The Server Issues / Outages Thread - Panic Mode On! (118)
Message boards :
Number crunching :
The Server Issues / Outages Thread - Panic Mode On! (118)
Message board moderation
Previous · 1 . . . 91 · 92 · 93 · 94
| Author | Message |
|---|---|
Stephen "Heretic"  Send message Joined: 20 Sep 12 Posts: 5557 Credit: 192,787,363 RAC: 628 
|
. . Except that the majority of that 'delay' on the slow hosts is not due to their low productivity so much as their oversized caches. The reason they sit on tasks for 50 days is not because it takes them that long to process a task, but because WUs sit in their 'in progress' status for weeks on end before they get around to processing them.In theory, if a WU is processed it should be done within 20 days (10+10 for cache settings).* . . You have omitted the factor that Rob seems very concerned about, part time crunchers. A 10+10 cache is based on run times and 24/7 capablility, but a machine (and there are many of them Rob believes) that only runs a couple of hours a day would take many, many times that long to get through the work allocated. If comparing machines to avoid same hardware false validations then run times are the criterion, but when calculating work allocation it should be turn around time that is used. If a machine returns only 1 task per week because it is sub-normally slow and very much part time, then it should have a limit of maybe 5 tasks; compared to a machine that completes 12 tasks every 5 mins and has a return time of about 1 hour (based on a 150 WU cache). Stephen . . ID: 2033782 · |
|
rob smith Send message Joined: 7 Mar 03 Posts: 22190 Credit: 416,307,556 RAC: 380 
|
Yes, I am concerned about the part-time crunchers, as they numerically are the vast majority of crunchers, and there is a very small, very vocal number of high rollers. And remember that SETI has worked very hard to ensure a very wide user base, and if that means having sensible deadlines then we have to live with it, and not cheat by bunkering, re-scheduling or GPU-spoofing, all of which deprive the MAJORITY of user of tasks. I get at least one PM a week from someone who is leaving SETI@Home because of the attitude of some of the high rollers and greedy. Bob Smith Member of Seti PIPPS (Pluto is a Planet Protest Society) Somewhere in the (un)known Universe? ID: 2033785 · |
|
Stephen "Heretic" Send message Joined: 20 Sep 12 Posts: 5557 Credit: 192,787,363 RAC: 628
|
Have you ever worked out how much it would "hurt" the super-fast hosts? . . OK that's easy enough . . Since you stipulated 'super-fast' lets look at a machine such as Keith and Ian use. . . Each task takes less than a minute, closer to 30 secs, so on a per device basis the 150 current limit would last about 1.25 hours but let's say 2 hours. So a 4 hour absence of new work would see them idle for at least 2 hours or 100% detriment, an 8 hours lack of work would see them idle for over 6 hours or at least a 300% detriment. Slightly more than your estimation of less than 10%. . . Now if you drop back to a more pedestrian machine like the one I am using with a GTX1050ti which only return 16 or so tasks per hour on average then even the 8 hour drought would be kind of survivable ie 0% detriment, on the premise that sufficient work is immediately available at the end of the 8 hours. But there are hundreds or thousands of machines between those two levels, take a look at the top host listing and try to find the ones with RACs under 25,000. Stephen ID: 2033788 · |
|
rob smith Send message Joined: 7 Mar 03 Posts: 22190 Credit: 416,307,556 RAC: 380
|
Reduced server side limits would have no effect on those super slow hosts but would hurt fast gpus disproportionally. When the limit was 100 per GPU, my cache was limited to less than 2 hours and I have just a cheap mid range graphics card. I'm not sure HOW you generated your curve, but here is a plot of percent tasks pending vs days pending from data earlier today: 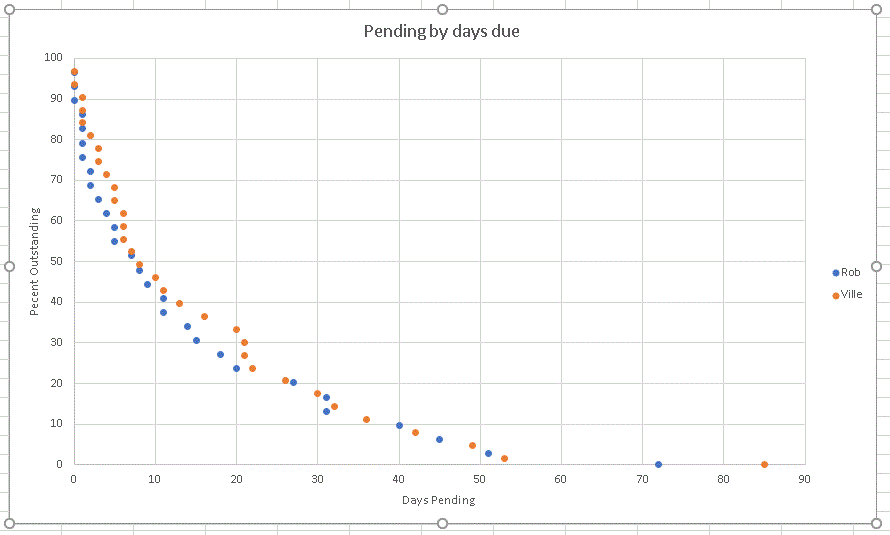 The key is not looking at tasks that have validated, but at those that are still pending - these are the ones that need to be moved into validation, and thus out of the day-to-day database, but into the main database - remember pending tasks have to be "monitored" by the servers to make sure they don't become over-due tasks (which then need to be re-sent), or "dead" tasks (those which have reached their limit on re-sends). As you can see there is a marked difference in the shape of the curve, and the position of the curve, some of this may be down to sampling techniques (I sampled every 20th task), but that goes nowhere near explaining the vast difference between the two sets of curves. In my plot you can see where we each had a "bump" in the validation rates before the 55 day cut-off was reached - something I would expect, but is totally lacking in Ville Saari's plot. Bob Smith Member of Seti PIPPS (Pluto is a Planet Protest Society) Somewhere in the (un)known Universe? ID: 2033790 · |
