OpenCL NV MultiBeam v8 SoG edition for Windows
Message boards :
Number crunching :
OpenCL NV MultiBeam v8 SoG edition for Windows
Message board moderation
Previous · 1 · 2 · 3 · 4 · 5 . . . 18 · Next
| Author | Message |
|---|---|
 Raistmer Raistmer Send message Joined: 16 Jun 01 Posts: 6325 Credit: 106,370,077 RAC: 121 
|
Also would be interesting to check how it responds to -cpu_lock. OpenCL NV quite uncharted area and what we know on ATi side not always directly applicable here. ID: 1762691 · |
|
Raistmer Send message Joined: 16 Jun 01 Posts: 6325 Credit: 106,370,077 RAC: 121
|
Also would be interesting to check how it responds to -cpu_lock. Just as part of app parameter space exploration, later, when you establish some baseline impression how it behaves on different ARs. Baseline required to have smth to compare with. Then such things like -use_sleep and/or -cpu_lock and -sbs N variations can be tested. ID: 1762695 · |
|
Zalster Send message Joined: 27 May 99 Posts: 5517 Credit: 528,817,460 RAC: 242 
|
Definitely using a lot more CPU than Beta, also seems to be taking longer to process. ID: 1762729 · |
|
Zalster Send message Joined: 27 May 99 Posts: 5517 Credit: 528,817,460 RAC: 242
|
Well, had a chance to look at some of these processed. They are now slower than Cuda here on main. Also seeing unusually high kernal usage. Within the last 20% of the analysis, kernal activity spikes, all CPUs go to 100%. I had been using a command line but removed it when it appears to be actually hampering the work, so now it's just running stock 3 at a time. ID: 1762742 · |
|
Raistmer Send message Joined: 16 Jun 01 Posts: 6325 Credit: 106,370,077 RAC: 121
|
Well, had a chance to look at some of these processed. They are now slower than Cuda here on main. Also seeing unusually high kernal usage. Within the last 20% of the analysis, kernal activity spikes, all CPUs go to 100%. I had been using a command line but removed it when it appears to be actually hampering the work, so now it's just running stock 3 at a time. Could you provide links to comparison pairs, please. ID: 1762793 · |
|
tullio Send message Joined: 9 Apr 04 Posts: 8797 Credit: 2,930,782 RAC: 1 
|
I have installed a Geforce GTX 750 on my Windows 10 PC, reinstalled the Lunatics package and is now crunching SETI@home tasks. In the stderr.txt I see that the nVidia driver is 353.54. Is this OK? I did nothing to install drivers, Windows 10 did all the work. Tullio ID: 1762873 · |
|
Bill G Send message Joined: 1 Jun 01 Posts: 1282 Credit: 187,688,550 RAC: 182
|
That driver should be fine. It is working here. (as are even later drivers on some of my computers)  SETI@home classic workunits 4,019 SETI@home classic CPU time 34,348 hours ID: 1762893 · |
|
Zalster Send message Joined: 27 May 99 Posts: 5517 Credit: 528,817,460 RAC: 242
|
Tut is right, it appears it likes higher AR. Lower AR tend to run slower. These are the closest one I could find These had 3 MBs at a time, CPU usage 89-100%. Screen lag, flickering, I couldn't go beyond 3 at a time due to lock ups and freezes http://setiathome.berkeley.edu/result.php?resultid=4706466613 ar= 0.42 http://setiathome.berkeley.edu/result.php?resultid=4706466462 ar= 0.42 I did not use the command -use_sleep on those above These work units are run with Cuda 50 higher number of instances per card, CPU usage was much lower, no lag, no lock ups http://setiathome.berkeley.edu/result.php?resultid=4705817746 ar=0.41 http://setiathome.berkeley.edu/result.php?resultid=4705223266 ar=0.40 Going to have to stop testing for now as I'm leaving the systems by themselves for a few days. ID: 1762924 · |
|
Raistmer Send message Joined: 16 Jun 01 Posts: 6325 Credit: 106,370,077 RAC: 121
|
I have installed a Geforce GTX 750 on my Windows 10 PC, reinstalled the Lunatics package and is now crunching SETI@home tasks. In the stderr.txt I see that the nVidia driver is 353.54. Is this OK? I did nothing to install drivers, Windows 10 did all the work. It's known that drivers provided via M$ OS update mechanism are different from drivers provided by GPU vendor site. Usualy they differ to worse. They can work OK but not always. Besides that 353 is OK for OpenCL NV. ID: 1762929 · |
|
Raistmer Send message Joined: 16 Jun 01 Posts: 6325 Credit: 106,370,077 RAC: 121
|
Number of app instances per device set to:2 So how many app instances BOINC actually launched?
