Slow server for the next 8 hours or so...
Message boards :
News :
Slow server for the next 8 hours or so...
Message board moderation
| Author | Message |
|---|---|
Eric Korpela   Send message Joined: 3 Apr 99 Posts: 1382 Credit: 54,506,847 RAC: 60 
|
GeorgeM, the machine that holds the data that you download, decided that it was time to verify that the RAID array is in good shape. That will slow down disk access until the verify procedure is complete. The main effect is slowing down the rate at which work can be created. It's likely that we'll run out of work in the next hour or so. Things should recover automatically when it's done. @SETIEric@qoto.org (Mastodon) 
ID: 1977747 · |
rob smith  Send message Joined: 7 Mar 03 Posts: 22199 Credit: 416,307,556 RAC: 380 
|
Machines will do what machines will do..... Thanks for the heads-up Eric. Bob Smith Member of Seti PIPPS (Pluto is a Planet Protest Society) Somewhere in the (un)known Universe? ID: 1977769 · |
 Brent Norman Brent Norman Send message Joined: 1 Dec 99 Posts: 2786 Credit: 685,657,289 RAC: 835 
|
Thanks for the heads up Eric. It's a good thing to have a healthy RAID :) Things seem to be slowly catching up, but I'm sure those drives are mighty busy. 
ID: 1977793 · |
|
Speedy Send message Joined: 26 Jun 04 Posts: 1643 Credit: 12,921,799 RAC: 89 
|
Thanks Eric for the news. Out of interest are big is the storage capacity in George M? 
ID: 1977936 · |
|
TomnLiz Send message Joined: 15 Oct 02 Posts: 4 Credit: 952,982 RAC: 1
|
Could this be the reason I've seen a huge drop in my user average the past few days? ID: 1978079 · |
|
rob smith Send message Joined: 7 Mar 03 Posts: 22199 Credit: 416,307,556 RAC: 380
|
No - this was a transient that only lasted a few hours. Bob Smith Member of Seti PIPPS (Pluto is a Planet Protest Society) Somewhere in the (un)known Universe? ID: 1978081 · |
|
Eric Korpela Send message Joined: 3 Apr 99 Posts: 1382 Credit: 54,506,847 RAC: 60
|
Thanks Eric for the news. Out of interest are big is the storage capacity in George M? Not huge. Two RAID-10 arrays each with 10x2TB drives. So about 20TB usable. @SETIEric@qoto.org (Mastodon)
ID: 1978176 · |
|
Speedy Send message Joined: 26 Jun 04 Posts: 1643 Credit: 12,921,799 RAC: 89
|
Thanks Eric for the news. Out of interest are big is the storage capacity in George M? Thanks for the information Eric. If these are the discs that we downloaded the work from. How can the download storage hold upwards of 700,000 work units (when the splitters are working at performance) according to the SSP if storage capacity is only 20 TB? I estimate somewhere around about 28,000 work units working on one new unit being about 703 kB. On the other hand I may have completely misunderstood the following comment "GeorgeM, the machine that holds the data that you download"
ID: 1978186 · |
|
Eric Korpela Send message Joined: 3 Apr 99 Posts: 1382 Credit: 54,506,847 RAC: 60
|
I think your math is off a bit. 700,000 * 710 kB = 496 GB It's actually quite a bit more than that because the residence time of workunits is at least a day and we're pushing through about 1.25M per day these days. But's still less than 1TB. In practice we use one 10x2TB RAID-10 for the data coming from Arecibo, and temporary storage of database backups, some other data sets that have low access demands. We use the other 10x2TB for outgoing workunits and little else because we want the full I/O capacity of the drives to handle the workunit transfers. If we moved to another system I'd probably want a triple mirrored set of 15 drives, or a move to SSD. Given that the space keeps getting rewritten, SSDs might not have a long enough lifetime. @SETIEric@qoto.org (Mastodon)
ID: 1978200 · |
|
Brent Norman Send message Joined: 1 Dec 99 Posts: 2786 Credit: 685,657,289 RAC: 835
|
Hi Eric, I'm curious what storage media you use for the raw data. Well that's probably a mix from over the years. To have that amount of data on hand must take up quite a lot of physical space to. And likely climate controlled for safety as well.
