AP V7
Message boards :
Number crunching :
AP V7
Message board moderation
Previous · 1 . . . 14 · 15 · 16 · 17 · 18 · 19 · 20 · Next
| Author | Message |
|---|---|
Richard Haselgrove  Send message Joined: 4 Jul 99 Posts: 14656 Credit: 200,643,578 RAC: 874 
|
OK, a couple of posts relating to recent discussions. Both draw on data from host 7118033, if you want to follow along. First, credit. I set the host up for a long-term AP v7 credit test while I was finalising and testing the installer, two weekends ago. Here are the results to date. 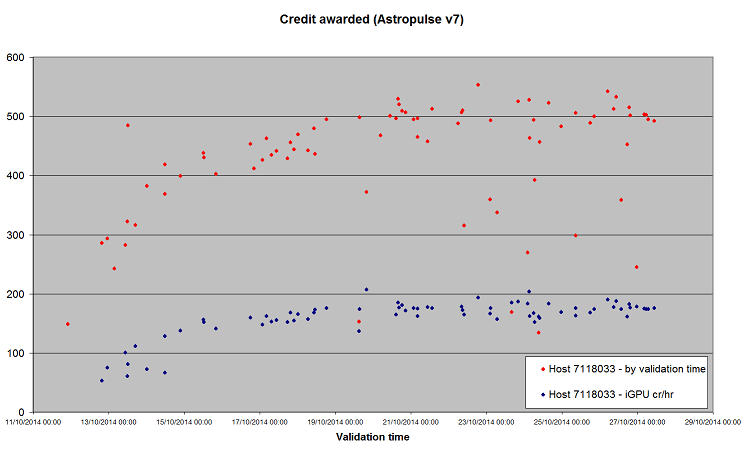 The red dots are the credit awarded for each individual task. The X-axis, labelled 'validation time', is the return time of the final task for the workunit. We know there was a bit of a glitch after the long outage last week, when we know the validator didn't run for a while although a quorum of tasks had been returned, but it's the best I can do. Some of the tasks were run on CPU, but the majority were run on the Intel HD 4600 iGPU - which has the advantage of running at a very stable speed. So, I've plotted the credit per hour of the iGPU tasks as well. I think we can see that credit for AP v7 started low, but has trended up towards ~500 per full-length task - and that the lower credit for individual tasks recently has been accounted for by shorter-running, early-exit tasks, and not by any reduction in the hourly rate. ID: 1592926 · |
|
Richard Haselgrove Send message Joined: 4 Jul 99 Posts: 14656 Credit: 200,643,578 RAC: 874
|
Secondly, the work fetch and server allocation issues we were discussing yesterday. I re-configured the same test host to run SETI MB (only) on the CPU, and AP v7 (only) on the iGPU: then turned up my cache settings to see what arrived. What I saw was entirely consistent with a server stuffed full of MB vlar tasks, and desperate to get rid of them, and with very few, if any, AP tasks available to spread very thinly. I don't think I've been allocated more than 3 non-VLAR tasks for the CPU. And I've seen no evidence at all that the host has been preferentially allocated CPU work, other than that there's a lot of it about. What I have noticed, however, are these lines appearing repeatedly in the event log: 27/10/2014 12:38:58 | SETI@home | Requesting new tasks for CPU and Intel GPU If you look at the task list from my previous post, you'll see that I have - at any time - exactly 100 MB 'tasks in progress' - and I strongly suspect that equates to the 'task in progress' limit for the CPU. I'm not getting my full quota for the iGPU at the moment, but that's almost certainly because there are no tapes loaded and being split right now. What remains as a possibility is that the new server behaviour is "If host is at the limit for CPU tasks, stop looking for any other work to allocate" - in other words, a failure to process the GPU request when it should have been considered. We can't see that in the logs, of course, but I'll think up ways to test it over the next couple of days - with or without another batch of AP v7 to test with. ID: 1592935 · |
|
TBar Send message Joined: 22 May 99 Posts: 5204 Credit: 840,779,836 RAC: 2,768 
|
Secondly, the work fetch and server allocation issues we were discussing yesterday... There was a discussion about work fetch yesterday, but it was about AstroPulse tasks that hadn't reached the 11 completions and were dealing with tasks with estimated run times of 7.5 days. Here, this is what is happening; 1) New AstroPulse App Version Released, Very Long CPU Estimates 2) Client starts downloading First tasks 3) GPUs receive one task per GPU and begins 4) Server starts sending CPU tasks with Estimated 180 hour Run-Times 5) CPU starts task, sees 180 hour Estimate and goes into CPU Panic Mode 6) In CPU Panic Mode BONIC refuses to Download GPU tasks and may Stop GPU Processing I still have One Host that hasn't worked any APv7s yet, http://setiathome.berkeley.edu/host_app_versions.php?hostid=6979629 I can test that host with an ATI 6770 & 4670. I'm willing to predict what will happen. BTW, the Vista host has completed 11 