Message boards :
Number crunching :
GBT ('guppi') .vlar tasks will be send to GPUs, what you think about this?
Message board moderation
Previous · 1 · 2 · 3 · 4 · 5 . . . 10 · Next
| Author | Message |
|---|---|
 Zalster Zalster Send message Joined: 27 May 99 Posts: 5517 Credit: 528,817,460 RAC: 242 
|
What is the % of GPU usage for 1 VLAR/GPU? for 2 VLAR/GPU? 94-96% GPU Usage for 1 VLAR/GPU 98-99% GPU Usage for 2 VLAR/GPU but the system starts to slow down in responsiveness. Not a problem for a dedicated cruncher but some people might get annoyed with trying to use the computer. ID: 1785503 · |
|
tullio Send message Joined: 9 Apr 04 Posts: 8797 Credit: 2,930,782 RAC: 1 
|
I am running 2 Guppi Vlar on the CPU of my Windows 10 PC, which has a NVidia graphic board. I have installed an AMD board on my main Linux box, and it is running both SETI CPU tasks and SETI GPU tasks but so far no Vlar. Tullio ID: 1785575 · |
Richard Haselgrove  Send message Joined: 4 Jul 99 Posts: 14690 Credit: 200,643,578 RAC: 874 
|
I started the same test this morning, with a view to evaluating whether OpenCL (specifically MB8_win_x86_SSE3_OpenCL_NV_r3430_SoG.exe) is ready for prime time in the installer yet. It's running - deliberately - "as stock" on Beta host 23492. It's running 2-up, initially on the GTX 750 Ti (headless), but now on the GTX 970 which is also the display provider for my daily driver. The questions being (a) can I live with the display while it's working on guppi VLARs, and (b) what sort of efficiency (=speed) do I see at VLAR? So far, Murphy's server has dished out mostly Arecibo mid-ARs, and I've noticed occasional display lags - mostly when the screen attempts to display movement, rather than preventing typing as CUDA used to do at VLAR. Mid ARs are running through at about 14 minutes the pair, so I'll start the VLAR test in earnest in a bit over an hour from now. There's no reason not to do an installer refresh at some point, if only to strip out the v7 transition content after the last 168 WUs have cleared through. But I need to be sure that SoG is ready, and that BOINC handles the switch between CUDA and OpenCL plan classes transparently when people upgrade with tasks in flight. So, I'm not rushing into it. ID: 1785580 · |
|
Keith Myers Send message Joined: 29 Apr 01 Posts: 13164 Credit: 1,160,866,277 RAC: 1,873
|
Thanks for the installer update Richard. If I understand Mike's and Zalster's posts, it doesn't really matter at the moment if the R3430 OpenCL SoG app is run on Main because there aren't any VLAR's being sent to Nvidia cards still. Only at Beta are VLAR's being sent to Nvidia cards. Is that correct? I did look at the Beta host you linked and it looks like it has processed some Guppi VLARs. Seti@Home classic workunits:20,676 CPU time:74,226 hours   A proud member of the OFA (Old Farts Association) ID: 1785652 · |
|
Zalster Send message Joined: 27 May 99 Posts: 5517 Credit: 528,817,460 RAC: 242
|
VLAR are not sent to GPU on main. You can force it thou to move CPU VLAR to the GPU with Raistmer's app_info he posted. Otherwise you can run them on Beta where they are sent to the GPU I processed some here on Main yesterday but suspended them last night. I'll probably test some more tonight again. ID: 1785659 · |
|
Mike Send message Joined: 17 Feb 01 Posts: 34577 Credit: 79,922,639 RAC: 80 
|
I started the same test this morning, with a view to evaluating whether OpenCL (specifically MB8_win_x86_SSE3_OpenCL_NV_r3430_SoG.exe) is ready for prime time in the installer yet. It's running - deliberately - "as stock" on Beta host 23492. It's running 2-up, initially on the GTX 750 Ti (headless), but now on the GTX 970 which is also the display provider for my daily driver. The questions being (a) can I live with the display while it's working on guppi VLARs, and (b) what sort of efficiency (=speed) do I see at VLAR? So far, Murphy's server has dished out mostly Arecibo mid-ARs, and I've noticed occasional display lags - mostly when the screen attempts to display movement, rather than preventing typing as CUDA used to do at VLAR. So i better find some nice params for you NV guys soon. With each crime and every kindness we birth our future. ID: 1785664 · |
|
Richard Haselgrove Send message Joined: 4 Jul 99 Posts: 14690 Credit: 200,643,578 RAC: 874
|
