stuck on high priority
Message boards :
Number crunching :
stuck on high priority
Message board moderation
| Author | Message |
|---|---|
|
PhonAcq Send message Joined: 14 Apr 01 Posts: 1656 Credit: 30,658,217 RAC: 1 
|
One of my hosts seems not to be able to unstick itself. It has been running on high priority for about a week or so. What's more and while in this mode, it has been downloading new work, until I turned it off. It has been booted a couple of times, but this didn't help. It is running boinc 6.10.60, but I don't remember when I upgraded. Anything I can do? I'm not sure that I mind, as long as I can get new work. I think I'll let it run out of wu's, enable downloads, and see what happens. But I haven't seen this behaviour before. ID: 1098225 · |
 SciManStev SciManStev   Send message Joined: 20 Jun 99 Posts: 6653 Credit: 121,090,076 RAC: 0
|
Check to see if your GPU downclocked. If that isn't the cause, set for No New Tasks for a couple of days, and see if it clears. The same thing just happened to me, and these were the causes. Steve Edit: Also use Fred's rescheduler. It prevents -177 errors, and may help to aleviate the problem, even if it does not have to move VLAR's. Rescheduler Warning, addicted to SETI crunching! Crunching as a member of GPU Users Group. GPUUG Website ID: 1098226 · |
|
BilBg Send message Joined: 27 May 07 Posts: 3720 Credit: 9,385,827 RAC: 0 
|
Your CPU tasks are computed in 3-5 hours. What estimates do you see for the unstarted tasks? What is the "Duration correction factor" for SETI@home? (BOINC Manager -> Projects tab -> select SETI@home -> press [Properties] - Look at the bottom) Computer 5828858 is the only with BOINC version 6.10.60: http://setiathome.berkeley.edu/show_host_detail.php?hostid=5828858 From the bottom of page copy this info: % of time BOINC is running 97.0718 % While BOINC running, % of time host has an Internet connection 99.994 % While BOINC running, % of time work is allowed 99.3354 % Task duration correction factor 1.225475 ( I think it has only SETI@home and not Einstein@Home tasks (?) as it is not listed here: http://einstein.phys.uwm.edu/hosts_user.php?userid=102722 ) @SciManStev - PhonAcq has no (recognized) GPUs on any of his Computers: http://setiathome.berkeley.edu/hosts_user.php?userid=18847 Â   - ALF - "Find out what you don't do well ..... then don't do it!" :) - ALF - "Find out what you don't do well ..... then don't do it!" :)Â ID: 1098376 · |
|
PhonAcq Send message Joined: 14 Apr 01 Posts: 1656 Credit: 30,658,217 RAC: 1
|
at the bottom of properties it reads: * sch priority 0.00 * fetch priority 0.0 * work fetch deferred for --- * work fetch interval --- * DCF 1.0125 I don't see anything about unstarted task estimates Yes, no einstein (Yet) ID: 1098393 · |
|
kittyman Send message Joined: 9 Jul 00 Posts: 51469 Credit: 1,018,363,574 RAC: 1,004
|