|
Stephen "Heretic" Send message Joined: 20 Sep 12 Posts: 5557 Credit: 192,787,363 RAC: 628
|
BTW I still believe the only practical solution, with the available server hardware & software is to limit the WU cache to something like 1 day of the host actual returning valid tasks number, for all the hosts, fastest or slower. And even that will give only some extra time. . . Hi Juan, . . You well know my ideal is the one day (max) cache. But we do need to maintain 'good faith' with the more timid volunteers who only log in once per week. Still not sure there are very many (if any) people using dial ups. But some may be using metered services. Stephen :) ID: 2033793 · |
|
rob smith Send message Joined: 7 Mar 03 Posts: 22190 Credit: 416,307,556 RAC: 380
|
Thanks Stephen. You have provided some sensible figures, and a rationale behind them - I just did the figures on one of Keith's computers and came up with about 45s/per task. Your conclusions are somewhat dubious - as the "hit" has to be taken in terms of tasks per week (168 hours), thus a loss of 1 hour is ~0.6%, so a loss of two hours is ~1.2%, and 6 hours is ~3.6%. Which I think you will agree is much less than my first guess, based on no evidence apart from thinking "they will be double the speed of my Windows based host", of ~10%. If we think in terms of RAC, 4% may well be less than the gain/hit from having a great pile of APs vs a great pile of poor-payers (whatever they may be this week). Bob Smith Member of Seti PIPPS (Pluto is a Planet Protest Society) Somewhere in the (un)known Universe? ID: 2033794 · |
|
Stephen "Heretic" Send message Joined: 20 Sep 12 Posts: 5557 Credit: 192,787,363 RAC: 628
|
Yes, I am concerned about the part-time crunchers, as they numerically are the vast majority of crunchers, and there is a very small, very vocal number of high rollers. . . Sensible = dysfunctional and detrimental to the project to pander to archaic hardware and badly configured/managed hosts. Though if the stats that Richard provided are even close to typical (and I would guess that they indeed are) then it is mainly the latter. . . It is a great pity that users who feel they are being in some way disadvantaged by policy choose to say that only to you in a PM rather than contribute to the broader discussion. If they are offended by this discussion then they are indeed very sensitive because it is only the perspective of other users NOT policy being espoused by the boffins that run the show. Stephen :( ID: 2033795 · |
|
juan BFP Send message Joined: 16 Mar 07 Posts: 9786 Credit: 572,710,851 RAC: 3,799 
|
BTW I still believe the only practical solution, with the available server hardware & software is to limit the WU cache to something like 1 day of the host actual returning valid tasks number, for all the hosts, fastest or slower. And even that will give only some extra time. That could be easy solved by setting a minimum buffer for this type of hosts. Something like select the minimum 1 to 10 WU or whatever number. Not a fix 150 limit per device. What we need to avoid is those who pick a larger number of WU and never returning them in time. Above this hypothetical number your host will receive only what he could rely crunch and return valid in a day or whatever is used as a base line. In this scenario, if your host return 30 valid WU per day you can have a buffer of 30. If it can (like Ian) return 8K WU per day, his buffer could be 8K too. Simple like that. You could receive what you do. If your host only return invalids, error or even not return any valid WU it will be limited to the minimum buffer until you fix that. The stats are already available and are updated in a daily basis AFAIK. 