"higher" is how many? 3, 4 ? What if number will be equal (as most natural way for comparison that doesn't require any additional calculation to extract real host throughput from task times) ? Sorry, but w/o definitive number of simultaneous instances for both runs comparison impossible. EDIT: OMG do you really provide overflow task as comparison one ??? Preemptively acknowledging a safe Exit. -> Pity you should stop, would be interesting to get adequate data from your GPUs. Seems second dot is non-overflow so could be used (after info how many instances were per GPU): http://setiathome.berkeley.edu/result.php?resultid=4705223266 WU true angle range is : 0.40154 Ð’Ñ€ÐµÐ¼Ñ Ð²Ñ‹Ð¿Ð¾Ð»Ð½ÐµÐ½Ð¸Ñ 23 мин. 57 Ñек. Ð’Ñ€ÐµÐ¼Ñ Ð¦ÐŸ 5 мин. 59 Ñек. and http://setiathome.berkeley.edu/result.php?resultid=4706466462 WU true angle range is : 0.421824 Ð’Ñ€ÐµÐ¼Ñ Ð²Ñ‹Ð¿Ð¾Ð»Ð½ÐµÐ½Ð¸Ñ 21 мин. 32 Ñек. Ð’Ñ€ÐµÐ¼Ñ Ð¦ÐŸ 11 мин. 56 Ñек. http://setiathome.berkeley.edu/result.php?resultid=4706466613 WU true angle range is : 0.421824 Ð’Ñ€ÐµÐ¼Ñ Ð²Ñ‹Ð¿Ð¾Ð»Ð½ÐµÐ½Ð¸Ñ 21 мин. 54 Ñек. Ð’Ñ€ÐµÐ¼Ñ Ð¦ÐŸ 9 мин. 33 Ñек. Regarding freezes - well, that's quite developed tuning abilities for. What if you would run w/o custom cmd string? What if custom cmd string will be changed to reduce lags (that is, not decrease as you did but increase number of iterations in -period_iterations_num N )?... EDIT2: and from PM: The opencl were 3 per card, even though it say 2 in the stderr. I use a app_config to change the number Cause CPU affinity adjustment disabledthe wrong number of instances provided to app is harmless. Then we have throughput of 5/(23*60+57)=0.00348 tasks/s vs 3*2/(21*2*60+32+54)=0.00230 tasks/s for midrange AR area for GTX 980Ti GPU. OpenCL is quite slower in this comparison. Will be interesting to see more case studies. And meantime I'll try to find drivers that capable to build SoG path for pre-FERMI GPUs to be able to do some tests by myself too. ID: 1762930 · |
|
Raistmer Send message Joined: 16 Jun 01 Posts: 6325 Credit: 106,370,077 RAC: 121
|
Well, this number provided to Sleep() call and means number of milliseconds for that thread going to sleep. I would not recommend to use -use_sleep_ex N in production w/o variation of N first to find sweet spot. From other side -use_sleep uses Sleep(1) call so should be equal to -use_sleep_ex 1. Both do as many iterations as required to really complete kernel. Why these 2 options and not just one: 1) Let suppose real time to complete processing is 6ms. Doing it with -use_sleep app will make 6 sleep iterations of 1ms long. From other side, doing it with -use_sleep_ex 5 app will make 2 iterations 5ms each so spend 10ms (!) in sleep. 2) Let suppose real time is 600ms. Properly tuned "ex" could reduce number of iterations (and hence CPU overhead) considerably. 3) Unfortunately, it's simplified picture cause under Windows app will not sleep 5ms or 1ms even if told to do that. Real time will be very different, I spent much time studying that. So, though app has ability (-v 6) to show how many iterations particular wait did it's impossible just to make run with -use_sleep -v 6, and then set -use_sleep_ex N to that number of iterations from stderr. Experimentation required with N number. And last remark: would be interesting to see how -use_sleep_ex 0 behaves with high-performance GPU. Quite possible that just yelding control w/o any sleep time will be enough to reduce CPU usage w/o too much GPU slowdown. ID: 1762943 · |