ID: 1978204 · |
|
Eric Korpela Send message Joined: 3 Apr 99 Posts: 1382 Credit: 54,506,847 RAC: 60
|
Definitely climate controlled. We have several rack in the UC Data Center. The workunit storage array is an external SuperMicro SAS box attached to georgem. We try to keep our arrays to a single manufacturer. The georgem arrays are Seagate, a combination of ST2000DM001 and ST2000DM009. For older Hitachi/HGST arrays it's getting difficult to find drives with 512 byte sectors, so those arrays will probably to mixed manufacturer at some point. For kicks I looked at the age of files in the workunit storage (based upon a sample of 0.1%). 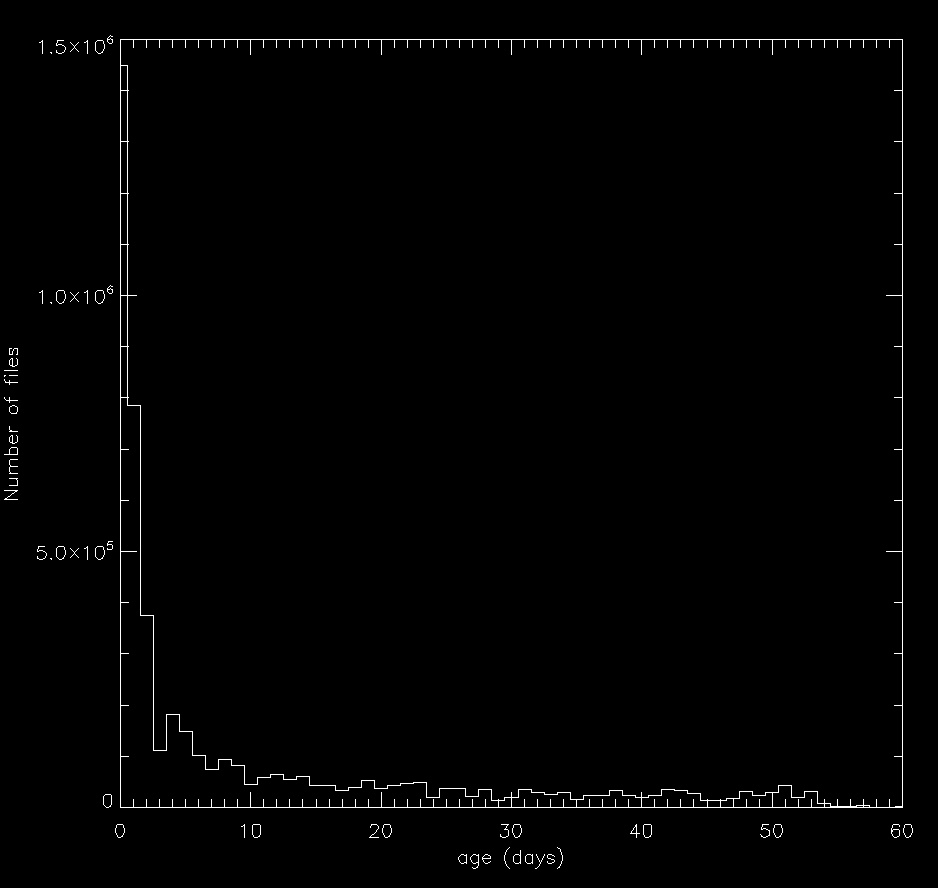 As you can see, half our files get deleted within a couple days, but some hang out for up to 60. @SETIEric@qoto.org (Mastodon)
ID: 1978208 · |
|
Speedy Send message Joined: 26 Jun 04 Posts: 1643 Credit: 12,921,799 RAC: 89
|
Yes my maths was off by a long way. Thanks Eric for pointing that out in the information provided. This however raises another question. The tasks we download are they transferred from the 496 GB of storage you refer to in my example to the 10×2 TB storage avery?
ID: 1978214 · |
|
Brent Norman Send message Joined: 1 Dec 99 Posts: 2786 Credit: 685,657,289 RAC: 835
|
Thanks for the Tasks details. It is interesting to see that a client cache size of greater than 2-3 days (EDIT: And lengthy deadlines) accounts for half the task storage and active database tracking for them. I was actually referring to the raw antenna media data prior to splitting from which you retrieve the old data from. What is this stored on? There must be a lot of it.
ID: 1978217 · |
|
Grant (SSSF) Send message Joined: 19 Aug 99 Posts: 13736 Credit: 208,696,464 RAC: 304 
|
If we moved to another system I'd probably want a triple mirrored set of 15 drives, or a move to SSD. Given that the space keeps getting rewritten, SSDs might not have a long enough lifetime. Enterprise SSDs for high write levels are generally rated at a minimum of 3 DWPD (Drive Writes Per Day) for 5 years- ie you can write data to the same value as the capacity of the drive, 3 times every single day, for 5 years. For some drives it's as many as 5 DWPD. They also often come with software that allows you to adjust the drive's provisioning, further increasing the number of writes possible before failure is likely to occur (and also increasing random write performance). From WD- The SSD Endurance Cheat Sheet (right down near the bottom of the page). Use Case Description Approx. DWPD Virtualization and Containers. Tier-0 storage for containers and VMs in a hyperconverged system. SSDs provide all local storage for the cluster. 1.0 ~ 3.0 OLTP Database Data intensive workloads. Frequent updates to database logs and data files, often thousands of times per second. 3.0+ High Performance Caching (Accelerate local hard drives). Some of the highest write workloads possible. 3.0++ Grant Darwin NT ID: 1978222 · |

©2024 University of California
SETI@home and Astropulse are funded by grants from the National Science Foundation, NASA, and donations from SETI@home volunteers. AstroPulse is funded in part by the NSF through grant AST-0307956.