ID: 2033796 · |
|
rob smith Send message Joined: 7 Mar 03 Posts: 22190 Credit: 416,307,556 RAC: 380
|
I just looked to see where your mid-range hitter (RAC ~27000) sits on the scale of things, I can't find it, but based on the current RAC somewhere around 810, and mine with a RAC of ~42000 is sitting at about 370. This just goes to show how long the tail is, and how few "big hitters" there really are. ARGHHHH - nothing you've done, I just hit a limit on how far back along the hosts list one could go - 10000 is the last host that one can scroll offset to, by which time the RAC has dropped to ~5700 - the mid-range is certainly flatter than I expected..... Bob Smith Member of Seti PIPPS (Pluto is a Planet Protest Society) Somewhere in the (un)known Universe? ID: 2033797 · |
|
Stephen "Heretic" Send message Joined: 20 Sep 12 Posts: 5557 Credit: 192,787,363 RAC: 628
|
Thanks Stephen. . . Hi Bob, . . If your model is predicated on a one week time frame you should have specified a "single" 8 hour cessation of WU supply ( we are talking maintenance outage then ?) in that week. Since lately the outages have been far longer than 8 hours with protracted recovery periods with no new WUs available then the impact is proportionally higher. And with the server issues there have typically been more than one each week. But based on your model then yes, you have established a scenario with an overall loss of less than 10%. However this discussion, from my side, is about productivity not RAC. Sadly the two are not actually proportional. Stephen . . ID: 2033799 · |
|
Ian&Steve C. Send message Joined: 28 Sep 99 Posts: 4267 Credit: 1,282,604,591 RAC: 6,640 
|
Yes, I am concerned about the part-time crunchers, as they numerically are the vast majority of crunchers, and there is a very small, very vocal number of high rollers. if you're worried about bunkering then you should be in support of shorter deadlines, as that vastly limits the amount of WUs that can be bunkered before expiring. 2-3 week deadlines are more than sensible enough. if someone isn't going to finish a WU in that time, then it shouldn't be taking up valuable RAM space. let someone who's actually willing to do the work... do the work. Seti@Home classic workunits: 29,492 CPU time: 134,419 hours  
ID: 2033800 · |
|
Stephen "Heretic" Send message Joined: 20 Sep 12 Posts: 5557 Credit: 192,787,363 RAC: 628
|
I just looked to see where your mid-range hitter (RAC ~27000) sits on the scale of things, I can't find it, but based on the current RAC somewhere around 810, and mine with a RAC of ~42000 is sitting at about 370. This just goes to show how long the tail is, and how few "big hitters" there really are. . . Yes, that extended flat mid range is where the bulk of the work gets done, with the majority of the remainder at the top end. Stephen . . ID: 2033802 · |
Richard Haselgrove  Send message Joined: 4 Jul 99 Posts: 14650 Credit: 200,643,578 RAC: 874
|
That long tail is very hard to search, which is why I attacked the question by looking at the wingmates on my long-term pendings. The region I looked at - more than four weeks after issue - is where any time-stressed hosts would show up. But I didn't see any hosts (in that admittedly small sample) that showed any indication that - given another four weeks - they would complete the task in question. It's only the hosts that need to run up to the wire, but would then deliver a completed task at the last possible moment, that we need to worry about. ID: 2033804 · |
|
juan BFP Send message Joined: 16 Mar 07 Posts: 9786 Credit: 572,710,851 RAC: 3,799
|
and not cheat by bunkering, re-scheduling or GPU-spoofing, all of which deprive the MAJORITY of user of tasks. I get at least one PM a week from someone who is leaving SETI@Home because of the attitude of some of the high rollers and greedy. Was a long time i not hear that work..... cheat!!! Boinc code is open, so anyone could do what he want with it. Why you call "cheat" if someone has the capacity of upgrade it? This is not the main idea of "open source code"??? If make changes on the code is "cheating" we are all are cheaters, since the lunnatics code was an upgrade of the original crunching code or not? The Linux Special sauces is a "cheat" too? This seems like the old children's aptitude: "if i not could have it" then "nobody could" Please not follow this "dark path" nothing good could come by doing that. And if you look at the boinc main page they clearly shows: BOINC software development is community-based. Everyone is welcome to participate.