If the rig is still crunching, what is the problem? Other than not building cache at the moment, it should be fine. Boinc will sort things sooner or later. It always does for me. I kinda quit manually playing with it long ago. Too hard to monitor 8 rigs with large caches. And Boinc has not let me down yet. Meow. "Freedom is just Chaos, with better lighting." Alan Dean Foster 
ID: 1098394 · |
Richard Haselgrove  Send message Joined: 4 Jul 99 Posts: 14654 Credit: 200,643,578 RAC: 874 
|
I don't see anything about unstarted task estimates That looks like the Projects tab, properties for SETI@Home. Bill meant the Tasks tab, normal display, with all tasks shown (not filtered to active tasks only by the top-left button). Any task with status 'Ready to start' should show a 'Remaining' time estimate as well. ID: 1098395 · |
|
PhonAcq Send message Joined: 14 Apr 01 Posts: 1656 Credit: 30,658,217 RAC: 1
|
I have the same opinion regarding boinc, but I like to wu fiddle as much as some like to facebook, etc. Yet, it seems that boinc's logic is flawed, especially since I'm getting things slated for June now. So if the program isn't perfect, I might be helping to point oddities out. The time estimates are all 3-4 hours, except for about three 24 hour ap's. That is about 1000 h of estimated compute time, or 44 days. The host has 4 threads, making this about 11 days, which matches my requested 10 day cache. The earliest deadline is 5/10/11, which is more than 20 days away; my latest is 6/5. I've turned off new task requests to reduce the cache size for a while and hope(?) that the HP mode will revert to normal. thx. ID: 1098401 · |
|
kittyman Send message Joined: 9 Jul 00 Posts: 51469 Credit: 1,018,363,574 RAC: 1,004
|
I have the same opinion regarding boinc, but I like to wu fiddle as much as some like to facebook, etc. LOL...fiddle away, my friend. Micro managing Boinc can be quite a bit of handiwork indeed. "Freedom is just Chaos, with better lighting." Alan Dean Foster
ID: 1098407 · |
John McLeod VII  Send message Joined: 15 Jul 99 Posts: 24806 Credit: 790,712 RAC: 0
|
I have the same opinion regarding boinc, but I like to wu fiddle as much as some like to facebook, etc. There are two different settings that determine the queue size for BOINC. The first is the "Connect every X days" setting. This does two things: First, it attempts to keep enough work on hand so that BOINC can be disconnected from the internet for that amount of time. Second, it attempts to finish every task at least that amount of time before the report deadline so that it can be reported by one connect interval prior to the report deadline as you might be disconnected at the moment the report deadline comes around. The second setting for queue size is "maintain enough work for X extra days". This attempts to maintain at least that amount of work in addition to the off line time declared in the previously described setting. Hints: You should set Connect Every X days to approximately match predicted reality. High priority mode is not a problem.   BOINC WIKI ID: 1098625 · |
|
PhonAcq Send message Joined: 14 Apr 01 Posts: 1656 Credit: 30,658,217 RAC: 1