GPU tasks and has an estimate if 1.2 hours. It still hasn't completed 11 CPU tasks and without a flops setting has an estimate of 180 hours. As a test, I removed the CPU flops entry. The CPUs immediately went into Panic mode. I was only able to download a few GPU tasks over a couple hours even with the work cache set to 10 days. As soon as I added the CPU flop setting it downloaded a hand full of tasks at one time and continued to download tasks with the cache set to 2 days. Some of the Host have to Finish 50 CPU tasks to receive those 11 completions. In the case of the slower CPUs, that could take weeks. ID: 1592945 · |
|
Richard Haselgrove Send message Joined: 4 Jul 99 Posts: 14656 Credit: 200,643,578 RAC: 874
|
BTW, the Vista host has completed 11 GPU tasks and has an estimate if 1.2 hours. It still hasn't completed 11 CPU tasks and without a flops setting has an estimate of 180 hours. As a test, I removed the CPU flops entry. The CPUs immediately went into Panic mode. I was only able to download a few GPU tasks over a couple hours even with the work cache set to 10 days. As soon as I added the CPU flop setting it downloaded a hand full of tasks at one time and continued to download tasks with the cache set to 2 days. Having the work cache set to 10 days will likely make it LESS likely you will receive new work. Depending on which version of BOINC that host is running, and which of the two available values you have set to 10 days (they have different effects in different vintages of BOINC client), you have probably reduced the available time before BOINC feels that the work has to be completed and reported, to meet deadline. Thus increasing the sense of panic... My research is designed to address the concern that you ascribed to Claggy: irrespective of client requests, the server code allocates work to CPUs first. I find that 'not proven', but I've suggested a possible area of concern and I'll keep working on it. The question of poor initial estimates for the first 11 tasks is well known, as are the consequences that flow from it. I've reported the problem, several times: finding a solution falls into the area of work that Jason has taken responsibility for. ID: 1592955 · |
|
TBar Send message Joined: 22 May 99 Posts: 5204 Credit: 840,779,836 RAC: 2,768
|
Having the work cache set to 10 days will likely make it LESS likely you will receive new work. Depending on which version of BOINC that host is running, and which of the two available values you have set to 10 days (they have different effects in different vintages of BOINC client), you have probably reduced the available time before BOINC feels that the work has to be completed and reported, to meet deadline. Thus increasing the sense of panic... Please. I'll rephrase it for you. The Work Cache was set to Two Days To Begin With and it Still Didn't Download any Work. I started raising it until I reached 10 Days. Don't you think I was Smart enough to test different Settings? Testing to see which Task is downloaded first is easy. Just start with an Empty Host. Maybe even a Project reset will work on a host that has a number of tasks. Just make sure both CPU and GPU are selected in the Preferences. ID: 1592961 · |
|
Richard Haselgrove Send message Joined: 4 Jul 99 Posts: 14656 Credit: 200,643,578 RAC: 874
|
Having the work cache set to 10 days will likely make it LESS likely you will receive new work. Depending on which version of BOINC that host is running, and which of the two available values you have set to 10 days (they have different effects in different vintages of BOINC client), you have probably reduced the available time before BOINC feels that the work has to be completed and reported, to meet deadline. Thus increasing the sense of panic... And setting the <work_fetch_debug> log flag helps, too. Helps to distinguish between a client request issue, and a server response issue. ID: 1592962 · |
|
TBar Send message Joined: 22 May 99 Posts: 5204 Credit: 840,779,836 RAC: 2,768
|
