The Server Issues / Outages Thread - Panic Mode On! (118)
Message boards :
Number crunching :
The Server Issues / Outages Thread - Panic Mode On! (118)
Message board moderation
Previous · 1 . . . 90 · 91 · 92 · 93 · 94 · Next
| Author | Message |
|---|---|
|
Ville Saari Send message Joined: 30 Nov 00 Posts: 1158 Credit: 49,177,052 RAC: 82,530 
|
Reduced server side limits would have no effect on those super slow hosts but would hurt fast gpus disproportionally. When the limit was 100 per GPU, my cache was limited to less than 2 hours and I have just a cheap mid range graphics card. There is something fishy in the graph. I have monitored the validating time of my tasks for a long time and 95% of all my tasks have been validated within 5 days of me originally downloading the task. 98% in 13 days. So a two week deadline would force at most 2% of the tasks to be resent and in practice a lot less because people would adjust their caches. I guess the graph shows a snapshot of tasks in validation queue. Such a snapshot would show disproportionally high percentage of long waiting tasks as they are the ones that get 'stuck' in the queue while the quickly validated ones don't wait in there to be seen. This is what the real validation time distribution looks like in graph form (x axis is days, y axis is percentage of tasks not validated yet): 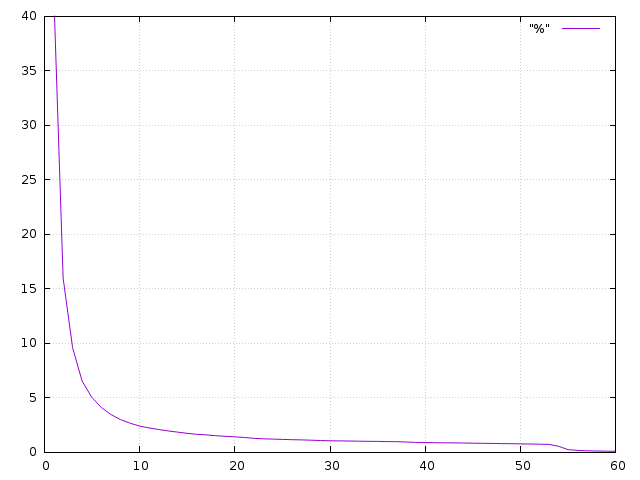 The sudden drop at 55 days is the result of the tasks expiring, getting resent and then getting validated fast in a scaled down version of similar curve. ID: 2033748 · |
rob smith  Send message Joined: 7 Mar 03 Posts: 22752 Credit: 416,307,556 RAC: 380 
|
Have you ever worked out how much it would "hurt" the super-fast hosts? It's quite simple to do: How many tasks per hour does ONE GPU get through. Now work out the legnth of time a 150 task cache lasts for. Now work out what percentage of a week is that? Now let's see the "hurt" for a 4 hour and an 8-hour period where no tasks are sent to that GPU, remember that the first x minutes of that time is covered by the GPU's cache. (I've not done the sums, but I think you will be amazed by how small the figure is - less than 10% (for the 8-hour period) is my first guess, but prove me wrong) Bob Smith Member of Seti PIPPS (Pluto is a Planet Protest Society) Somewhere in the (un)known Universe? ID: 2033750 · |
|
Ville Saari Send message Joined: 30 Nov 00 Posts: 1158 Credit: 49,177,052 RAC: 82,530
|
Have you ever worked out how much it would "hurt" the super-fast hosts?You would be amazed how high the figure is. Tuesday downtimes are not the only periods when the caches deplete. In the last couple of months we have had lot of periods of throttled work generation where my host spends several hours getting noting until it gets lucky and gets some work. And then again long time of nothing. 150 tasks last about 3 hours with my GPU but it's a slow one. High end GPUs will probably crunch those 150 tasks in less than an hour. ID: 2033753 · |
|
Lazydude Send message Joined: 17 Jan 01 Posts: 45 Credit: 96,158,001 RAC: 136 
|
please remember 10+10 days are per PROJECT so my concluson deadlines 20 days + 10 days (for the gremlings) i just tested with 10+10 and got 12,5 days of work in one requst from Einstein. and 150+150 wus from seti 1000units from ( 3days) from Asteriods before i set nnt So in a couple of days i suspect i have a lot of task in high priorty mode ID: 2033754 · |
Richard Haselgrove  Send message Joined: 4 Jul 99 Posts: 14690 Credit: 200,643,578 RAC: 874
|