ID: 2033806 · |
|
Stephen "Heretic" Send message Joined: 20 Sep 12 Posts: 5557 Credit: 192,787,363 RAC: 628
|
Ah well, we all know where elitism leads. . . These are the people who (hopefully) get tasked with making things work, so the authority comes with the job. The quality of dubious merit is 'wealth' where the only special talent may be greed (tinged with dishonesty). Keep on smiling. Stephen :) ID: 2033807 · |
|
rob smith Send message Joined: 7 Mar 03 Posts: 22190 Credit: 416,307,556 RAC: 380
|
I do support shorter deadlines -but not the excessively short ones suggested by yourself, but realistic ones that will enable the vast majority of users to return data in time, others have suggested a month (30 days) - which would cover in excess of 80% of the pending tasks, without too much of a down on the really slow hosts. Yes, reduced deadlines would reduce the amount of work out in the field. But so would turning off GPU-spoofing - on a continuous basis that would probably reduce the work in the field by a few hundred thousand tasks, with the added advantage that during the recovery from an outage hosts would only be asking for 150 (current limit) tasks per GPU, not the 300 to 1500 per GPU, further, because some spoofed hosts never appear to completely fill their limit they are always requesting excessive amounts of work, not the "one-in-one-out" that they actually need - these excessive calls cost quite a bit of server time to sort out, and must regularly deplete the very small (200) send buffer, so causing other users to have to make additional requests for their one or two tasks needed to replenish their stocks. Bob Smith Member of Seti PIPPS (Pluto is a Planet Protest Society) Somewhere in the (un)known Universe? ID: 2033810 · |
|
Oddbjornik Send message Joined: 15 May 99 Posts: 220 Credit: 349,610,548 RAC: 1,728 
|
... and not cheat by bunkering, re-scheduling or GPU-spoofing, all of which deprive the MAJORITY of user of tasks. I get at least one PM a week from someone who is leaving SETI@Home because of the attitude of some of the high rollers and greedy.I take exception to this kind of wording. The project asks for and needs as much processing power as it can get. I maximize utilization of my hardware by GPU-spoofing and by using the mutex-build to preload tasks to the GPUs under linux. I buffer slightly more than a day's worth of work across all my crunchers. The "buffer work for" setting is at 1,2 days + up to 0,3 days additional. Only the slowest hosts last that long. Don't see anything objectionable in this thinking. ID: 2033811 · |
|
Richard Haselgrove Send message Joined: 4 Jul 99 Posts: 14650 Credit: 200,643,578 RAC: 874
|
I've spent a little time talking with users of the spoofed client since I built my first Linux machine last year, and I've been reassured by what I've heard. As they've also posted openly here, they are aware of their responsibility towards the project servers: they try not to make big requests at busy times (such as during outage recovery), and the main working principle is 'cache enough to cover the likely duration of outage + recovery'. I haven't come across anyone who simply turns all the knobs up to 11 and leaves all the rest of us to suck it up. I logged all the recorded turnround times for the top 100 hosts a few days ago. Well over half of them returned work, on average, within 6 hours: 89 of the 100 returned it within a day. Only one had a turnround of more than 4 days. ID: 2033813 · |
|
rob smith Send message Joined: 7 Mar 03 Posts: 22190 Credit: 416,307,556 RAC: 380
|
While BOINC code is open SETI @Home has decided, for better or worse, that there should be limits on the number of tasks for a host. These limits are (as far as I'm aware) 150 for the CPU (regardless of how many you have, or how many cores they have), and 150 per GPU. If a user claims to have 64 GPUs on a system which only has 8 then that is LYING, possibly in an endeavour to CHEAT. This is totally unlike the Special Sauce, which improves upon the existing code and makes it more efficient. There is a mechanism within BOINC, and permitted by SETI@Home that has allowed such developments, provided the results obtained by the use of the numerical analysis techniques deployed are in line with those obtained using the existing set of numerical analysis techniques. Please remember that the current crop of "stock" applications were at one time at the cutting edge, following optimisation of and earlier generation of applications. I would love to see someone get hold of the Linux Special Sauce application and get it working under Windows, but that won't happen until a developer with the right skills appears on the scene. (There was one, Jason, who started but "life got in the way" and he dropped out of sight.) Bob Smith Member of Seti PIPPS (Pluto is a Planet Protest Society) Somewhere in the (un)known Universe? ID: 2033814 · |
 Mr. Kevvy Mr. Kevvy Send message Joined: 15 May 99 Posts: 3776 Credit: 1,114,826,392 RAC: 3,319 
|
ID: 2033818 · |

©2024 University of California
SETI@home and Astropulse are funded by grants from the National Science Foundation, NASA, and donations from SETI@home volunteers. AstroPulse is funded in part by the NSF through grant AST-0307956.