GPU max 100wu Why?
Message boards :
Number crunching :
GPU max 100wu Why?
Message board moderation
Previous · 1 · 2
| Author | Message |
|---|---|
juan BFP  Send message Joined: 16 Mar 07 Posts: 9786 Credit: 572,710,851 RAC: 3,799 
|
Sure you not understand what i post as always (must be the translator who knows?), my propose is exactly the inverse, make ALL the users have a limit of 1 day cache only. Whatever their run. No exceptions. Like could be done today. Simply got to the statistics and look. But i'm talking about the time the host leaves after receive a WU and send back it crunched. Not the speed of the host. There are even a lot of powerful host (with a lot of cores & GPU's) who only crunch 2 or 3 WU /day due the way the user use them. 
ID: 1980079 · |
|
juan BFP Send message Joined: 16 Mar 07 Posts: 9786 Credit: 572,710,851 RAC: 3,799
|
My last MSG was truncated when the system goes down, there is the right one: So you propose a "special elite group" of crunchers to differentiate from "commoners"? Sure you not understand what i post as always (must be the translator who knows?), my propose is exactly the inverse, make ALL the users have a limit of 1 day cache only. Whatever their run. No exceptions. Like could be done today. Also, when was the last time you seen a single processor computer crunching 2-3 wu's a day? Simply got to the statistics and look. But i'm talking about the time the host leaves after receive a WU and send back it crunched. Not the speed of the host. There are even a lot of powerful host (with a lot of cores & GPU's) who only crunch 2 or 3 WU /day due the way the user use them.
ID: 1980083 · |
|
rob smith Send message Joined: 7 Mar 03 Posts: 22200 Credit: 416,307,556 RAC: 380 
|
That might not be a sensible solution for someone running a very slow device like a mobile phone or a raspberry Pi where a single task can take more than a day to complete.... Bob Smith Member of Seti PIPPS (Pluto is a Planet Protest Society) Somewhere in the (un)known Universe? ID: 1980099 · |
|
juan BFP Send message Joined: 16 Mar 07 Posts: 9786 Credit: 572,710,851 RAC: 3,799
|
That might not be a sensible solution for someone running a very slow device like a mobile phone or a raspberry Pi where a single task can take more than a day to complete.... That's why i post in my initial msg "something like the GPUGrid does..." For those who don't know. GPUGrid allow you to DL 1 WU at a time ONLY! (per thread of course). No matter how powerful is your host. After you crunch a big part of the WU (not sure but about 70%) then it allow you to DL the next WU So you always has around 1 WU to crunch (4-10 hrs in their case) Something similar could be easily done to care about the slower devices here. Just need to adjust the times. The main idea of my suggestion is to keep the DB size smaller as possible and keeping all host working on most of the outages (scheduled or no) who rarely pass the 1 day mark. What is not realistic is keep a timeout of more than a month when you have problems with the size of your DB. You need to do the inverse, try to flush the data as fast as possible. IMHO is that the main reason why the complains about the 100 WU limit. Bus as i post, it's a idea, suggestion, could be a path to follow, but needs a lot of polish. Something like minimum cache of 2 WU could solve the problem too.