Now there's a challenge!Took a sample from my host 7118033 - single GTX 1050 Ti, cache 0.8 days, turnround 0.81 days, 82 tasks in progress, 120 pending. 100 of those pending were less than 4 weeks old. Here are the other 20. Workunit Deadline Wingmate Turnround Platform CPU 3843402125 10-Mar-20 8011299 1.77 days Ubuntu i7 Block of ghosts on that day? Later work returned normally. 3838811280 06-Mar-20 6834070 0.06 days Darwin i5 No contact since that allocation. Stopped crunching? 3835694801 04-Mar-20 8882763 0.04 days Win 10 Ryzen 5 No contact since that allocation. Stopped crunching? 3833579833 06-Mar-20 7862206) 17.02 days Darwin i7 Only contacts once a week. Nothing since 29 Jan 3833579839 03-Mar-20 7862206) 3831370022 02-Mar-20 8504851) n/a Win 7 Turion Never re-contacted 3831369958 02-Mar-20 8504851) 3830290903 02-Mar-20 8623725) 0.48 days Win 10 i7 No contact since that allocation. Stopped crunching? 3830290941 27-Feb-20 8623725) 3827620430 29-Feb-20 8879055 6.2 days Win 10 i5 Last contact 12 Jan. Stopped crunching? 3826924227 25-Mar-20 8756342 1.21 days Android ? Active, but many gaps in record. 3821828603 02-Mar-20 8871849 5.29 days Win 10 i5 Last contact 5 Jan. Stopped crunching? 3821313504 26-Feb-20 8664947) 0.96 days Win 10 Ryzen Last contact 10 Feb. Stopped crunching? 3821313516 26-Feb-20 8664947) 3821313522 26-Feb-20 8664947) 3820902138 25-Feb-20 8665965 2.66 days Win 7 i7 Last contact 6 Jan. Stopped crunching? 3819012955 15-Mar-20 8842969 2.75 days Win 10 i7 Last contact 11 Jan. Stopped crunching? 3816054138 Timed out/resent. Should return today. 3808676716 14-Mar-20 8873865 53.85 days Win 10 i5 Host still active, but not crunching. Hit his own bad wingmate! 3783208510 Timed out/resent. Should returnApart from one Android and one Turion, all of those are perfectly good crunchers - should have no problem with deadlines. No sign of an excessive cache amongst them. The biggest problem is people who sign up, then leave without cleaning up behind them. I'd say that supports a shorter (set of) deadlines - remember deadlines are variable. ID: 2033755 · |
 Tom M Tom M Send message Joined: 28 Nov 02 Posts: 5126 Credit: 276,046,078 RAC: 462 |
And for extremely slow rarely on systems, 1 month is plenty of time for them to return a WU. It's actually plenty of time for them to return many WUs. +42 A proud member of the OFA (Old Farts Association). ID: 2033756 · |
|
juan BFP Send message Joined: 16 Mar 07 Posts: 9786 Credit: 572,710,851 RAC: 3,799 
|
The biggest problem is people who sign up, then leave without cleaning up behind them. I'd say that supports a shorter (set of) deadlines - remember deadlines are variable. Richard hit the target. Even the super slow host can crunch it`s WU in less than a month, The ones who not do that are the ones with problems. Ghosts, stop crunching, hardware failure, etc. I made a search (very painful due the slow response from the servers) on my Validation pending (6380) and find some very close to Richard findings, about 15% of it are WU received and crunched on the begging of January and still waiting for the wingmens. By the ones i was able to follow (takes a long time to show a single page) i could say with high confidence about 1/2 of them will not return before the deadline. I f we extrapolate that 7.5% to the DB size we are talking on a huge number. Then why not set the deadline to up to 1 month? That will give the project admins an extra time to think on a more permanent solution. BTW I still believe the only practical solution, with the available server hardware & software is to limit the WU cache to something like 1 day of the host actual returning valid tasks number, for all the hosts, fastest or slower. And even that will give only some extra time. The real permanent solution is a complete update of the project, better hardware could help obviously, but what is the bottleneck is the way the project works, still in the same way of >20 years ago. When we take more than a day to crunch a single WU and dial up connections are the only available. I trying to find one app from >20 years ago who is still running in the same way and i was unable to find, maybe someone knows and could share. 
