SETI and Einstein Cooperation on a Q6600
Message boards :
Number crunching :
SETI and Einstein Cooperation on a Q6600
Message board moderation
| Author | Message |
|---|---|
|
archae86 Send message Joined: 31 Aug 99 Posts: 909 Credit: 1,582,816 RAC: 0 
|
I think Richard Haselgrove may have made a comment on this point a while back, but in the last 24 hours I've been startled to see how large a difference in CPU time I get for a similar SETI work unit depending on whether I have 1 SETI sharing my Q6600 with 3 Einsteins, 2 and 2, or four SETI work units taking the whole machine. The background is that I've been running a small resource share to SETI, so the normal behavior of the scheduler has meant that nearly all my SETI work was done sharing the processor with 3 Einsteins. A few days ago on November 21 I accidentally took on board a large supply of results with short deadlines. At my normal resource share, these would never have gotten done on time, so I thought to work them off by suspending Einstein--so instantly transitioned to 4 SETIs. After a couple of hours, I looked at the machine, and was horrified to see that my usual 20 minute execution times for these things were looking closer to 30 minutes. I resumed Einstein, and adjusted resource share and debts so that immediately the host ran 2 SETI with 2 Einstein. The execution times promptly came down substantially. By evening, I did not have enough of the short-timers to last overnight, but still too many to finish at my usual resource share, so I adjusted again to get 1 SETI and 1 Einstein overnight. The graph represents work on results which were all sent out within a few minutes on November 21, and seem likely to have similar computational requirements. I've labelled points which I believe ran as 1, 2, and 4 SETI processes: 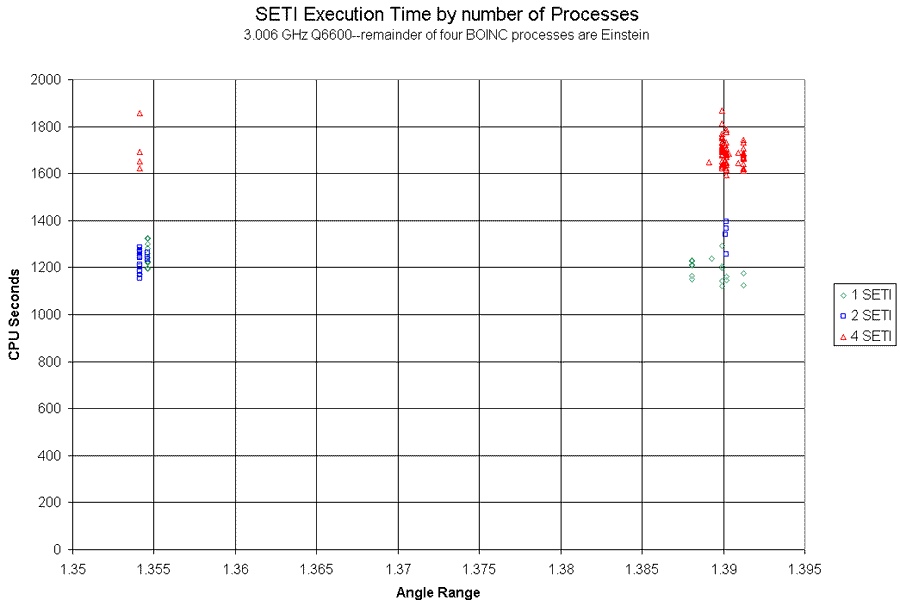 As the processors in a Q6600 are, I believe, quite independent at the CPU level, the major candidates for this effect seem to be forms of memory contention--possibly for cache, or possibly external memory access. While my Q6600 CPU is mildly overclocked at 3.006 GHz, my RAM is a bit overclocked in FSB, but set to very conservative clock counts for its other timings. Given imperfect matching of results, I think the two vs. 1 process comparison is not compelling here, but the four process effect turned on and off exactly, so I am confident that effect is present and large. Using the abundant sample of results near 1.39 AR, the average CPU time for the 4 SETI group is almost 1.42 times the tiem for the 1 SETI group. ID: 684685 · |
|
PhonAcq Send message Joined: 14 Apr 01 Posts: 1656 Credit: 30,658,217 RAC: 1
|
Did you also fix the cpu affinity? If not, then the complexity of timesharing would be daunting to understand (for me at least). I run 2 seti and 2 folding (non-boinc) wu's at once on my (son's) core 2 duo. It is very interesting, in a 60's berkeley mindbending time-wasting sort of way, to see how the four processes are shared against the two cores. Sometimes one hogs one core and the other three share the remaining one. When I launch another app, say excel, then frequently the work is applied to the core that already has three low-priority seti & folding wu's running, leaving the other core running a single seti or folding app. The distributed computing processes all have a low base priority, so the Windows (Vista 64b) cpu affinity seems to be more sophisticated (of course) than just dividing the available cpu time by N for the low priority stuff. ID: 684695 · |
 mimo mimo Send message Joined: 7 Feb 03 Posts: 92 Credit: 14,957,404 RAC: 0 
|
as was writed somewhere cache expensive aplications as seti have some performance degradation on intel quads due memory bottleneck when running on all cores ....  
