The Server Issues / Outages Thread - Panic Mode On! (118)
Message boards :
Number crunching :
The Server Issues / Outages Thread - Panic Mode On! (118)
Message board moderation
Previous · 1 . . . 72 · 73 · 74 · 75 · 76 · 77 · 78 . . . 94 · Next
| Author | Message |
|---|---|
|
Ville Saari Send message Joined: 30 Nov 00 Posts: 1158 Credit: 49,177,052 RAC: 82,530 
|
Maybe it time to start to cut the timeline of the WUs and some changes in the way the work is distributed like sending the resends to the fastest hosts to clear them ASAP.Again NOT the fastest but the ones with the shortest average turnaround time. Slow host with a tiny cache can return the result faster than a fast host with a huge spoofed cache. One thing that could prevent this from happening again is if the system monitored the rate of overflows returned and when any file being split exceeds some threshold, that file would be heavily throttled so that it continues being split but would produce only a small percentage of all the workunits. Or this could even happen without any monitoring if the different splitters split different files instead of all bunching up on the same file. So if some file (or a few files) produced an overflow storm, the storm would be diluted by all the other splitters splitting clean files. But I don't know how this would affect the splitter performance. Spreading out could be faster or slower than bunching up. ID: 2030536 · |
juan BFP  Send message Joined: 16 Mar 07 Posts: 9786 Credit: 572,710,851 RAC: 3,799 
|
Again NOT the fastest but the ones with the shortest average turnaround time. Slow host with a tiny cache can return the result faster than a fast host with a huge spoofed cache. Sorry the meaning was lost in the translation. For me fastests host are the ones with the shortest average turnaround time (less than 1 day). They could clear the WU in very little time and help to reduce the DB size. Obviusly the WU must be sended with a very small death time line (less than 3 days in this case) . The way is done now, by sending the WU to any hosts (with a long death time line) just make the DB size problem even worst. 
ID: 2030560 · |
|
Speedy Send message Joined: 26 Jun 04 Posts: 1643 Credit: 12,921,799 RAC: 89 
|
I think BoincTasks can do that, as well. I agree. It would be good if boinc tasks or another piece of software could push short tasks to the front of the queue. Does anybody know of any software that does this? 
ID: 2030566 · |
|
Cruncher-American Send message Joined: 25 Mar 02 Posts: 1513 Credit: 370,893,186 RAC: 340 
|
Better solution: if you can detect short tasks without running them, why not just abort them? Can Boinc Tasks do this? Could the servers? ID: 2030584 · |
W-K 666  Send message Joined: 18 May 99 Posts: 19048 Credit: 40,757,560 RAC: 67 
|
Better solution: if you can detect short tasks without running them, why not just abort them? The only known way is to run them. For a short time, like the time taken on a 2060 GPU, or better, for bomb to be -9ed. We don't know how many tasks are sent/day but we do know how many are returned/hr. Average tasks returned per hr * 24 * short time on GPU / 86400 (s in day) = GPU's needed ID: 2030586 · |
 Tom M Tom M Send message Joined: 28 Nov 02 Posts: 5124 Credit: 276,046,078 RAC: 462 |
Sun 02 Feb 2020 06:16:57 PM CST | SETI@home | Scheduler request completed: got 92 new tasks Yum! Something to crunch ;) Tom A proud member of the OFA (Old Farts Association). ID: 2030593 · |
|
TBar Send message Joined: 22 May 99 Posts: 5204 Credit: 840,779,836 RAC: 2,768
|
Looks like more trouble. About 30 minutes ago the Website got very Slow and the Scheduler checked out; Mon Feb 3 01:08:50 2020 | SETI@home | [sched_op] Starting scheduler requestJust when everything was working well... ID: 2030611 · |
|
Grant (SSSF) Send message Joined: 19 Aug 99 Posts: 13731 Credit: 208,696,464 RAC: 304 
|