|
tullio Send message Joined: 9 Apr 04 Posts: 8797 Credit: 2,930,782 RAC: 1
|
I downloaded 20 SETI@home tasks and they are being processed in one-two hours on my Windows 10 PC. I still have a CD provided by nVidia but probably it is older by now (I bought the board probably in 2014). So I am satisfied for the time. I have another board, a Sapphire HD 7770 and I shall try to install it on my main Linux box, a SUN M20 workstation vintage 2008 but still running with SuSE Linux 13.1. Thanks. Tullio ID: 1762945 · |
|
Raistmer Send message Joined: 16 Jun 01 Posts: 6325 Credit: 106,370,077 RAC: 121
|
Aha, good to know, thanks. Then it seems no other way but to leave -use_sleep enabled (or even disable it and leave high CPU usage) and increase size of kernels where possible: 1) try -period_iterations_num 1 (instead of default 50 ) 2) try -sbs 256 3) try increased number of simultaneous tasks (maybe even more than 4)
Yes, it has explanation accordingly types of search app does for tasks with different ARs. ID: 1762977 · |
Richard Haselgrove  Send message Joined: 4 Jul 99 Posts: 14650 Credit: 200,643,578 RAC: 874 
|
I'm breaking in a new machine, so I thought I'd try a direct comparison between the various NVidia applications. Machine is an i5 running under Windows 7, with a GTX 970 and driver 350.12 For the purposes of this first test, I simulated a loaded GPU by running a GPUGrid task continuously under BOINC, and let each SETI MB application in turn fight for its own share of GPU resources at default settings only. The CPU was unloaded, except for whatever support the running application claimed (and basic OS functions, of course). I used the Lunatics 'FG' set of full-length test tasks, adapted to run in v8 mode. Raw timings: AR cuda50 OpenCL_r3330 OpenCL_r3366_SoG Elapsed CPU Elapsed CPU Elapsed CPU 0.0091 4651.00 246.06 2095.70 2084.42 1940.44 1930.00 0.0134 4629.99 242.27 2072.96 2047.69 1919.05 1897.58 0.1307 2801.69 230.57 1464.58 1453.90 1311.01 1303.47 0.2968 2890.48 268.77 1345.67 1336.20 923.63 916.51 0.3853 2393.70 260.41 1096.38 1087.64 753.14 746.51 0.4160 2389.04 226.48 1021.21 1004.38 697.12 690.13 0.4221 2166.88 185.80 1150.63 1141.16 693.66 685.56 0.4317 2133.83 182.37 1137.48 1126.06 684.62 677.58 0.4465 2051.34 216.92 1112.27 1095.58 664.75 657.97 0.9362 1731.48 184.67 796.82 782.78 508.08 255.70 1.1753 1483.10 167.59 580.77 573.34 424.70 70.82 1.3462 1564.06 135.69 574.19 567.10 419.38 62.03 2.4857 1538.77 137.48 568.31 557.49 412.00 27.58 5.3024 1536.54 136.39 561.60 553.69 408.66 12.59 7.6516 1546.13 135.83 559.68 553.12 408.16 11.29 and in graphical form: 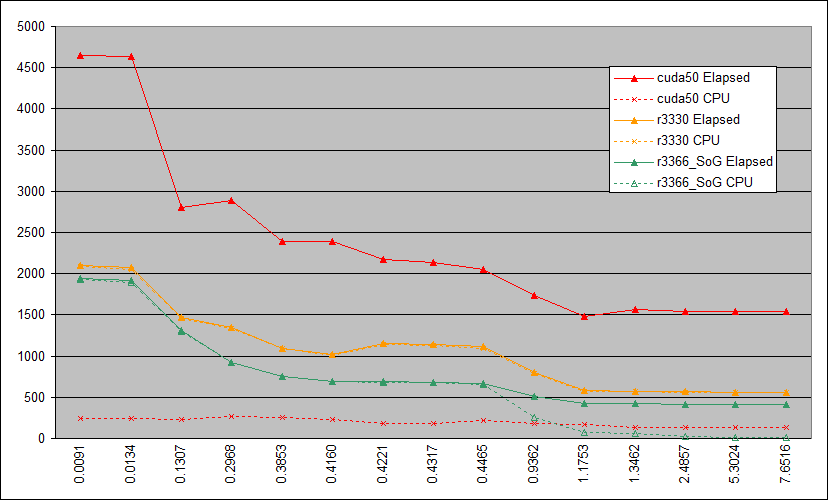 Note that I don't think that anybody in the BOINCverse has done any serious study of the dynamics of running two different application technologies on the same device at the same time. There's some anecdotal stuff about the effects of running 2xMB, 2xAP, or AP+MB together (usually without reference to the AR of the MB), and some stuff about running SETI + Einstein on the same card, but that's about it. For information, the GPUGrid task I loaded the card with uses Cuda65 technology. When the current GPUGrid task has finished, I'll repeat the run without extra GPU loading (so just the single MB task running) - watch this space. ID: 1763118 · |
|
Raistmer Send message Joined: 16 Jun 01 Posts: 6325 Credit: 106,370,077 RAC: 121