ID: 684697 · |
|
DJStarfox Send message Joined: 23 May 01 Posts: 1066 Credit: 1,226,053 RAC: 2
|
The best explanation here is increased occurance of page faults in the processor cache. I.e., L2 cache gets emptied when the tasks are preempted by the Windows kernel switching up which processors run which tasks. Either get a bigger L2 cache or set processor affinity for each task. Note: you have to set "leave applications in memory" to true in the global preferences, or else everytime BOINC pauses, each task loses its affinity setting. Another option is to only run 3 tasks with 4 cores; so windows won't have to preempt the BONIC tasks. ID: 684705 · |
|
archae86 Send message Joined: 31 Aug 99 Posts: 909 Credit: 1,582,816 RAC: 0
|
Did you also fix the cpu affinity? No cpu affinity was set. I personally doubt the 4 SETI case would be greatly improved by affinity. The effect is strong enough that I could get a decent test of the hypothesis with a single run of four results selected from this same population. I've started up such a test, so should have some actual data in twenty minutes (if affinity fixes all), or over thirty (if it hurts). ID: 684708 · |
|
archae86 Send message Joined: 31 Aug 99 Posts: 909 Credit: 1,582,816 RAC: 0
|
Did you also fix the cpu affinity? The four results processed under the condtion of all processors running SETI and processor affinity set had Angle Ranges in a region heavily populated from the previous 4 SETI run, for which no affinity was set. So though the sample size is small, moderate confidence may be warranted. The average CPU time for 71 results in this AR set (those very near to 1.39) for the no affinity condition was 1686 seconds, while for the affinity trial it was 1695 seconds. Here is a graph showing the individuals in context: 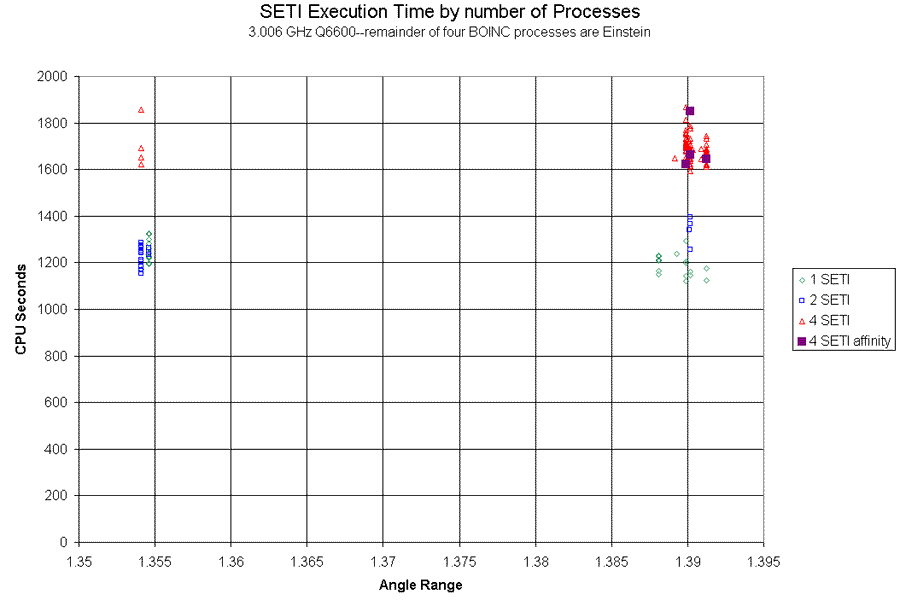 While the increased average is pulled up by one slight outlier in the new run, the other three are clearly in the main distribution, trending a bit below the middle. MY INTERPRETATION Affinity is no magic fix for the effect cited here, and this small trial appears to set a rather low ceiling on any benefit it may have for the system configuration, code, and data at hand. Harm is not excluded based on this experiment. Both possible benefit and harm seem likely to be small compared to the original effect that prompted this thread. The broader question of possible modest benefit of affinity across a representative range of Work Units is not well addressed here, though my previous lack of interest in seeking it is further damped down. ID: 684728 · |
|
ML1 Send message Joined: 25 Nov 01 Posts: 21877 Credit: 7,508,002 RAC: 20 
|
... MY INTERPRETATION I remember that others have already looked at cpu affinity (Crunch3r?) and found no measurable improvement. An interesting test would be to try 3 WUs in parallel: If you get an even spread between the times you already have, then that CPU is either or both cache and FSB limited; However, if you get only the shorter times then you know then that you hit a FSB limit for 4 WUs; If you get only the longer times, then you are FSB limited at 3 WUs. Or, other scenarios? If you run for long enough with three WUs, you might be able to gather statistics for where the bottleneck is. Interesting. Happy crunchin', Martin See new freedom: Mageia Linux Take a look for yourself: Linux Format The Future is what We all make IT (GPLv3) ID: 684794 · |
|
archae86 Send message Joined: 31 Aug 99 Posts: 909 Credit: 1,582,816 RAC: 0
|