Having the work cache set to 10 days will likely make it LESS likely you will receive new work. Depending on which version of BOINC that host is running, and which of the two available values you have set to 10 days (they have different effects in different vintages of BOINC client), you have probably reduced the available time before BOINC feels that the work has to be completed and reported, to meet deadline. Thus increasing the sense of panic... I see. You want me to test the XP Host with APv7 and run the work_fetch_debug. Would that be acceptable? You know what will happen, it's the same machine that runs Vista and Ubuntu. ID: 1592967 · |
|
Richard Haselgrove Send message Joined: 4 Jul 99 Posts: 14656 Credit: 200,643,578 RAC: 874
|
Having the work cache set to 10 days will likely make it LESS likely you will receive new work. Depending on which version of BOINC that host is running, and which of the two available values you have set to 10 days (they have different effects in different vintages of BOINC client), you have probably reduced the available time before BOINC feels that the work has to be completed and reported, to meet deadline. Thus increasing the sense of panic... Well, that rather depends what you want. My impression was that you felt there were one (or more) bugs in one (or more) components of BOINC - client, server, or both. And that you wanted those bugs to be fixed. Well, if you want to be part of the solution, instead of part of the problem, it's necessary to narrow the problems down. What's the bug, which component(s) is/are affected, and what change needs to be made. That works better if there is evidence, in writing. If you can use work fetch debug to illustrate whatever problem it is that you think you've identified (and that's far from clear to me, so far), then yes - please supply the evidence. But please be precise about it. 6) In CPU Panic Mode BONIC refuses to Download GPU tasks and may Stop GPU Processing This is an example of the sort of language which I find ambiguous and imprecise. "Download" is a precise technical term in the BOINC client/server system - it refers to a file transfer. Somehow, I don't think that's what you were thinking of. Did you mean that the BOINC client refused to request new GPU work? Or did you mean that the BOINC server refused to allocate new GPU work? That's the sort of question which needs answering, and if you don't have the answer readily to hand, then work fetch debug will help you to distinguish the two cases. ID: 1592973 · |
|
TBar Send message Joined: 22 May 99 Posts: 5204 Credit: 840,779,836 RAC: 2,768
|
6) In CPU Panic Mode BONIC refuses to Download GPU tasks and may Stop GPU Processing When I removed the Flops setting my host was mostly receiving the same response as Cherokee150 was receiving; 10/25/2014 9:48:08 PM | SETI@home | Requesting new tasks for NVIDIA 10/25/2014 9:48:09 PM | SETI@home | Scheduler request completed: got 0 new tasks 10/25/2014 9:48:09 PM | SETI@home | No tasks sent 10/25/2014 9:48:09 PM | SETI@home | No tasks are available for AstroPulse v6 10/25/2014 9:48:09 PM | SETI@home | No tasks are available for AstroPulse v7 Of course mine said ATI. In both cases, there was work available. In my case, it did receive a few downloaded tasks over a couple hours, and began receiving many tasks as soon as I replaced the Flop setting. In the Vista case it already has a valid GPU estimate of 1.2 hours verses the stock 17 hours for a GPU APv7. So, it would be best to use the XP host which hasn't worked any APv7 tasks on main. We will have to wait until more APs are split to test the XP host. As for Cherokee150, you can see his host first started working APv7 on the 23rd, http://setiathome.berkeley.edu/results.php?hostid=3324167 As of the 27th when the tasks dried up, he still hadn't received his first GPU task even though his CPU was working the entire time. Considering that host has a Dual core CPU, it was probably running under CPU Panic the entire time. ID: 1592986 · |
|
TBar Send message Joined: 22 May 99 Posts: 5204 Credit: 840,779,836 RAC: 2,768
|