ID: 2033761 · |
|
rob smith Send message Joined: 7 Mar 03 Posts: 22752 Credit: 416,307,556 RAC: 380
|
I trying to find one app from >20 years ago who is still running in the same way and i was unable to find, maybe someone knows and could share. I assume you mean "host" not "app", as the 20 year old application was the Classic (pre-BOINC) and those results have been collated a long time ago - probably just after BOINC burst on the block in 2003. Grumpy Swede was, and possibly still is, using a Windows XP system, so that might be one of the oldest around. Bob Smith Member of Seti PIPPS (Pluto is a Planet Protest Society) Somewhere in the (un)known Universe? ID: 2033765 · |
|
juan BFP Send message Joined: 16 Mar 07 Posts: 9786 Credit: 572,710,851 RAC: 3,799
|
I trying to find one app from >20 years ago who is still running in the same way and i was unable to find, maybe someone knows and could share. Yes my mistake, you know my English is bad. But you get the point, why insists to keep the >2 moths deadlines in this days? While what we urgent needs is to squeeze the DB size.
ID: 2033767 · |
|
Richard Haselgrove Send message Joined: 4 Jul 99 Posts: 14690 Credit: 200,643,578 RAC: 874
|
We were reminded recently of Estimates and Deadlines revisited from 2008 (just before GPUs were introduced). That link drops you in on the final outcome, but here's a summary of Joe's table of deadlines: Angle Deadline (days from issue) 0.001 23.25 0.05 23.25 (VLAR) 0.0501 27.16 0.22548 16.85 0.22549 32.23 0.295 27.76 0.385 24.38 0.41 23.70 (common from Arecibo) 1.12744 7.00 (VHAR) 10 7.00Since then, we've had two big increases in crunching time, due to increases in search sensitivity, and each has been accompanied by an extension of deadlines. So the table now looks something like: Angle Deadline 0.05 52.75 (VLAR) 0.425 53.39 (nearest from Arecibo) 1.12744 20.46 (VHAR)So, deadlines overall have more than doubled since 2008, without any allowance for the faster average computer available now. I think we could safely halve the current figures, as the simplest adjustment. ID: 2033768 · |
|
juan BFP Send message Joined: 16 Mar 07 Posts: 9786 Credit: 572,710,851 RAC: 3,799
|
So, deadlines overall have more than doubled since 2008, without any allowance for the faster average computer available now. I think we could safely halve the current figures, as the simplest adjustment. Another reason to support the idea. Something must be done. Anyway, any changes on the deadlines will take weeks to make effect. Plenty of time to make any fine adjust if necessary.
ID: 2033770 · |
|
Ville Saari Send message Joined: 30 Nov 00 Posts: 1158 Credit: 49,177,052 RAC: 82,530
|
Increasing deadlines when workunits become slower to crunch doesn't really make much sense. No one needs long deadline because his hosts needs so long to crunch a single task. The need for long deadlines arises from things that have nothing to do with single task duration. AstroPulse tasks have 25 day deadline despite being many times slower to crunch than MultiBeam. Why not drop the deadline of all tasks to this same 25 days? My validation time statistics say that 61% of the tasks that take longer than 25 days will eventually expire. And the remaining 39% is only 0.45% of all tasks. So currently less than one task in 200 would be returned in the time window that would be cut out by deadline reduction to 25 days. And I believe most of that 0.45% won't really hit the new deadline because users who currently run their computers in a way that makes tasks take that long will adapt to the new deadline and will either reduce their cache sizes or increase the time they keep their computers powered on and crunching setiathome. ID: 2033775 · |
|
rob smith Send message Joined: 7 Mar 03 Posts: 22752 Credit: 416,307,556 RAC: 380
|