ID: 1980113 · |
 TRuEQ & TuVaLu TRuEQ & TuVaLu Send message Joined: 4 Oct 99 Posts: 505 Credit: 69,523,653 RAC: 10 
|
Very intresting reading. Thank you all. If I'd know that it was this big issu with databas servers keeping track of very many(ALOT) of wu's was the problem. I guess I would have been silent. My suggestion to decrease the number of Wu's would be: For very fast GPU's : 10hour per wu Medium cards ; 1-2 hour per wu Slow cards : 30 mins per wu I guess there is problems here with my suggestion regarding cpu use and similiar size for wu. But my suggestion would maybe solve 1 bottleneck a little. And make the wu's bigger. The size doesn't really matter as they say *haha*. I guess this will also be a problem for servera that create the wu's. OpenCl Programming for fast GPU's might work for the creation of very large wu's somewhat faster. As of now I leave it up to the guys that needs 900 000 USD to see if my suggestions are of any use. Oh, and I will tell my mom that I can't make the setting 100 to 200 because SETI lacks 900K $ *And it is true. She asked me that today of FB and she has a win 10 with a NVIDIA 1060 //TRuEQ out ID: 1980114 · |
|
Brent Norman Send message Joined: 1 Dec 99 Posts: 2786 Credit: 685,657,289 RAC: 835 
|
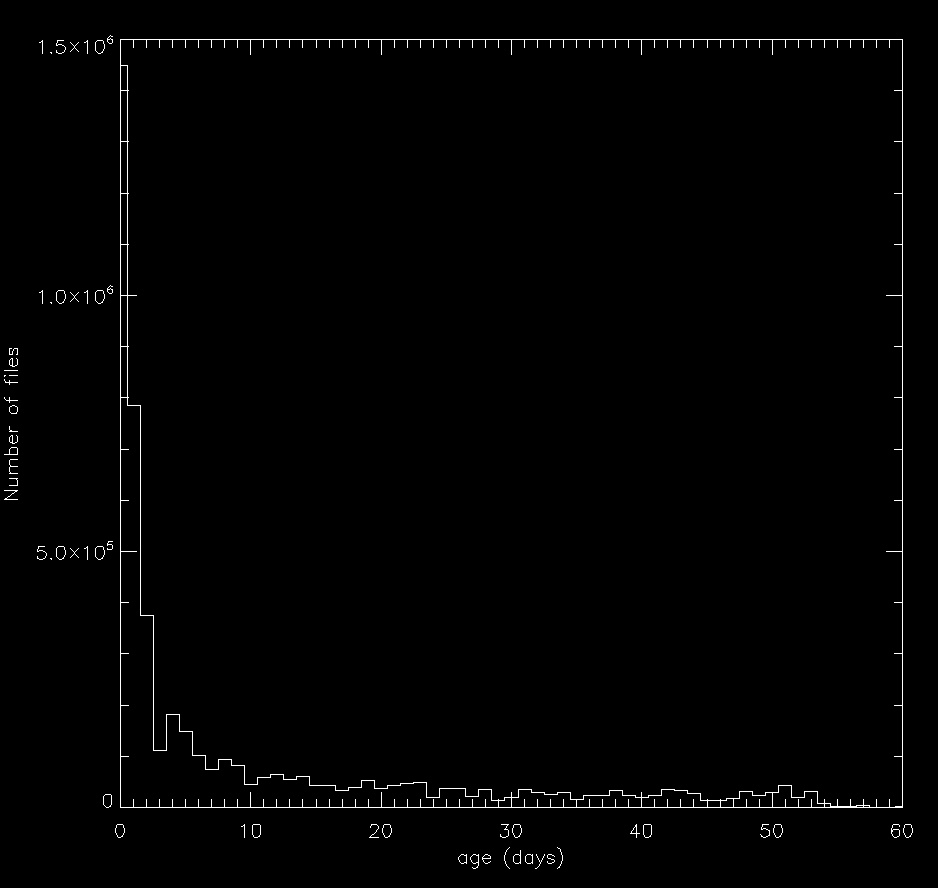
Size does matter, so they say. Each WU is 100s of data, with 7s of overlap. Sure they could likely make that 300s fairly easily, but the apps we use have a 30 signal overflow scheme built into them - so every single app would have to be rewritten to detect the recording length and adjust accordingly. Then there is the problem that the 'best' signals found in 300s rather than 100s would be different, and inconsistent with previous data for comparison. That would be a total mess to have to deal with in scientific terms when your data is not consistent. Eric has stood fast on deadlines, cache sizes, and device limits - I would say bull headed, LOL. we don't live in a world now where 56k modems we high-end communication anymore. Sure a few will have that, but a very few. And rarely connected devices are now daily connected in most cases. As for processing power, that has been exponential. I do see a problem with 1 day limit for phones, etc (which I believe they are pushing to get more online because of popularity now over desktops) in that they could be just about ready to report before a outage, in that they would run dry. so make that 2 days. But there certainly should be something done for faster computers, which are also common place and do a lot of their processing! The deadlines are absolutely ridiculous being 6 weeks for most. I just looked at my newest tasks and they are 53 days to deadline. Good grief! Eric posted a graph of tasks files on the server which does show that a large number of tasks are returned in the 20-60 day range, but I find it hard to believe that computers that returned these wouldn't have newer tasks onboard that would run if these timed out on them - that's a firm indicator to me that their cache size is a WAY too BIG for their system and usage. For kicks I looked at the age of files in the workunit storage (based upon a sample of 0.1%). 