Well, of all the problems i was expecting to occur, the Scheduler going MIA wasn't one of them. And it appears it might have just come back to life- no longer timing out, or HTTP errors, or failure when receiving data from the peer (I think every possible error has been given at some stage). Now it's back to "Project has no tasks available", but at least i can report every thing that's accumulated since the Scheduler went AWOL earlier. Grant Darwin NT ID: 2030612 · |
|
Ville Saari Send message Joined: 30 Nov 00 Posts: 1158 Credit: 49,177,052 RAC: 82,530
|
Looks like the validators have been MIA too, not just the scheduler. The first successful scheduler contact made my RAC drop lower than the lowest point yesterday at the end of the dry period. ID: 2030615 · |
|
TBar Send message Joined: 22 May 99 Posts: 5204 Credit: 840,779,836 RAC: 2,768
|
A few machines are starting to get Downloads again. Hopefully this will blow over quickly. ID: 2030616 · |
|
Grant (SSSF) Send message Joined: 19 Aug 99 Posts: 13731 Credit: 208,696,464 RAC: 304
|
Looks like the validators have been MIA too, not just the scheduler. The first successful scheduler contact made my RAC drop lower than the lowest point yesterday at the end of the dry period.For a while there things were improving (steadily if slowly), but all the new work going out has caused the Validation backlog to increase again. Grant Darwin NT ID: 2030617 · |
|
Ville Saari Send message Joined: 30 Nov 00 Posts: 1158 Credit: 49,177,052 RAC: 82,530
|
For a while there things were improving (steadily if slowly), but all the new work going out has caused the Validation backlog to increase again.The assimilation backlog was reducing until two SSP updates ago. But on the last two updates it too has grown bigger. Here are the cumulative result counts for the last few days: 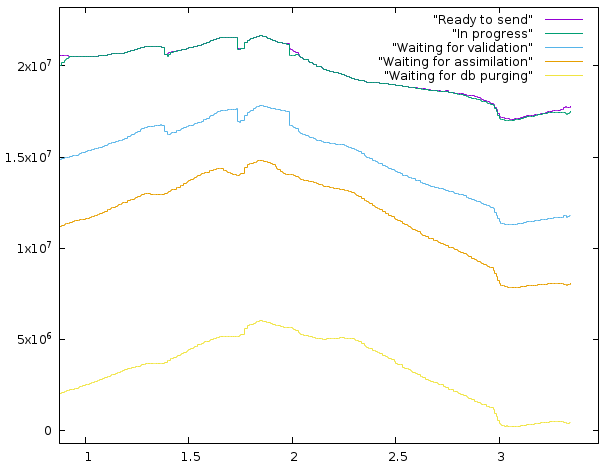 Each plotted value is the sum of that value plus all the values below it so that the width of the band between the line and the one below it represents the value of the specific variable. The plots show that db purging has been primarily responsible for the database size reduction and when the database ran out of purgeable results, the total result count started increasing again. The results waiting for assimilation are an estimated value because the SSP doesn't report it separately. The estimation is based on two assumptions: Those are counted as waiting for validation on ssp and the average replication (number of results per workunit) is 2.2. The numbers on x-axis are days of February. ID: 2030619 · |
|
Cruncher-American Send message Joined: 25 Mar 02 Posts: 1513 Credit: 370,893,186 RAC: 340
|
I agree. It would be good if boinc tasks or another piece of software could push short tasks to the front of the queue. Does anybody know of any software that does this? Then how could any other piece of s/w do this...just asking for a friend. ID: 2030627 · |
|
Richard Haselgrove Send message Joined: 4 Jul 99 Posts: 14650 Credit: 200,643,578 RAC: 874
|
Unfortunately, can't be done - consistently, at any rate.I agree. It would be good if boinc tasks or another piece of software could push short tasks to the front of the queue. Does anybody know of any software that does this?Then how could any other piece of s/w do this...just asking for a friend. That's what we're here for - finding the signals in the noise. The only way to do that is to run SETI's own software. There are occasions when a whole group of tasks are 'similar' - like the recent run of BLC35 tasks. But it wasn't 100%, and there were tasks in there that needed running. The best we can hope for is that the powers that be provide enough workers in the SETI@Home labs to manage the tape splitting process more closely, so that when one of these self-similar groups appears, they can respond by distributing them gradually, amongst other types of work. ID: 2030629 · |
|
Tom M Send message Joined: 28 Nov 02 Posts: 5124 Credit: 276,046,078 RAC: 462 |
I got up this morning and my Windows 10 box had shut down for some reason or other. When it does that I have to turn off the PSU before things will "reset" and then up it comes. Got this when everything was up again: 2/3/2020 5:51:36 AM | SETI@home | Scheduler request completed: got 150 new tasks Tom A proud member of the OFA (Old Farts Association). ID: 2030634 · |