How wrong can you be: Let's take an extreme example: A task takes 1 hour to run. The deadline is 1.5 hours Now the task complexity is changed and it takes 2 hours to run, but the deadline remains at 1.5 hours. Therefore all tasks fail to complete within their deadline. As I said that is a deliberately extreme example. You do however raise a reasonable question - why indeed to AstroPulse tasks have a deadline of 25 day, when the much faster to computer (but much more common) MultiBeam tasks have a deadline of over 50 days? I suspect the logic behind that is lost in the mists of time (or Richard will pop up with the answer). Bob Smith Member of Seti PIPPS (Pluto is a Planet Protest Society) Somewhere in the (un)known Universe? ID: 2033781 · |
|
Stephen "Heretic" Send message Joined: 20 Sep 12 Posts: 5557 Credit: 192,787,363 RAC: 628 
|
. . Except that the majority of that 'delay' on the slow hosts is not due to their low productivity so much as their oversized caches. The reason they sit on tasks for 50 days is not because it takes them that long to process a task, but because WUs sit in their 'in progress' status for weeks on end before they get around to processing them.In theory, if a WU is processed it should be done within 20 days (10+10 for cache settings).* . . You have omitted the factor that Rob seems very concerned about, part time crunchers. A 10+10 cache is based on run times and 24/7 capablility, but a machine (and there are many of them Rob believes) that only runs a couple of hours a day would take many, many times that long to get through the work allocated. If comparing machines to avoid same hardware false validations then run times are the criterion, but when calculating work allocation it should be turn around time that is used. If a machine returns only 1 task per week because it is sub-normally slow and very much part time, then it should have a limit of maybe 5 tasks; compared to a machine that completes 12 tasks every 5 mins and has a return time of about 1 hour (based on a 150 WU cache). Stephen . . ID: 2033782 · |
|
rob smith Send message Joined: 7 Mar 03 Posts: 22752 Credit: 416,307,556 RAC: 380
|
Yes, I am concerned about the part-time crunchers, as they numerically are the vast majority of crunchers, and there is a very small, very vocal number of high rollers. And remember that SETI has worked very hard to ensure a very wide user base, and if that means having sensible deadlines then we have to live with it, and not cheat by bunkering, re-scheduling or GPU-spoofing, all of which deprive the MAJORITY of user of tasks. I get at least one PM a week from someone who is leaving SETI@Home because of the attitude of some of the high rollers and greedy. Bob Smith Member of Seti PIPPS (Pluto is a Planet Protest Society) Somewhere in the (un)known Universe? ID: 2033785 · |
|
Stephen "Heretic" Send message Joined: 20 Sep 12 Posts: 5557 Credit: 192,787,363 RAC: 628
|
Have you ever worked out how much it would "hurt" the super-fast hosts? . . OK that's easy enough . . Since you stipulated 'super-fast' lets look at a machine such as Keith and Ian use. . . Each task takes less than a minute, closer to 30 secs, so on a per device basis the 150 current limit would last about 1.25 hours but let's say 2 hours. So a 4 hour absence of new work would see them idle for at least 2 hours or 100% detriment, an 8 hours lack of work would see them idle for over 6 hours or at least a 300% detriment. Slightly more than your estimation of less than 10%. . . Now if you drop back to a more pedestrian machine like the one I am using with a GTX1050ti which only return 16 or so tasks per hour on average then even the 8 hour drought would be kind of survivable ie 0% detriment, on the premise that sufficient work is immediately available at the end of the 8 hours. But there are hundreds or thousands of machines between those two levels, take a look at the top host listing and try to find the ones with RACs under 25,000. Stephen ID: 2033788 · |
|
rob smith Send message Joined: 7 Mar 03 Posts: 22752 Credit: 416,307,556 RAC: 380
|