ID: 1980120 · |
|
Tom M Send message Joined: 28 Nov 02 Posts: 5124 Credit: 276,046,078 RAC: 462 |
If the 6 week time out parameter is a data file issue rather than a re-compile the code issue it would seem that slowly stepping the deadline date/time down while watching to see how many "time outs" are reported would be a worthy experiment. As long as the "time outs" didn't surge you could keep dropping the deadline until you see a "surge" then back off a day or two. Its not like the data gets lost when a deadline expires and it might speed up the overall production without inconveniencing our average systems (yes I have one or more of those). Tom A proud member of the OFA (Old Farts Association). ID: 1980144 · |
|
Tom M Send message Joined: 28 Nov 02 Posts: 5124 Credit: 276,046,078 RAC: 462 |
So 1 day of work and 0.1 day additional work are pretty good settings across the board? A proud member of the OFA (Old Farts Association). ID: 1980145 · |
Unixchick  Send message Joined: 5 Mar 12 Posts: 815 Credit: 2,361,516 RAC: 22 
|
I'm enjoying this discussion. I'm running just one "average" system (15-20 WUs in a day). The 100 WU limit is way more than I need. I tend to only request WUs when the system is running well, and the RTS queue is full. While the ultimate goal is to find the signal... there is also something to be said for involving as many people as possible. I love being a part of this community even though I know my contribution is minor. The more PR/education that is done and the more people that feel like they are a part of a science project has to also have some value. As someone who is part of the space community I often have relatives saying that the space budget for US should be scrapped and spent to feed people. We need to get more people feeling a part of the "science" participate so they can catch a clue. I like a lot of the ideas posted here, and it has made me think about how many WUs I take at a time. I was only thinking about my impact on the RTS queue not on db size. ID: 1980148 · |
|
Brent Norman Send message Joined: 1 Dec 99 Posts: 2786 Credit: 685,657,289 RAC: 835
|
We also have to remember that the average user makes up a large portion of those 93,895 active users. I would hamper a guess at the bottom 92,000 doing the same amount of work as the top 1895 users - there is strength in numbers. It would be really interesting to see where the 50/50 cut off point actually lies there. All those 'little' device and a hour a day users add up. So size doesn't always matter, but sometimes you can use the help of some friends to go the same distance.  :D
ID: 1980164 · |
|
Brent Norman Send message Joined: 1 Dec 99 Posts: 2786 Credit: 685,657,289 RAC: 835
|
I was thinking about those tasks that get returned in 15-60 days. These are likely mostly made up of multi-project users. Not intermittent users. For instance Einstein has shorter deadlines and like to really swamp users with an overabundance of tasks, this puts Seti tasks on the back burner until BOINC says they are nearing the deadline and puts them in High Priority mode to run them. In that case shorter deadlines would help clear the backlog and keep the tasks moving along. That 53 day deadline for MB tasks is way too high. heck the AP tasks are 24 days and take much longer to run. 53 days is like 10d cache, 10d extra, and 33d to process. On a 286 maybe, but we don't even have apps that will run on a 286 now. LOL
ID: 1980167 · |
|
Dr Grey Send message Joined: 27 May 99 Posts: 154 Credit: 104,147,344 RAC: 21
|
I took a look at the contribution of the top 20 hosts to the overall RAC according to Boincstats. While the top 20 hosts represent a little over 0.01 % of the total number of active users, when you tot up their combined RACs they are actually contributing to almost exactly 3 % of the total Seti@home RAC. ID: 1980179 · |
|
juan BFP Send message Joined: 16 Mar 07 Posts: 9786 Credit: 572,710,851 RAC: 3,799
|
Not forget, i`m no talking only about the top 20 hosts, i`m talking about all the users who has high capacity GPUs/CPUs. Is not dificult to imagine how much processing power is lost (not used by SETI at least) during the outages due the 100 WU limit. Add that to the multiproject hosts who switch to other project during the outages and takes time to return to the SETIverse. Sure is significative. My bet is even more than the combined output of the top 20 hosts. If you set the cache size to 1 day (or 2 as suggested) and that produces a decrease of 10 WU on each host times 93K users aroximately is close to 10% of the DB size. Now redo the math with a 10/20 WU / day host who has now 100 WU or more on his cache, as somebody post in the thread. Please correct me if i`m wrong but i`m sure a 10/20 day host could live with a cache of 20/40 WU since it will never run out of WU due the outages. A gain of 20% in the DB size will make the servers very happy i presume. But that is for now, by doing that we gain some time with the actual servers capacity. As posted by someone in the thread, sooner or later the avaiable computing capacity of the users will pass the capacity of the servers. So new fast servers and more eficient DB manager will be needed.
ID: 1980187 · |
|
rob smith Send message Joined: 7 Mar 03 Posts: 22200 Credit: 416,307,556 RAC: 380
|
It is not the disk space on the servers that is the issue, it is the rate at which they can process each query, and the number of queries required to satiafy each user request that is the bottleneck. We saw what happened last week when there was a loss of 15% in the capability to distribute work - the other servers went on a go-slow This is symptomatic of a system that has either been tightly tuned for its current workload or one that is running on the ragged edge. Changing to some sort of "fair" task distribution where would increase the complexity of the user request, so increase the number of queries per transaction, and slow down the whole process thus increase the crash potential. If those who have been here a fair time care to think back to the days when it was a free-for-all in the task stakes they will recall that we had some really spectacular server crashes which damaged the data - never mind cost a few crunchers a few hours of processing a week. And also should remember that the project has NEVER guaranteed us enough tasks to crunch 24/7. Bob Smith Member of Seti PIPPS (Pluto is a Planet Protest Society) Somewhere in the (un)known Universe? ID: 1980249 · |

©2024 University of California
SETI@home and Astropulse are funded by grants from the National Science Foundation, NASA, and donations from SETI@home volunteers. AstroPulse is funded in part by the NSF through grant AST-0307956.