I'm skeptical about much depth of bottleneck insight from extended 3-unit runs statistics, and my remaining supply of closely comparable work units would not support an extended test, but there is a big enough gap between 2 and 4 that even a few points could help clarify, so I'll try it for a little while. I am running this one without affinity. ID: 684837 · |
|
ML1 Send message Joined: 25 Nov 01 Posts: 21877 Credit: 7,508,002 RAC: 20
|
An interesting test would be to try 3 WUs in parallel: Good stuff, thanks. Regardless, the plots should give good food for thought even if the conclusion is that nothing can be concluded! However, I've made my hypothesis. Let's see what happens! Happy crunchin', Martin See new freedom: Mageia Linux Take a look for yourself: Linux Format The Future is what We all make IT (GPLv3) ID: 684852 · |
|
Josef W. Segur Send message Joined: 30 Oct 99 Posts: 4504 Credit: 1,414,761 RAC: 0
|
There's a related issue I'd like to see somebody with a quad investigate. Dr who? noted in one of his posts that SETI WUs of distinctly different angle range interfere with each other much less. If clearly demonstrated, perhaps the project would consider modifying their splitting arrangements so there's more of a mix of WUs available to make more efficient use of participants' hosts. Maybe they will even without this motivation, as the simplest fix to the servers choking when all splitters are producing VHAR WUs. For several months I've been using BoincLogX to save WUs as well as results, so I could supply a set of work if anyone is interested. I realize I'm bending the topic somewhat, but I think the basic issue is SETI WUs interfering with each other. It's apparent that sharing with Einstein is an effective antidote, I'm just suggesting there may be alternatives which some participants would prefer. Joe ID: 684888 · |
|
archae86 Send message Joined: 31 Aug 99 Posts: 909 Credit: 1,582,816 RAC: 0
|
I ran a total of six results in "3 SETI, 1 Einstein, no affinity" mode. Direct comparison with the most numerous population for 1 and 4 is a bit compromised by the fact that five of the six came from the secondary peak of AR range. 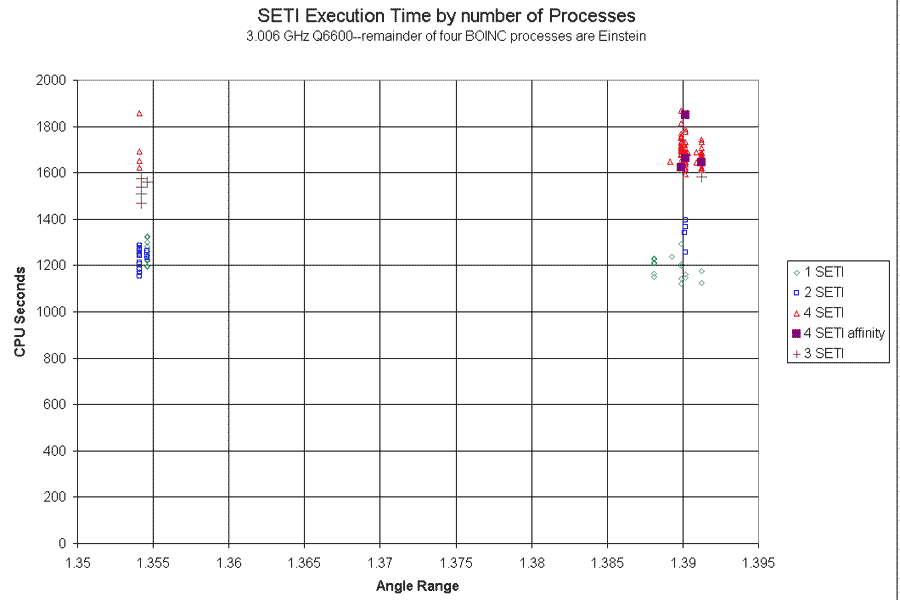 Still, I think one can say that 3 is between 2 and 4, and probably rather closer to 4. Real thoroughness would require assessing the impact on Einstein execution times of varying SETI counterparts, but I suspect the answer is "not much" and don't plan the considerable time investment to check. For the moment I'll just conclude that for folks running both Einstein and SETI, there is a real efficiency benefit to keeping the SETI to two processes or less on a Conroe-class Quad. So the next time you see someone lecturing that "there is nothing to be feared from having the scheduler fall into Earliest Deadline First mode", here is one counterexample. ID: 684891 · |
|
DJStarfox Send message Joined: 23 May 01 Posts: 1066 Credit: 1,226,053 RAC: 2
|
The only thing you've concluded here is that running more than 2 instances/tasks of SETI has a non-linear, diminishing return on RAC with each WU above 2 per physical processor. If your goal is maximize CPU efficiency across all your projects, then yes, limiting SETI to 50% share (2 cores or less) will accomplish that. This processor-application limitation was a very good discovery, IMHO. BTW, I did not see in your original post any attempt to run 4 Einstein tasks, using the same sampling methodology. I wonder if Einstein WU would slow down with more than 2 concurrent tasks? ID: 684937 · |
|
archae86 Send message Joined: 31 Aug 99 Posts: 909 Credit: 1,582,816 RAC: 0
|
