The Server Issues / Outages Thread - Panic Mode On! (118)
Message boards :
Number crunching :
The Server Issues / Outages Thread - Panic Mode On! (118)
Message board moderation
Previous · 1 . . . 89 · 90 · 91 · 92 · 93 · 94 · Next
| Author | Message |
|---|---|
rob smith  Send message Joined: 7 Mar 03 Posts: 22200 Credit: 416,307,556 RAC: 380 
|
We might be able to raise the money but how can we help with the Time? A fairly simple solution. Recently we've been looking that the capital money (e.g. buying new disks), but there needs to be a fair bit of money for wages, rent, power etc - the revenue spend. My figures might be a bit off, but I would guess it would cost about $100k to cover salary and all other costs for a single person for a year. While not as glamorous as a lump of hardware. Having another pair of hands would ease the burden of daily server tasks to allow the likes of Eric to develop the software and prepare grant applications etc. Bob Smith Member of Seti PIPPS (Pluto is a Planet Protest Society) Somewhere in the (un)known Universe? ID: 2033490 · |
|
Ghia Send message Joined: 7 Feb 17 Posts: 238 Credit: 28,911,438 RAC: 50 
|
Every now and then the servers will send out a few tasks destined for other apps to confirm that you are still using the best performing one. Tnx...makes sense...just finding it funny that it took 3 years... :) Humans may rule the world...but bacteria run it... ID: 2033493 · |
|
Ville Saari Send message Joined: 30 Nov 00 Posts: 1158 Credit: 49,177,052 RAC: 82,530 
|
Tnx...makes sense...just finding it funny that it took 3 years... :)It just took 3 years for you to notice. I guess you didn't watch your queue all the time during those 3 years to make sure no non SoG task slips through. ID: 2033503 · |
 Kissagogo27 Kissagogo27 Send message Joined: 6 Nov 99 Posts: 716 Credit: 8,032,827 RAC: 62 
|
I found one stuck since the end of January https://setiathome.berkeley.edu/show_host_detail.php?hostid=8884799 i am still waiting about it https://setiathome.berkeley.edu/workunit.php?wuid=3861245798 xD ID: 2033511 · |
|
rob smith Send message Joined: 7 Mar 03 Posts: 22200 Credit: 416,307,556 RAC: 380
|
It hasn't reached its deadline, so why panic? Actually that is one of mine, and as I'm not going to be able to get back to it for a few weeks and sort out its power supply you'll just have to be patient Bob Smith Member of Seti PIPPS (Pluto is a Planet Protest Society) Somewhere in the (un)known Universe? ID: 2033514 · |
|
Kissagogo27 Send message Joined: 6 Nov 99 Posts: 716 Credit: 8,032,827 RAC: 62
|
i don't panic at all ;) ID: 2033522 · |
|
juan BFP Send message Joined: 16 Mar 07 Posts: 9786 Credit: 572,710,851 RAC: 3,799 
|
The splitters are down..... again..... This will be going to be a long weekend of ups & downs. No <panic> yet. The WU cache is holding. Need to go for some more six packs for the festivities. <edit< Just because i write this message they are up again. Could be a hell of a coincidence, but apparently each time the AP splitters starts the other goes down for some time. 
ID: 2033530 · |
|
Tom M Send message Joined: 28 Nov 02 Posts: 5124 Credit: 276,046,078 RAC: 462 |
We might be able to raise the money but how can we help with the Time? So how do we raise/funnel the money to fund another Programmer/System Admin? I assume that the director would have to be willing to hire.... And I assume we would need to come up with more than a single years worth of funding. Tom A proud member of the OFA (Old Farts Association). ID: 2033580 · |
|
Grant (SSSF) Send message Joined: 19 Aug 99 Posts: 13736 Credit: 208,696,464 RAC: 304 
|
The splitters are down..... again..... This will be going to be a long weekend of ups & downs.The splitter output is still being limited by the database size. For a while now it's been running in very short bursts. Most of my requests don't result in any work, but when i do get work i get plenty of it for a couple of requests & it's enough to keep the Lunix system fed and the Windows system full to the serverside limits. Grant Darwin NT ID: 2033583 · |
|
pututu Send message Joined: 21 Jul 16 Posts: 12 Credit: 10,108,801 RAC: 6 
|
There are 14 servers of various 2X quad/hex core machines running. How much electricity cost do they consume annually? Considering that these servers are in California (Berkeley?), the electricity rates are relatively high perhaps good to know the actual annual electricity cost. My gut feeling is that if we can consolidate this to a few (Ivy-Bridge, Haswell, Broadwell or EPYC) servers, the payback should be favorable? From reading some of the posts below, it seems that there are two or three main items that can help to reduce the current outage/panic/server issues: 1. Tasks/WU management and distribution (e.g. setting short deadline, limit the number of tasks downloaded depending on task time return, etc, etc) 2. Hardware (bandwidth, CPU speed, storage, RAM, etc). 3. Maybe software upgrade/overhaul (goes together to take advantage of the newer hardware capabilities?) From my limited experience and exposure to SETI@home, this is what I think. Item 1 seems like something that can be optimized relatively easy when compare to item 2 and 3 and perhaps as a short term solution. May not cost a lot of money and time when compare to item 2 or 3 or I'm completely out of touch. However after having optimizing the task management/distribution, the project will likely hit a wall again because it will eventually be hardware limited if SETI@home decides to attract more donors. My humble one cent. :) ID: 2033599 · |