|
My cache setting are for continuous connect and 10 extra days. This works fine for me. However, the host I'm referring to below is still in HP mode, even though it has just two days worth of wu's remaining with an earliest due date of 5/26. So I think that boinc has a programmng problem and can't get out of HP mode by itself. I will leave things alone and hope to flush the cache and then start over. (I've prevented additional downloads so my cache is clearing) May this Farce be with You ID: 1099647 · |
|
HAL9000 Send message Joined: 11 Sep 99 Posts: 6534 Credit: 196,805,888 RAC: 57
|
My cache setting are for continuous connect and 10 extra days. This works fine for me. However, the host I'm referring to below is still in HP mode, even though it has just two days worth of wu's remaining with an earliest due date of 5/26. So I think that boinc has a programmng problem and can't get out of HP mode by itself. I will leave things alone and hope to flush the cache and then start over. (I've prevented additional downloads so my cache is clearing) The settings for "Switch between tasks every nn minutes" also plays a role into the scheduler function. I set mine for 6 days, 8640 minutes. So I see HP mode kick in when you might otherwise thing it shouldn't. If you are using a high value & think that might be what is causing HP mode try setting it to a lower value. SETI@home classic workunits: 93,865 CPU time: 863,447 hours  Join the [url=http://tinyurl.com/8y46zvu]BP6/VP6 User Group[ Join the [url=http://tinyurl.com/8y46zvu]BP6/VP6 User Group[
ID: 1099771 · |
|
PhonAcq Send message Joined: 14 Apr 01 Posts: 1656 Credit: 30,658,217 RAC: 1
|
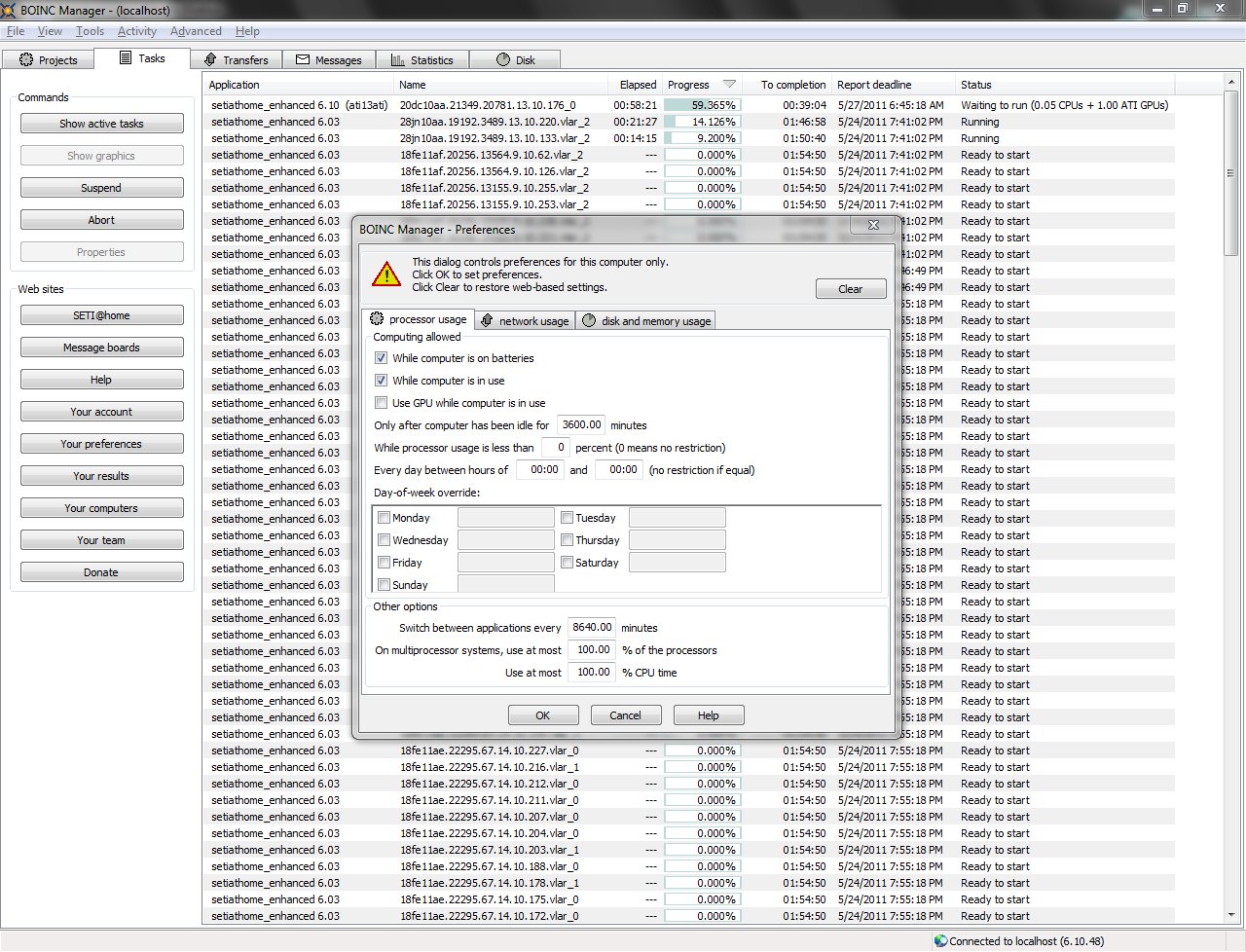
Interesting, in the boinc preferences window and network usage tab, there is a line (second column second row) that merely says "every" afterwhich there is an entry window having a value of 0 days. On the processor usage tab, there is a switch applications entry which I want set to a very high number so that once a wu is started boinc doesn't switch to another application, leaving the initiated wu to fester in the waiting to run queue. But this parameter probably doesn't apply to the problem being described here (perpetual HP mode) because I have wu's for only one project available for running right now. That is, I have Einstein set at 0 resource sharing so that einstein will download only if seti goes belly up for about 10 days and I run out of wu's to process. May this Farce be with You ID: 1099958 · |
|
HAL9000 Send message Joined: 11 Sep 99 Posts: 6534 Credit: 196,805,888 RAC: 57
|
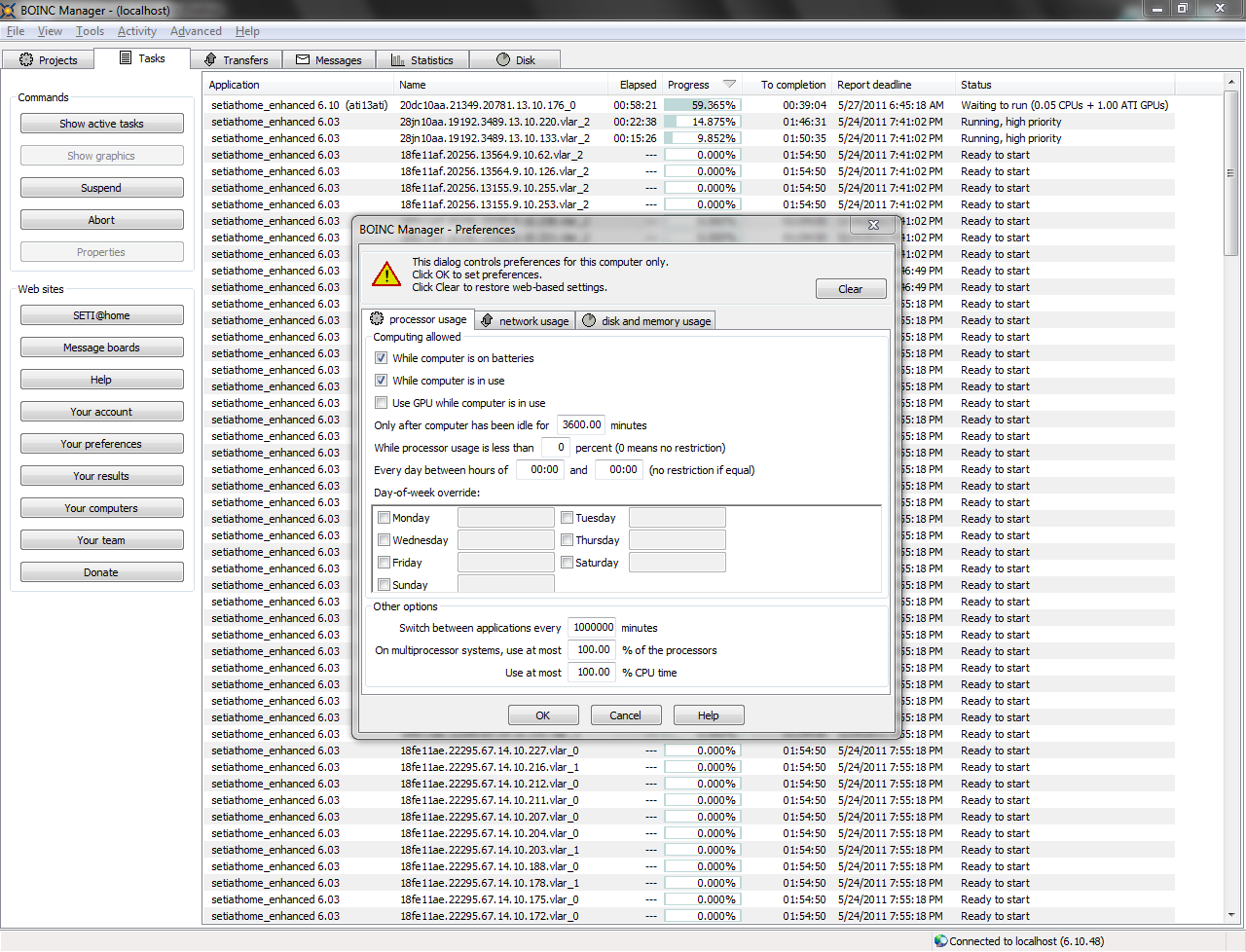