BTW, I did not see in your original post any attempt to run 4 Einstein tasks, using the same sampling methodology. I wonder if Einstein WU would slow down with more than 2 concurrent tasks? As I normally run Einstein at 96% resource share on my Q6600, four Einsteins is the norm, and 1 SETI plus 3 Einsteins happens about 16% of the time. The current Einstein work has a rather large systematic variation in CPU required per result, in a pattern first noted by Richard Haselgrove, and discussed in this message and elsewhere in that thread. In principal that effect is systematic enough that one might account for it, but, to quote myself: Real thoroughness would require assessing the impact on Einstein execution times of varying SETI counterparts, but I suspect the answer is "not much" and don't plan the considerable time investment to check. ID: 684951 · |
|
The Gas Giant Send message Joined: 22 Nov 01 Posts: 1904 Credit: 2,646,654 RAC: 0 
|
Back in the early days of BOINC it was quite obvious that running 2 seti units on a P4 HT machine was slower than running 1 seti and 1 climate prediction. I think it was also seen that running 1 seti and 1 einstein was more efficient as well. Live long and BOINC! Paul (S@H1 8888)    And proud of it! And proud of it!
ID: 685052 · |
W-K 666  Send message Joined: 18 May 99 Posts: 19813 Credit: 40,757,560 RAC: 67
|
Having run a Seti/Einstein combination before on dual P3 and P4HT, I'm not surprised at these results from archae86. At that time I was seeing between a 15 to 20 percent in overall performance from Seti if run in 'virtual' affinity mode with an Einstein unit. Not tried it yet with our C2D as now it is running SetiBeta as well, and it is in the middle of doing several 60hr+ AP units. ID: 685101 · |
|
Richard Haselgrove Send message Joined: 4 Jul 99 Posts: 14690 Credit: 200,643,578 RAC: 874
|
Since archae86 has cited me for the 'parallel VHAR' effect and the 'Einstein cycle' effect, here are a couple more from the archives to get you thinking. 1) CPDN coupled models speeded up significantly when the Chicken Coop released a new optimised SETI app (February this year - I think that was Chicken 2.2B ?) 2) CPDN coupled models speed up significantly when SETI Beta is issuing AstroPulse work instead of SETI Enhanced work. The second point is interesting, because it implies that the 'SETI effect' applies to the stock application (as used on Beta), as well as the Chicken optimised apps which both archae86 and I usually use on Main. ID: 685154 · |
|
ML1 Send message Joined: 25 Nov 01 Posts: 21877 Credit: 7,508,002 RAC: 20
|
An interesting test would be to try 3 WUs in parallel:I'm skeptical about much depth of bottleneck insight from extended 3-unit runs statistics, ... I was rather hoping that you would run just the 3 s@h WUs and nothing on the remaining core. The plots tend to be further towards the long times, and from the other anecdotal comments, I think that is suggestive of FSB saturation (bottleneck). That in itself could be triggered by cache thrashing... Interesting, Happy crunchin', Martin See new freedom: Mageia Linux Take a look for yourself: Linux Format The Future is what We all make IT (GPLv3) ID: 685220 · |
|
Josef W. Segur Send message Joined: 30 Oct 99 Posts: 4504 Credit: 1,414,761 RAC: 0
|