|
AllgoodGuy Send message Joined: 29 May 01 Posts: 293 Credit: 16,348,499 RAC: 266
|
There are 14 servers of various 2X quad/hex core machines running. How much electricity cost do they consume annually? Considering that these servers are in California (Berkeley?), the electricity rates are relatively high perhaps good to know the actual annual electricity cost. My gut feeling is that if we can consolidate this to a few (Ivy-Bridge, Haswell, Broadwell or EPYC) servers, the payback should be favorable? These are definitely higher costs than most areas, which is counter intuitive to California's power plan as the state is actually paying Arizona to take power off its grid due to overproduction. One thing which is very debatable in my most humble of opinions is the ability for Berkeley to even interest a soul to work there for a mere $100K/yr. in one of the top 5 highest cost of living areas in the nation, possibly the world. Perhaps some undergrad attending the university wishing to enter into an internship. We might as well be talking about funding a solar/wind generation site for the university for cost reduction and redundancy when the state or PG&E forces brownouts. Perhaps we can gain interest from the panic crowds in the Global Climate debates??? :) That would be a long term reduction of costs for the university as a whole. #1 is a very feasible suggestion, and most of that work is already done if you look at the breakdown per host on a per plan class basis (needs a bit of tweaking, but it is a good start), it would be a feasible move to limit outgoing work on a machine's own track record, and should be easy to implement with little overhead. For the sake of the crowd who wants to allow the largest number of members the ability to crunch numbers, I would suggest that we set limits based on a security measure. That is, don't allow hardware on the system which will not run a supportable operating system which is actively writing fixes, or we disallow hardware which is outside that scope by a time limit no more than 2 years outside of such software limits. That just makes sense, and allows the system a higher floor, which corresponds with actual growth in the field. There is something to be said about the soft bigotry of low expectations here. The system as a whole should not cut off its nose to spite its face. We want people to participate at maximum potential, but when the entire system suffers because of our want to allow some to run antiquated hardware, we shoot for mediocrity not excellence. Edit* That said, if one sets limits too low on their equipment, or doesn't turn on their computer very often, that is a choice the person makes. Setting a much lower turn around limit is not an impractical move. If storage space, memory, and software limitations were not an issue, we wouldn't even have this discussion. We are however, having this discussion. These policies have led us to what is perhaps our own limits set not by the hardware, but our own permissiveness in policy. This is having serious ramifications systemwide, and is correctable. We can talk about increasing the hardware in a dream list, and come up with other measures at a cost. We can also make a decision to change a policy and avoid the cost while at the same time correcting the system, and extending the life of these systems as they exist. My humble opinion is to say that policy > hardware changes, at least in the foreseeable timeframe. This can extend the ability for some to make rational purchase decisions for the future based on sensible, and planned needs. My stinky opinion for what it's worth. ID: 2033606 · |
|
Ghia Send message Joined: 7 Feb 17 Posts: 238 Credit: 28,911,438 RAC: 50
|
Tnx...makes sense...just finding it funny that it took 3 years... :)It just took 3 years for you to notice. I guess you didn't watch your queue all the time during those 3 years to make sure no non SoG task slips through. I look through my tasks each morning and at least a couple of times throughout the day. On my slow cruncher, that would catch such strangers. Humans may rule the world...but bacteria run it... ID: 2033626 · |
|
rob smith Send message Joined: 7 Mar 03 Posts: 22200 Credit: 416,307,556 RAC: 380
|
Simple - just make a donation to SETI@Home by our preferred mechanism, if you don't say it is for a special fund raiser then it goes to running the pool for general running of the project. The funding for a new member of staff should not be for one year, but for a number of years - short term staff (including interns and research students) are OK for doing a secific, well defined task, but what the project needs is a stable core of staff onto which one adds the short-term staff. Bob Smith Member of Seti PIPPS (Pluto is a Planet Protest Society) Somewhere in the (un)known Universe? ID: 2033631 · |
