Observation of CreditNew Impact (3)
Message boards :
Number crunching :
Observation of CreditNew Impact (3)
Message board moderation
Previous · 1 · 2
| Author | Message |
|---|---|
|
tbret Send message Joined: 28 May 99 Posts: 3380 Credit: 296,162,071 RAC: 40 
|
Jason, please don't let that bother you. The advantage you have over most of us is that you know what you did and see the results in your testing. Unfortunately, with "credits" being the only way most of us have to tell what's going-on, it takes a while for us to adjust our perceptions to the new reality. In the meantime it "feels bad" and we can't tell if that tweak we made helped or hurt. And then complicate that with a "mix" of work units (AP, MB, vlars, vhars, vvars) and it takes a long, long time for us to adjust. But don't let our whining out here in the dark take away from what you know you have accomplished. ID: 1416171 · |
|
Lionel Send message Joined: 25 Mar 00 Posts: 680 Credit: 563,640,304 RAC: 597 
|
SETI is one of a few, or perhaps the only, project that uses CreditNew (I call it CreditFew). What evidence do you need Richard? All you have to do is look at the numbers. They tell the story quite clearly. By the way, just after posting the comment above, I also posted a comment in Eric's staff blogg under "What's new about SETI@home v7" to let him know that my comment was there. Overall, what amazes me is the lack of scientific rigor that is being applied to determining what the root cause(s) is/are with the rating system and this behaviour is from the "lead" scientists of the project. Tweaking a knob isn't the solution. ID: 1416174 · |
|
Lionel Send message Joined: 25 Mar 00 Posts: 680 Credit: 563,640,304 RAC: 597
|
Over this same period have you noticed a drop in the average cobblestones awarded for AP task now? Wiggo, I don't believe that I am noticing a drop in average credit awarded for an AP work unit. The credits bounce around quite a bit and in looking at my list of valids, they appear to be similar to before. If we could get a good run of APs for about 10 days straight we should be able to see if there is an indicator towards a change but with the oscillation occurring quite frequently it's a bit difficult to get a sense of it. Lionel ID: 1416201 · |
kittyman  Send message Joined: 9 Jul 00 Posts: 51525 Credit: 1,018,363,574 RAC: 1,004
|
Over this same period have you noticed a drop in the average cobblestones awarded for AP task now? A 10 day AP run??? LOL...you are dreaming, but the kitties would love to see that happen. "Time is simply the mechanism that keeps everything from happening all at once." 
ID: 1416351 · |
|
alan Send message Joined: 18 Feb 00 Posts: 131 Credit: 401,606 RAC: 0 
|
I have been running the optimised CPU applications for MB and AP since 2011 on the same machine and keeping records (by copying them from the fast-deleted workunit sheets) of credits and cpu-seconds. This allows me to graph CPU-seconds per credit (where a lower figure is better "payback"). I don't have a usable GPU in this laptop. I have found that in the past, "shorties" have paid back badly compared to "regular" MB tasks, and that AP's paid back slightly better. Since the introduction of Version 7 MB, the payback for optimised MB apps has roughly halved for me, as can be seen in the graphs, and the payback for AP has improved slightly. The result is quite clear, that there is an imbalance in payback in my case that was not the case before V7. However the "shorties" now seem to pay back at about the same rate as regular MB's. To me, the amount of cpu work done per credit granted is a useful and sensible measure of the value of each credit, where RAC is not, having too many other variables. The only explanation I have seen that makes any sense of this is that the credit granted is "normalised" against the standard, non-optimised, application. In other words, the V7 "standard" app is now performing much better than the V6 one, and is closer to the optimised app than before. What this also seems to mean is that no attempt is made to compare the new credit to the old when it comes to this normalisation, and that every new release of a standard application will reset the value of a "standard" credit. Or, to put it another way, for SETI@home CPU-based MB, V7 credits are devalued with respect to V6 credits as they are based on more efficient applications. Using the optimised apps, you have to work harder to get the same number of credits as before, which is unexpected. It would be interesting to see the same figures for someone running the standard apps, but this can only be done if someone has been saving their run-time figures like I have - the historic data is not publicly available (and may not be saved at all). My graph is therefore wrong to show a continuous line linking V6 and V7 results, and there should be a discontinuity. It is true that the same factors affect everyone on the SETI@home project. The diminished payback compared to AP is now very significant and will result in AP's being grabbed and processed preferentially - which is no bad thing as they are producing real, fully processed results and as far as I know attract funding. This may be why they are now so rewarding. 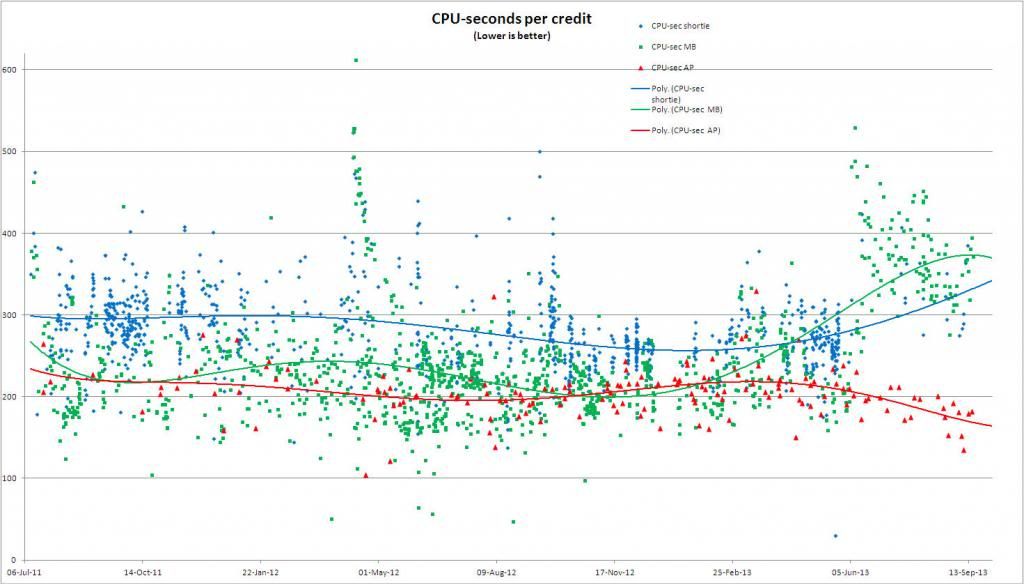 ID: 1416362 · |
Richard Haselgrove  Send message Joined: 4 Jul 99 Posts: 14690 Credit: 200,643,578 RAC: 874
|
To me, the amount of cpu work done per credit granted is a useful and sensible measure of the value of each credit, where RAC is not, having too many other variables. I'd agree with the methodology and the general conclusion: RAC is hopeless for detailed examination like this. One other comment on your final explanation: we had to withdraw the AK_v8 range of optimised CPU applications because of licencing complications. The replacement v7 optimised app, built using GPL-compliant open-source tools, is less tightly optimised than its predecessor. That will account for at least as much of the convergence between the apps as the improved optimisation in the stock app does. ID: 1416377 · |

©2025 University of California
SETI@home and Astropulse are funded by grants from the National Science Foundation, NASA, and donations from SETI@home volunteers. AstroPulse is funded in part by the NSF through grant AST-0307956.