BTW Richard, Remember this? BOINC isn't blocking the GPUs per se: it's blocking an application which needs both CPU and GPU. I remember it. I just now took the time to track it down, to make sure you remember it. It was Deemed to Not be a Bug, but many would call it such. The Problem is exacerbated when the Server decides to Fill the CPU Cache First, because, the GPUs then don't have any tasks to work when the CPUs go into Panic. It would work better if the GPUs had a Full Cache to work on when the CPUs went into Panic. Then if one of the GPUs were Stopped, one could just Suspend a few CPU tasks until BOINC Allowed the GPU to work again...sorta like our friend merle did a while back at my suggestion... ID: 1593016 · |
|
Richard Haselgrove Send message Joined: 4 Jul 99 Posts: 14656 Credit: 200,643,578 RAC: 874
|
BTW Richard, Remember this? Yes but..... You can only mess about with which application will run first, if you have already "downloaded" (to use your generalisation for either not requesting, or not being allocated) new work first. Can we work out why the work isn't there first, before we decide what to do with it? I'm still not convinced by this categorisation of "fill CPU first", until I've seen a demonstrable (and repeatable) mechanism which prevents "fill GPU second". ID: 1593025 · |
|
TBar Send message Joined: 22 May 99 Posts: 5204 Credit: 840,779,836 RAC: 2,768
|
Here is a recent example, "It keeps loading me up with cpu tasks" I've noticed the same behavior, so have others. I notice it every few days because my Mac is just about out of work every few days. It use to download the GPU tasks first, now it doesn't. Just as others have noted... ID: 1593029 · |
|
Richard Haselgrove Send message Joined: 4 Jul 99 Posts: 14656 Credit: 200,643,578 RAC: 874
|
Here is a recent example, "It keeps loading me up with cpu tasks" So. That's what we're looking for. What makes that decision? What criteria does it use to decide? Please start thinking about some answers, rather than just re-stating the question. ID: 1593045 · |
|
TBar Send message Joined: 22 May 99 Posts: 5204 Credit: 840,779,836 RAC: 2,768
|
Dang, I just looked in my closet...no answers there. Maybe someone on the other end can look in their closet? I'd wager they are more likely to find the answer there. Really ;-) Nothing has changed on this end. I don't have a clue what happened. I'm just reporting the change. ID: 1593049 · |
 HAL9000 HAL9000 Send message Joined: 11 Sep 99 Posts: 6534 Credit: 196,805,888 RAC: 57
|
Here is a recent example, "It keeps loading me up with cpu tasks" Not that is has anything to do with AP v7. Maybe this stuff could be moved to a new thread about the subject? I have noticed a change in behavior reporting work on a machine with a full queue limit. Previously with 100 tasks in the queue if a completed tasks was reported a new one would be sent in the same request. Now a task is not sent & the message "This computer has reached a limit on tasks in progress" is displayed. Then on the next request for work a new task is sent. SETI@home classic workunits: 93,865 CPU time: 863,447 hours  Join the [url=http://tinyurl.com/8y46zvu]BP6/VP6 User Group[ Join the [url=http://tinyurl.com/8y46zvu]BP6/VP6 User Group[
ID: 1593060 · |
|
Richard Haselgrove Send message Joined: 4 Jul 99 Posts: 14656 Credit: 200,643,578 RAC: 874
|
Here is a recent example, "It keeps loading me up with cpu tasks" Fine by me, if anybody has the energy to read through it and decide what does and doesn't belong. I have noticed a change in behavior reporting work on a machine with a full queue limit. Previously with 100 tasks in the queue if a completed tasks was reported a new one would be sent in the same request. Now a task is not sent & the message "This computer has reached a limit on tasks in progress" is displayed. Then on the next request for work a new task is sent. Probably depends on which version of the BOINC client you use. I've been getting this all day: 27/10/2014 18:55:06 | SETI@home | Computation for task 10jn14aa.24202.12337.438086664207.12.246.vlar_1 finished 27/10/2014 18:55:06 | SETI@home | Starting task 12jn14aa.24082.13155.438086664204.12.251.vlar_0 27/10/2014 