|
BetelgeuseFive Send message Joined: 6 Jul 99 Posts: 158 Credit: 17,117,787 RAC: 19 
|
Unfortunately, can't be done - consistently, at any rate.I agree. It would be good if boinc tasks or another piece of software could push short tasks to the front of the queue. Does anybody know of any software that does this?Then how could any other piece of s/w do this...just asking for a friend. But it should be possible to move resends to the top of the queue (or at least it used to be when all tasks where sent out as pairs: anything with a _2 or higher should be resends). Tom ID: 2030636 · |
|
Retvari Zoltan Send message Joined: 28 Apr 00 Posts: 35 Credit: 128,746,856 RAC: 230 
|
My Inconclusive results are going up too, even though I've only had a handful of Tasks since last night. Last night I had a large number of Inconclusive results that said 'minimum quorum 1' and only listed a single Inconclusive host. I didn't see how a single Inconclusive host task could ever validate. Now, it's very difficult to bring up my Inconclusive tasks lists, but, it seems those tasks are now listed as; https://setiathome.berkeley.edu/workunit.php?wuid=3862758806I have a couple of invalid tasks with minimum quorum = 1. Perhaps I have a lot of valid tasks as well with min.q.=1, but they are much harder to spot. https://setiathome.berkeley.edu/workunit.php?wuid=3861384942 https://setiathome.berkeley.edu/workunit.php?wuid=3861339403 https://setiathome.berkeley.edu/workunit.php?wuid=3861247650 https://setiathome.berkeley.edu/workunit.php?wuid=3861247545 and so on... https://setiathome.berkeley.edu/results.php?userid=5276&offset=0&show_names=0&state=5&appid= ID: 2030638 · |
|
Ville Saari Send message Joined: 30 Nov 00 Posts: 1158 Credit: 49,177,052 RAC: 82,530
|
But it should be possible to move resends to the top of the queue (or at least it used to be when all tasks where sent out as pairs: anything with a _2 or higher should be resends).I don't think this is easy to do for an external tool. Except perhaps by modifying the deadlines of the tasks in client_state.xml to trick boinc into processing them in a hurry. If you modified the boinc client itself, then you could change the rules it uses to pick the next task to crunch to make it prioritize _2s and higher over _0 and _1. ID: 2030639 · |
|
juan BFP Send message Joined: 16 Mar 07 Posts: 9786 Credit: 572,710,851 RAC: 3,799
|
Or... Instead of modify the client itself, who is not recommended because the dev`s constantly release new updates on it, you could build an external app like the rescheduler. But instead of reschedulling WU from GPU<>CPU you could rearrange the FIFO order the WU are crunched. So they will be crunched in the order you choose, any order. Obviously until the panic mode is triggered by the client. The question could be: Why you need to do that? Keep your WU cache big enough to make your host crunching all the WU within a day and you will help to clear the DB fast.
ID: 2030640 · |
|
Ville Saari Send message Joined: 30 Nov 00 Posts: 1158 Credit: 49,177,052 RAC: 82,530
|
But instead of reschedulling WU from GPU<>CPU you could rearrange the FIFO order the WU are crunched. So they will be crunched in the order you choose, any order.Does the order in which the results are listed in client_state.xml count? There's no field for queue position, so if the physical order doesn't count, then the only way to do this would be faking the deadlines or receive times. Hacking the client would have the advantage that you wouldn't then need to periodically stop and restart the client to edit the client_state.xml. Every restart makes you lose on average 2.5 minutes of CPU progress and half a task of GPU progress. ID: 2030643 · |

©2024 University of California
SETI@home and Astropulse are funded by grants from the National Science Foundation, NASA, and donations from SETI@home volunteers. AstroPulse is funded in part by the NSF through grant AST-0307956.