Interesting, in the boinc preferences window and network usage tab, there is a line (second column second row) that merely says "every" afterwhich there is an entry window having a value of 0 days. The application switch time does in fact have an effect on the scheduler. Here is an example. With my normal value of 8640m the scheduler is ok. With a really high value of 100000000m everything goes into HP mode & will stay there. If you enable the debugging flags in this case you will see the scheduler thinks it can't finish in time and shifts into HP mode. Which is fine if you want everything to be done by due date. That could be unrelated to your issue, but that is why I suggested setting it to a low value to see if that takes thing out of HP mode. Then you would have your answer if it did. If not then we would have to look elsewhere. SETI@home classic workunits: 93,865 CPU time: 863,447 hours Join the [url=http://tinyurl.com/8y46zvu]BP6/VP6 User Group[
ID: 1099964 · |
|
PhonAcq Send message Joined: 14 Apr 01 Posts: 1656 Credit: 30,658,217 RAC: 1
|
Interesting; I'll check your suggestions out some more later. But I did look at two hosts with the same 9999m setting. One (6.10.60) is HP and the other (6.10.58) is not. Both are downloading happily when needed. The one in HP mode has just cleared its cache. So I watched and the first wu's downloaded (into an empty queue) began in HP mode. It merely looks like boinc got stuck in this mode (through reboots and restarts) and won't budge. So I still think boinc is buggy. May this Farce be with You ID: 1100273 · |
|
HAL9000 Send message Joined: 11 Sep 99 Posts: 6534 Credit: 196,805,888 RAC: 57
|
Interesting; I'll check your suggestions out some more later. But I did look at two hosts with the same 9999m setting. One (6.10.60) is HP and the other (6.10.58) is not. Both are downloading happily when needed. With 9999m that is only about 7 days. So as long as the new work was due more then 7 days out it probably should not have gone into HP mode. The logging flag <cpu_sched_debug>1</cpu_sched_debug> will let you see what is going on a bit. Since you said earlier that the GUI isn't displayed correctly, in that you only see the work "every" in the network section. That would point to at least one corrupt file on your system. SETI@home classic workunits: 93,865 CPU time: 863,447 hours Join the [url=http://tinyurl.com/8y46zvu]BP6/VP6 User Group[
ID: 1100485 · |
|
PhonAcq Send message Joined: 14 Apr 01 Posts: 1656 Credit: 30,658,217 RAC: 1
|
Is there another debug switch to use? I've enabled the cpu_sched one and, although it adds some information about why a wu is started (mostly resume and intial), it doesn't shed light for me to understand this constant HP mode. ID: 1104298 · |
|
HAL9000 Send message Joined: 11 Sep 99 Posts: 6534 Credit: 196,805,888 RAC: 57
|
Is there another debug switch to use? I've enabled the cpu_sched one and, although it adds some information about why a wu is started (mostly resume and intial), it doesn't shed light for me to understand this constant HP mode. As i mentioned it should be cpu_sched_debug. As cpu_sched is a different debug flag. With the cpu_sched_debug flag on you should see a mess such as the following: 5/8/2011 12:23:29 AM [cpu_sched_debug] Request CPU reschedule: Core client configuration I set my connect every to 30 days to force it into HP mode. However whenever this process runs you should get this output. It lists all the tasks that it thinks will miss their deadline. In my case 39, but your output might be much longer. I know it is silly, but you did check to make sure the date on the PC is correct right? SETI@home classic workunits: 93,865 CPU time: 863,447 hours Join the [url=http://tinyurl.com/8y46zvu]BP6/VP6 User Group[