18:55:06 | SETI@home | [cpu_sched] Starting task 12jn14aa.24082.13155.438086664204.12.251.vlar_0 using setiathome_v7 version 700 in slot 4 27/10/2014 18:55:08 | SETI@home | Started upload of 10jn14aa.24202.12337.438086664207.12.246.vlar_1_0 27/10/2014 18:55:12 | SETI@home | Finished upload of 10jn14aa.24202.12337.438086664207.12.246.vlar_1_0 27/10/2014 18:55:13 | SETI@home | [sched_op] Starting scheduler request 27/10/2014 18:55:13 | SETI@home | Sending scheduler request: To fetch work. 27/10/2014 18:55:13 | SETI@home | Reporting 1 completed tasks 27/10/2014 18:55:13 | SETI@home | Requesting new tasks for CPU and Intel GPU 27/10/2014 18:55:13 | SETI@home | [sched_op] CPU work request: 969280.44 seconds; 0.00 devices 27/10/2014 18:55:13 | SETI@home | [sched_op] Intel GPU work request: 383937.49 seconds; 0.00 devices 27/10/2014 18:55:16 | SETI@home | Scheduler request completed: got 1 new tasks 27/10/2014 18:55:16 | SETI@home | [sched_op] Server version 705 27/10/2014 18:55:16 | SETI@home | Project requested delay of 303 seconds 27/10/2014 18:55:16 | SETI@home | [sched_op] estimated total CPU task duration: 7933 seconds 27/10/2014 18:55:16 | SETI@home | [sched_op] estimated total Intel GPU task duration: 0 seconds 27/10/2014 18:55:16 | SETI@home | [sched_op] handle_scheduler_reply(): got ack for task 10jn14aa.24202.12337.438086664207.12.246.vlar_1 27/10/2014 18:55:16 | SETI@home | [sched_op] Deferring communication for 00:05:03 27/10/2014 18:55:16 | SETI@home | [sched_op] Reason: requested by project 27/10/2014 18:55:18 | SETI@home | Started download of 21jn14aa.15871.2930.438086664208.12.3.vlar 27/10/2014 18:55:30 | SETI@home | Finished download of 21jn14aa.15871.2930.438086664208.12.3.vlar - all done and dusted in 24 seconds. I won't bore you with the full work_fetch_debug, but this version - 7.4.22 - deliberately doesn't start the request for new work until the upload is complete and the task just finished is ready to report. That's swapping CPU task for CPU task, of course, which is where my limit is biting. Are you sure you're reporting a task from the resource which is maxxed out? ID: 1593081 · |
|
TBar Send message Joined: 22 May 99 Posts: 5204 Credit: 840,779,836 RAC: 2,768
|
Another change that occurred with the Server. Use to be just about all the re-sends went to my GPUs. Makes sense, I have 3 GPUs that average around 30 minutes per AP and only run 2 CPU tasks that average about 9 hours. Now for some reason, just about All the re-sends are sent to my 2 overworked CPUs. That doesn't make much sense when there are 3 hungry GPUs than run dry much quicker than the CPUs. This happened the same time the Server decided to start filling the CPU cache First. My guess is the two are related. Hope that helps. Again, nothing has changed on this end but you can see it here; http://setiathome.berkeley.edu/results.php?hostid=6796479 ID: 1593158 · |
|
Wiggo Send message Joined: 24 Jan 00 Posts: 35199 Credit: 261,360,520 RAC: 489 
|
Is it to hard just to turn your CPU fetch off until your GPU's are happy? Cheers. ID: 1593161 · |
|
TBar Send message Joined: 22 May 99 Posts: 5204 Credit: 840,779,836 RAC: 2,768
|
We are looking for Bugs here. Your suggestion wouldn't help much. My observation might. Now if you can come up with a theory why the Server has changed it's behavior that would be welcome. I have a working theory, but, I suspect it's the same one a few other people already have. ID: 1593165 · |
|
Wiggo Send message Joined: 24 Jan 00 Posts: 35199 Credit: 261,360,520 RAC: 489
|
You're going to have what you see as a bug no matter which way the hardware fetch is orientated, others found it as being a bug when it was the fetch was other way around, but there is a simple way around it available which only requires a couple of clicks. Personally either way I don't regard as a bug at all. Cheers. ID: 1593168 · |

©2024 University of California
SETI@home and Astropulse are funded by grants from the National Science Foundation, NASA, and donations from SETI@home volunteers. AstroPulse is funded in part by the NSF through grant AST-0307956.