There's a related issue I'd like to see somebody with a quad investigate. Dr who? noted in one of his posts that SETI WUs of distinctly different angle range interfere with each other much less. Following up, I've received one expression of interest via Private Message so I put together a zip file with an assortment of MB WUs. There are 9 Multibeam workunit files in the archive. This table lists the angle range, number of Gaussians, Pulses, Spikes, and Triplets reported for each, and the file name: ang_rnge G P S T name 0.006540 0 2 0 2 07mr07af.10918.15205.5.6.151 0.135556 0 1 2 0 08mr07ae.25048.72.7.6.233 0.190456 0 0 0 0 12fe07ac.3882.483.5.5.208 0.307541 1 1 5 0 13fe07ae.26630.1708.4.5.140 0.523717 0 0 5 0 13mr07ae.16236.890.4.6.155 1.032591 2 0 0 0 12fe07ab.25285.309729.12.5.36 1.450429 0 0 3 0 03mr07ag.28094.11933.8.6.134 2.006198 0 0 2 0 09mr07ac.30543.20522.12.6.217 5.371288 0 0 1 2 05mr07ab.25622.364139.4.6.215 Also included are 9 xml files which contain the workunit details as BOINC had in its client_state.xml file, BoincLogX also saves that when set to save WUs. It would be possible to set BOINC to disable Network activity, shut it down and copy the full structure into a test structure, add the WUs to the project directory of the test structure, edit client_state.xml to include references to the added WUs, and do testing using BOINC Manager in the test structure. If anybody undertakes all that, just be sure you don't do anything which would make BOINC phone home. IIRC in recent versions, the No Network Activity setting only controls automatic program access to the network, user actions override the setting. There's also an init_data.xml file suitable for doing standalone tests. The idea is to set up multiple directories, each containing one of the WUs renamed to work_unit.sah, a copy of init_data.xml, and the science application. Then you just launch as many science apps as you have CPUs. If testing on a quad, when the first one finishes, you can go on to the fifth one, etc. In this mode, the init_data.xml is overwritten as the app exits and it includes a <wu_cpu_time> field. The value there is actually the time up through the last checkpoint, if you need more accurate time divide it by the value in the <prog> field of the state.sah checkpoint file. I realize I'm not providing much help. It would obviously be better if there were a script or program which would take care of the details. Consider the WUs as a resource which may also be useful for other comparative testing. Joe ID: 685491 · |
|
archae86 Send message Joined: 31 Aug 99 Posts: 909 Credit: 1,582,816 RAC: 0
|
Since archae86 has cited me for the 'parallel VHAR' effect and the 'Einstein cycle' effect <snip> When I cited Richard Haselgrove, I had not remembered his emphasis on the stronger effect at high Angle Range. Most likely my posts in this thread implied a larger overall impact than is true over the normal distribution of AR, though I suspect it has real relevance when the servers dispense a huge burst of VHAR work units. I have a considerable stock of 20fe07aa results near .38 AR, and just took advantage of today's cloudburst to get a fresh stock of 11ja07ag VHAR results, which seem to be clustered near 2.5 AR. I think I have enough of the two flavors, and that they may be closely enough matched within each flavor, to let me do a comparison of impact of "Einstein ratio" of those two particular AR's, and of mixes between the two flavors in varying proportions. That may feed my thoughts before approaching Joe's stashed test units, for which I need to think a bit on how to proceed. ID: 685761 · |
|
Josef W. Segur Send message Joined: 30 Oct 99 Posts: 4504 Credit: 1,414,761 RAC: 0
|
...took advantage of today's cloudburst to get a fresh stock of 11ja07ag VHAR results, which seem to be clustered near 2.5 AR. Maybe something lasting over 6 hours might better be called a slewstorm than a cloudburst? Joe ID: 685981 · |

©2025 University of California
SETI@home and Astropulse are funded by grants from the National Science Foundation, NASA, and donations from SETI@home volunteers. AstroPulse is funded in part by the NSF through grant AST-0307956.