|
Tom M Send message Joined: 28 Nov 02 Posts: 5124 Credit: 276,046,078 RAC: 462 |
It does help keep our sinuses clear though... :) Tom A proud member of the OFA (Old Farts Association). ID: 2033718 · |
|
Tom M Send message Joined: 28 Nov 02 Posts: 5124 Credit: 276,046,078 RAC: 462 |
For what it is worth of the projects I participate in, Seti@Home has the most relaxed "due" schedule. Many of my other projects allow a week or less per task. An experiment might be reduce the deadline to say 2 weeks and see if the load drops off because tasks are not sitting idle in the DB. If possible could we split the deadlines making the gpu tasks say a week or under? Tom A proud member of the OFA (Old Farts Association). ID: 2033719 · |
Gene  Send message Joined: 26 Apr 99 Posts: 150 Credit: 48,393,279 RAC: 118
|
TomM proposes/suggests reducing the deadline to 2 weeks. I would vote for a less "ambitious" adjustment to the deadlines. I do observe that the AstroPulse tasks are issued with a 26-day deadline, as compared to the 60-day deadline for everything else. If the deadline were reduced to perhaps 40 or 50 days and allowed to remain there a couple of months (i.e. long enough to stabilize to some sort of equilibrium) that ought to give the project some hard data on the effects on database issues and resend statistics. Then decide whether it was a mistake - and revert to previous values; or, decide it was a positive move and, perhaps, continue adjusting deadlines in similar small steps. ID: 2033727 · |
|
Grant (SSSF) Send message Joined: 19 Aug 99 Posts: 13736 Credit: 208,696,464 RAC: 304
|
An experiment might be reduce the deadline to say 2 weeksSee all of my previous posts on reducing deadlines. Grant Darwin NT ID: 2033731 · |
|
Speedy Send message Joined: 26 Jun 04 Posts: 1643 Credit: 12,921,799 RAC: 89 
|
Tasks are been removed after they have sat in your validated list for a period of time. But I am unsure if the purge queue is working properly on the server status page because I have not seen this rise over 300,000 in probably almost a week. I just find it interesting that all I'm pleased results are being deleted. I also see that we are back up to over 6 million results out in the field 
ID: 2033732 · |
|
rob smith Send message Joined: 7 Mar 03 Posts: 22200 Credit: 416,307,556 RAC: 380
|
I'm republishing this chart I posted a month ago. The x-axis is time *days pending), the y-axis is the percentage remaining to be validated. At 10 days pending there are still between 50% & 60% of the tasks waiting, at 30 days, this drops to between 20, and 30%and by 50 days we are down into the noise. 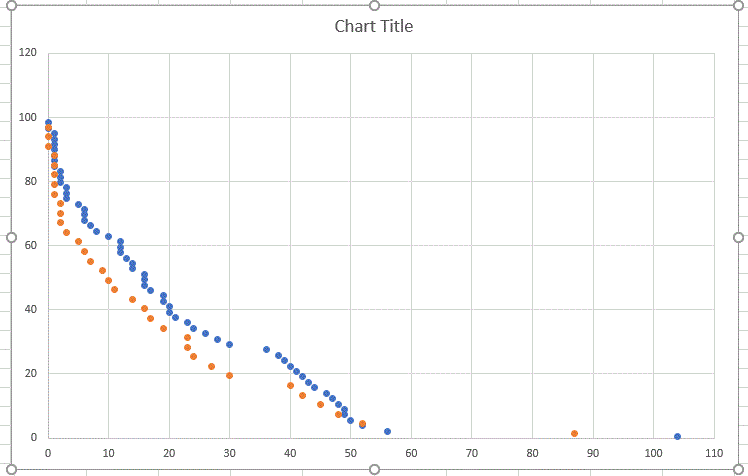 The peculiar gap between 30 and 40 days was the "Christmas Debacle", when nothing really got validated. So what does this mean? A deadline reduction to 10 days would shove the resends through the roof, and turn a large number of currently useful-if-slow hosts into slow-but-useless hosts - they just wouldn't return their data in time and that data forms a very large proportion of the total. A deadline reduction to 30 day still push the resends through the roof, and again turn a large number of currently useful-if-slow hosts into slow-but-useless hosts - they just wouldn't return their data in time and that data forms a fair proportion of the total. A deadline of 40 days would see between 10% and 20% resends, getting less hostile to the slow-but-productive hosts. A deadline of 50 days, and the resends drop to ~5%, much less hostile on the slow-but-productive hosts. I would suggest that the sweet-spot may be deadlines around 40-50 days, where the impact on the slowest hosts is probably about as low as one can reasonably expect. Bob Smith Member of Seti PIPPS (Pluto is a Planet Protest Society) Somewhere in the (un)known Universe? ID: 2033734 · |
|
Richard Haselgrove Send message Joined: 4 Jul 99 Posts: 14650 Credit: 200,643,578 RAC: 874
|
It would be interesting to know - but we can probably only speculate - under what circumstances a slow-but-useful computer returns a valid task after 50 days. 1) It really is that slow! 2) It only crunches part time. 3) It crunches, but only a small proportion of its time is spent on SETI 4) It broke down, but the owner took time to source and install replacement parts 5) It broke down, but the owner didn't notice 6) It was caught by a driver problem, but the owner didn't know how to handle it 7) It spends a lot of time out of reach of the internet and so on. I'm sure we can think of many more. ID: 2033735 · |

©2024 University of California
SETI@home and Astropulse are funded by grants from the National Science Foundation, NASA, and donations from SETI@home volunteers. AstroPulse is funded in part by the NSF through grant AST-0307956.