I did look at the Beta host you linked and it looks like it has processed some Guppi VLARs. Yes, it's done a few already, and another four to report any moment now. Run times vary from 30 minutes to 39 minutes - in other words, starting from more than double mid-AR and upwards from there. Two points observed so far: some bad lags, including (rarely) complete screen freezes for several seconds. And <fraction_done> is still out of synch with <progress>: <fraction_done> is what is displayed in BOINC Manager these days, and it's getting ahead of itself. So the visible progress meter implies a shorter runtime, and slows down as it progresses - that's the opposite of what the old CUDA apps used to display with VLARs, starting slowly and speeding up as they progressed. More observations tomorrow. Yes, with no VLARs sent to NV at main at the moment, there's no rush for SoG in the installer - but we should get it polished ready for deployment if the need arises. Eric has said (recently - see Beta) that very little data is being recorded at Arecibo these days, so the day will come when it's Guppi or nothing. And with the current state of play, that's mostly VLAR - and no AP. Edit - forgot to mention CPU usage. This is how BoincView sees my daily driver. 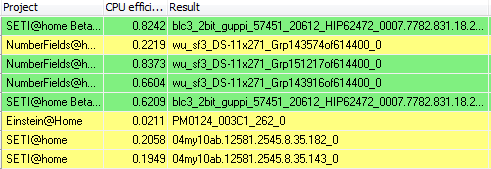 The middle column is 'CPU efficiency'. An ideal CPU application will show 1.0000 - full use of one core. An ideal GPU application will show 0.0000 - all work on GPU (not monitored by this app), no CPU used. The two Beta project tasks are SoG on GTX 970. The two SETI@Home tasks are cuda50 on GTX 750Ti. Einstein@home is an OpenCL app running on intel GPU - very well behaved. Numberfields is a CPU app, I think mostly integer. Two instances are just about nominal, but the third has triggered the yellow 'poor efficiency' warning, down below 25% of a core. On machines which don't also have 16 browser tabs open, I can run four of those plus four cuda tasks and not drop below 80%: 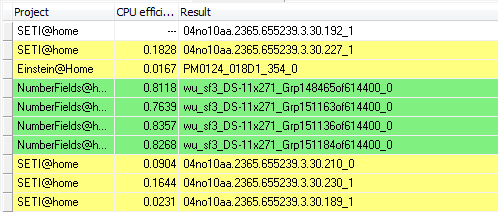 (well, maybe one core is a little lower) ID: 1785669 · |
|
Mike Send message Joined: 17 Feb 01 Posts: 34577 Credit: 79,922,639 RAC: 80
|
I did look at the Beta host you linked and it looks like it has processed some Guppi VLARs. ATM its no VLAR`s for GPU`s at all. I emailed Eric about it a while ago but he seems to be to busy atm. With each crime and every kindness we birth our future. ID: 1785671 · |
|
Richard Haselgrove Send message Joined: 4 Jul 99 Posts: 14690 Credit: 200,643,578 RAC: 874
|
ATM its no VLAR`s for GPU`s at all. Agreed, that's the policy for Main at the moment. That's why I'm running this test against Beta, where VLARs are allowed on NV Kepler GPUs and above. ID: 1785673 · |
|
Mike Send message Joined: 17 Feb 01 Posts: 34577 Credit: 79,922,639 RAC: 80
|
ATM its no VLAR`s for GPU`s at all. Yes, but my first response was that AMD`s should get VLAR`s. So i`m certain its still not easy to seperate both vendors. At least the plan was different. With each crime and every kindness we birth our future. ID: 1785676 · |
|
Richard Haselgrove Send message Joined: 4 Jul 99 Posts: 14690 Credit: 200,643,578 RAC: 874
|
As a general observation, if my car was mis-firing this badly, I'd pull over at the next garage and ask them to check it out before I completed my journey. The screen just "feels wrong" when running VLARs, in a way which would make me worry about my safety in a car. More significantly, I've just received my first error result - our old friend "finish file present too long". The timetable is: 11:03:17 (40088): called boinc_finish(0) So it looks as if there was an 18-second gap between calling finish and the app quitting, with BOINC pulling the plug at 13 seconds. That was Beta task 23790517, a normal Arecibo AR=0.429234. It was sharing the GPU with Beta VLAR task 23789897: I hope the VLAR lag didn't hold up the BOINC finish process. BOINC on this machine is the standard v7.6.22 (Windows 7/64) - I think that one has the shortest finish file tolerance of all. I'll check a few more timetables (delay between boinc_finish call and application exit), and see if I can find a pattern. ID: 1785804 · |
|
Mike Send message Joined: 17 Feb 01 Posts: 34577 Credit: 79,922,639 RAC: 80
|