|
Interesting data indeed though not too close to real production runs we do with these apps. Many use only SETI project when it has work and for others BOINC itself tends to pair tasks from same project. That's why MB+MB or AP+MB and AP+AP most popular combos here. Also, running different apps together adds another uncertainty to results: 1) process priority 2) size of GPU kernels. With 1) it's apparent that if CPU priorities differ it will create unequal conditions in GPU feeding. So result will not reflect relative performance but just relative CPU processes priority (and there are more easy ways to check those priorities ;) ) Second case is more difficult. There is no such thing as GPU preemptive scheduling still AFAIK. That means, once kernel will scheduled to run on GPU it will run until finish. Now imagine (for simplicity) strongly equal kernels of let say 100ms in background app (GPUgrid) and kernels of different size of apps you testing on that background (it's important here that background differs from app in testing). Also let suppose CPU priorities equal and kernels scheduled just in roundrobin manner. So with smaller kernel it wil be (B - background; s-small kernel; L-large kernel). BBBsBBBsBBBs (considering BBB is one bakground kernel and s-small kernel from another app). and with large kernels it will be: BBBLLLLLBBBLLLLL In first case relative share of background will be bigger so apparent speed of app in testing will be slower and in second case just reverse. Again, it says little about relative speed of 2 apps but more about relative kernel sizes of background app and app paired with it. Possible kernels overlapping just make picture even more complicated. That's why there is more info in MB+MB runs than in mixed runs. With mixed runs one should estimate overall host performance (background app included!) and then use some inter-project "currency" for performance measurements like cobblestones... and we all know how screwed they are... P.S. just compare this graph with what said before about AR dependence of SoG app. Most speedup in live runs was in VHAR area so far. And this completely in agreement of processing algorithm implementation in SoG. But here midrange and VHAR for nonSoG and SoG looks very similar [actually I would say even they show reversed picture - changes in nonSoG bigger!]. CPU time decline vastly, but elapsed doesn't show this. P.P.S. So, summarizing, I think it's hard to interpret such data. And care in any possible interpretation required to take into account listed things and perhaps some other. ID: 1763125 · |
|
jason_gee Send message Joined: 24 Nov 06 Posts: 7489 Credit: 91,093,184 RAC: 0 
|
Cuda app certainly won't be 'fighting' for anything unless you tell it to :) "Living by the wisdom of computer science doesn't sound so bad after all. And unlike most advice, it's backed up by proofs." -- Algorithms to live by: The computer science of human decisions. ID: 1763127 · |
|
Richard Haselgrove Send message Joined: 4 Jul 99 Posts: 14650 Credit: 200,643,578 RAC: 874
|