Reduced server side limits would have no effect on those super slow hosts but would hurt fast gpus disproportionally. When the limit was 100 per GPU, my cache was limited to less than 2 hours and I have just a cheap mid range graphics card. I'm not sure HOW you generated your curve, but here is a plot of percent tasks pending vs days pending from data earlier today: 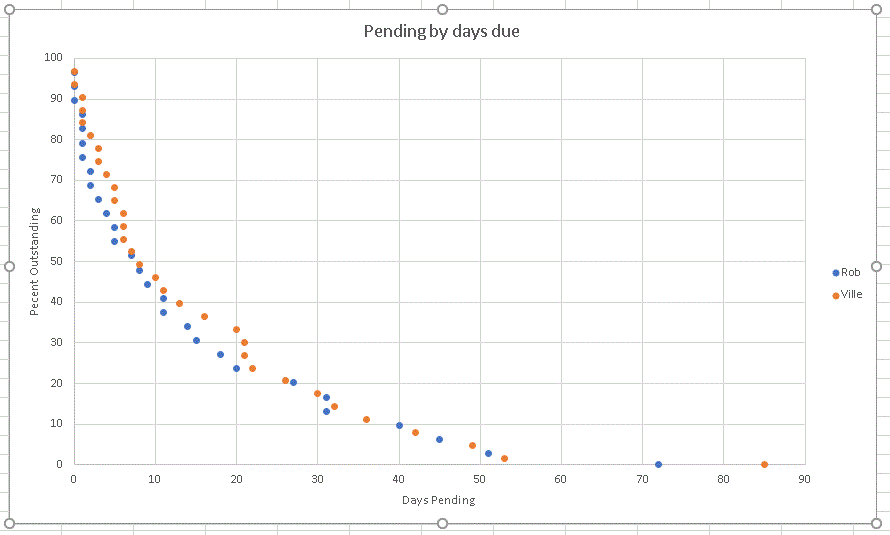 The key is not looking at tasks that have validated, but at those that are still pending - these are the ones that need to be moved into validation, and thus out of the day-to-day database, but into the main database - remember pending tasks have to be "monitored" by the servers to make sure they don't become over-due tasks (which then need to be re-sent), or "dead" tasks (those which have reached their limit on re-sends). As you can see there is a marked difference in the shape of the curve, and the position of the curve, some of this may be down to sampling techniques (I sampled every 20th task), but that goes nowhere near explaining the vast difference between the two sets of curves. In my plot you can see where we each had a "bump" in the validation rates before the 55 day cut-off was reached - something I would expect, but is totally lacking in Ville Saari's plot. Bob Smith Member of Seti PIPPS (Pluto is a Planet Protest Society) Somewhere in the (un)known Universe? ID: 2033790 · |
|
Stephen "Heretic" Send message Joined: 20 Sep 12 Posts: 5557 Credit: 192,787,363 RAC: 628
|
BTW I still believe the only practical solution, with the available server hardware & software is to limit the WU cache to something like 1 day of the host actual returning valid tasks number, for all the hosts, fastest or slower. And even that will give only some extra time. . . Hi Juan, . . You well know my ideal is the one day (max) cache. But we do need to maintain 'good faith' with the more timid volunteers who only log in once per week. Still not sure there are very many (if any) people using dial ups. But some may be using metered services. Stephen :) ID: 2033793 · |
|
rob smith Send message Joined: 7 Mar 03 Posts: 22752 Credit: 416,307,556 RAC: 380
|
Thanks Stephen. You have provided some sensible figures, and a rationale behind them - I just did the figures on one of Keith's computers and came up with about 45s/per task. Your conclusions are somewhat dubious - as the "hit" has to be taken in terms of tasks per week (168 hours), thus a loss of 1 hour is ~0.6%, so a loss of two hours is ~1.2%, and 6 hours is ~3.6%. Which I think you will agree is much less than my first guess, based on no evidence apart from thinking "they will be double the speed of my Windows based host", of ~10%. If we think in terms of RAC, 4% may well be less than the gain/hit from having a great pile of APs vs a great pile of poor-payers (whatever they may be this week). Bob Smith Member of Seti PIPPS (Pluto is a Planet Protest Society) Somewhere in the (un)known Universe? ID: 2033794 · |
|
Stephen "Heretic" Send message Joined: 20 Sep 12 Posts: 5557 Credit: 192,787,363 RAC: 628
|
Yes, I am concerned about the part-time crunchers, as they numerically are the vast majority of crunchers, and there is a very small, very vocal number of high rollers. . . Sensible = dysfunctional and detrimental to the project to pander to archaic hardware and badly configured/managed hosts. Though if the stats that Richard provided are even close to typical (and I would guess that they indeed are) then it is mainly the latter. . . It is a great pity that users who feel they are being in some way disadvantaged by policy choose to say that only to you in a PM rather than contribute to the broader discussion. If they are offended by this discussion then they are indeed very sensitive because it is only the perspective of other users NOT policy being espoused by the boffins that run the show. Stephen :( ID: 2033795 · |

©2025 University of California
SETI@home and Astropulse are funded by grants from the National Science Foundation, NASA, and donations from SETI@home volunteers. AstroPulse is funded in part by the NSF through grant AST-0307956.