As a general observation, if my car was mis-firing this badly, I'd pull over at the next garage and ask them to check it out before I completed my journey. The screen just "feels wrong" when running VLARs, in a way which would make me worry about my safety in a car. Without increasing single buffer size its no surprise to me. Maybe it would be a good idea to increase default params for NV builds. At least single buffer size and period_iterations_num. With each crime and every kindness we birth our future. ID: 1785810 · |
|
Richard Haselgrove Send message Joined: 4 Jul 99 Posts: 14690 Credit: 200,643,578 RAC: 874
|
Without increasing single buffer size its no surprise to me. If a single value can be found which is suitable for all cards [*], then absolutely, yes. If it has to be variable, then we need some sort of automatic tuning to pick the most appropriate values to suit the card the apps find themselves running on. [*] all cards the SoG app is appropriate for, that is. Do I remember it needs plenty of VRAM? We need an automatic 'minimum card' rule for stock deployment, and manual minimum card advice for the installer. ID: 1785815 · |
|
Mike Send message Joined: 17 Feb 01 Posts: 34577 Credit: 79,922,639 RAC: 80
|
Without increasing single buffer size its no surprise to me. That`s what i try to find out next week. Will run some tests on a 640 and 730. I have some values in mind, if the cards can cope with them we are another step in the right direction. Most cards now have at least 1GB VRAM. This would still be enough to run 2 instances. So this shouldn`t be a problem. I dont think one would run 2 instances on a 720. With each crime and every kindness we birth our future. ID: 1785821 · |
|
Raistmer Send message Joined: 16 Jun 01 Posts: 6325 Credit: 106,370,077 RAC: 121 
|
Without increasing single buffer size its no surprise to me. App check available GPU RAM. IF there is low - lower memory path used. If possible, app increase RAM usage for speedup. Also, I don't see how this connected with computation error from BOINC API. GPU computations were finished at that point, whatever buffer was. ID: 1785949 · |
|
Richard Haselgrove Send message Joined: 4 Jul 99 Posts: 14690 Credit: 200,643,578 RAC: 874
|
Without increasing single buffer size its no surprise to me. That part of Mike's reply was probably addressed to my opening remark: As a general observation, if my car was mis-firing this badly, I'd pull over at the next garage and ask them to check it out before I completed my journey. The screen just "feels wrong" when running VLARs, in a way which would make me worry about my safety in a car. The apps and screen are running on OpenCL: NVIDIA GPU 0: GeForce GTX 970 (driver version 350.12, device version OpenCL 1.2 CUDA, 4096MB, 3903MB available, 4087 GFLOPS peak) ID: 1785954 · |
|
Raistmer Send message Joined: 16 Jun 01 Posts: 6325 Credit: 106,370,077 RAC: 121
|
WU true angle range is : 0.429234 Used GPU device parameters are: Number of compute units: 13 Single buffer allocation size: 128MB Total device global memory: 4096MB max WG size: 1024 local mem type: Real FERMI path used: yes LotOfMem path: yes LowPerformanceGPU path: no period_iterations_num=50 I suppose VLAR ran with same defaults? Well, as I wrote few posts earlier: Instead of turning this thread in another point of rant I would propose for high-end GPU cards owners to more deeply explore quite a big parameter space of current OpenCL app and report back options that could speedup VLAR processing. And: (and very first attempt should be to add -sbs 512 to tuning line). It's still a way to go. ID: 1785957 · |
|
Richard Haselgrove Send message Joined: 4 Jul 99 Posts: 14690 Credit: 200,643,578 RAC: 874
|
It's still a way to go. Before the current app can be considered for release to run as stock. ID: 1785958 · |
|
Raistmer Send message Joined: 16 Jun 01 Posts: 6325 Credit: 106,370,077 RAC: 121
|
It's still a way to go. Before VLAR could be enabled on main, perhaps? Don't mix things up. ID: 1785960 · |
|
Richard Haselgrove Send message Joined: 4 Jul 99 Posts: 14690 Credit: 200,643,578 RAC: 874
|
It's still a way to go. Yes indeed, and that keeps us on topic for this thread. I don't think that GBT VLARs should be sent to (NVidia) GPUs until we have an application ready to handle them, and I don't think we have such an application - either CUDA or OpenCL - yet. ID: 1785962 · |

©2025 University of California
SETI@home and Astropulse are funded by grants from the National Science Foundation, NASA, and donations from SETI@home volunteers. AstroPulse is funded in part by the NSF through grant AST-0307956.