Interesting data indeed though not too close to real production runs we do with these apps. Sure, and I wouldn't pretend otherwise. I just thought it might be interesting - while I had a largely spare machine available - to experiment with alternative ways of presenting test data. I chose GPUGrid as my backfill load simply because I wanted to run realistic length tasks, and I wanted something that wouldn't keep stopping and starting during the ~18 hours that test was running. There was a single task replacement round about AR=0.4221 (and not all GPUGrid tasks use the GPU to the same extent), but I don't think that invalidates the run any more than the other issues you mention. The second run has started, and it will be interesting to see what changes pop up. In a way, having one tiny little MB task rattling around in the vast empty spaces of a 4 GB GTX 970 is even more unrepresentative of the way BOINCers drive their machines in the real world, but I thought the alternative viewpoint might be of interest to users and developers alike. ID: 1763130 · |
|
Richard Haselgrove Send message Joined: 4 Jul 99 Posts: 14650 Credit: 200,643,578 RAC: 874
|
Here are the NV card results for the 'unloaded' case - exactly the same host and procedure as in the previous post, but without the GPUGrid task to slow things down. Raw timings: AR cuda50 OpenCL_r3330 OpenCL_r3366_SoG Elapsed CPU Elapsed CPU Elapsed CPU 0.0091 2601.92 132.09 1333.55 1325.46 1309.81 1296.31 0.0134 2541.68 129.79 1308.30 1293.61 1282.73 1271.53 0.1307 945.99 133.55 971.08 960.48 946.56 940.17 0.2968 693.76 149.26 689.93 680.60 624.47 618.50 0.3853 528.65 119.39 539.39 533.04 487.25 482.18 0.4160 530.50 132.35 498.12 492.03 447.99 442.86 0.4221 527.00 127.92 493.38 480.59 443.54 438.00 0.4317 493.71 111.59 486.90 480.67 436.60 430.55 0.4465 510.25 127.02 470.21 462.08 421.81 415.99 0.9362 397.77 104.68 342.14 331.89 313.03 159.36 1.1753 286.73 78.89 262.39 256.33 252.75 43.70 1.3462 312.95 90.11 257.17 251.19 247.95 37.27 2.4857 305.37 87.97 251.64 245.31 242.61 17.25 5.3024 317.52 84.88 249.93 243.13 241.10 8.83 7.6516 312.20 89.72 249.46 242.97 240.97 8.05 and as a graph. I've deliberately left the scaling the same as the previous graph, to emphasise the difference GPU loading makes. 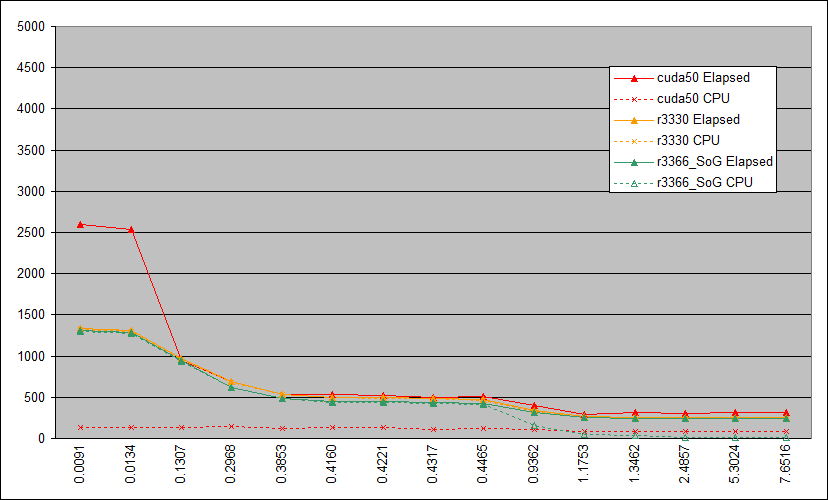 ID: 1763290 · |
|
jason_gee Send message Joined: 24 Nov 06 Posts: 7489 Credit: 91,093,184 RAC: 0
|
Assuming these are offline runs, can you run with the -poll command line option on the Cuda50 application ? effect should be full CPU core use (similar to the OpenCL mid-Low ARs) and faster elapsed. if noticably faster, and if CPU core Use is acceptable for some people/situations (though probably case specific), I would consider enabling the feature as an option through mbcuda.cfg Another thing to consider with the Cuda50 build on Later GPUss, specifically with the VLAR timing, is default pulsefind settings are set fairly gentle. Could be worth upping pfblockspersm to 15, and pfperiodsperlaunch to 200, which would be more aggressive settings than suitable as defaults. [ process priority may need similar attention] "Living by the wisdom of computer science doesn't sound so bad after all. And unlike most advice, it's backed up by proofs." -- Algorithms to live by: The computer science of human decisions. ID: 1763301 · |
|
Richard Haselgrove Send message Joined: 4 Jul 99 Posts: 14650 Credit: 200,643,578 RAC: 874
|
Can do in the morning, but I've clocked off to watch the Superbowl for tonight. ID: 1763303 · |

©2024 University of California
SETI@home and Astropulse are funded by grants from the National Science Foundation, NASA, and donations from SETI@home volunteers. AstroPulse is funded in part by the NSF through grant AST-0307956.