ID: 1104323 · |
|
BilBg Send message Joined: 27 May 07 Posts: 3720 Credit: 9,385,827 RAC: 0
|
Interesting; I'll check your suggestions out some more later. But I did look at two hosts with the same 9999m setting. One (6.10.60) is HP and the other (6.10.58) is not. Both are downloading happily when needed. Why do you need such a big setting?: "Switch between applications every 9999 minutes" (= ~7 days) (there is no task on SETI@home or Einstein@Home that will run for so long on your machines) Change this to e.g. 600 (= 10 hours) or 1440 minutes (= 1 day) and very probably the "High priority" mode will disappear. Â - ALF - "Find out what you don't do well ..... then don't do it!" :)Â ID: 1104368 · |
|
PhonAcq Send message Joined: 14 Apr 01 Posts: 1656 Credit: 30,658,217 RAC: 1
|
@HAL900: correct date; running boinc 6.10.20; I abbreviated the flag in my email-- the correct one is in cc_config; you get much more detailed info than I get. (It is cc_config.xml, correct?) I'll check again, reboot, and hope for the best. @BilBg: I want a high switch time period because I want to force boinc to finish what it starts before switching to another task. I run seti and einstein, with a resource request of 999 to 0. I only have einstein running in case seti poops out (and poops out for an extended time so that my seti cache clears). These setting work well on my other hosts, it seems. Boinc or me have problems with only one host. thx. ID: 1104381 · |
|
BilBg Send message Joined: 27 May 07 Posts: 3720 Credit: 9,385,827 RAC: 0
|
@BilBg: I want a high switch time period because I want to force BOINC to finish what it starts before switching to another task. Yes, but no task will run for 7 days, you can lower that value to 1440 minutes (= 1 day). These setting work well on my other hosts Combined with what "Connect every" & "Additional days"? running BOINC 6.10.20 I don't see such older version on your hosts: http://setiathome.berkeley.edu/hosts_user.php?userid=18847 (I think you again "abbreviated" something ;) - make Ctrl-C, Ctrl-V your friends) I'll check again, reboot, and hope for the best. Reboot will not change anything - this behavior is caused by settings which will remain the same across the reboot. Â - ALF - "Find out what you don't do well ..... then don't do it!" :)Â ID: 1104391 · |
{kind=link}
{kind=link}

©2024 University of California
SETI@home and Astropulse are funded by grants from the National Science Foundation, NASA, and donations from SETI@home volunteers. AstroPulse is funded in part by the NSF through grant AST-0307956.