it's the AP Splitter processes killing the Scheduler
Message boards :
Number crunching :
it's the AP Splitter processes killing the Scheduler
Message board moderation
Previous · 1 · 2 · 3 · 4 · 5 · 6 · Next
| Author | Message |
|---|---|
juan BFP  Send message Joined: 16 Mar 07 Posts: 9786 Credit: 572,710,851 RAC: 3,799 
|
Any news on the tests about the ACK theory? The proxy conection still holding the 100WU caches on all my hosts but my RAC fall like a rock even with all working at full load, i belive the wingmans was not able to do the same. 
ID: 1306618 · |
Richard Haselgrove  Send message Joined: 4 Jul 99 Posts: 14650 Credit: 200,643,578 RAC: 874 
|
And my hosts are holding their 100WU caches without needing a proxy. There's no rhyme or reason to it. Sorry, I got caught up in working on a different bug today (the fuller report is still waiting for a BOINC email moderator to release it - it was above their 200KB limit). Maybe I'll go back to wireshark tomorrow. ID: 1306620 · |
|
juan BFP Send message Joined: 16 Mar 07 Posts: 9786 Credit: 572,710,851 RAC: 3,799
|
Don´t worry just asking, take your time. Still using the Proxy because without it my DL are to slow to keep the caches.
ID: 1306623 · |
|
Josef W. Segur Send message Joined: 30 Oct 99 Posts: 4504 Credit: 1,414,761 RAC: 0 
|
Now getting it onto the project can be slow, especially if people are away in China, or touring the world playing Music, and the ones still here are snowed in under an avalanche of other problems, In a general sense, the project is working fine. It is delivering all the work the download pipe can handle, results are being validated and assimilated, etc. However, it's running something like a car misfiring on one cylinder which gets you where you're going but not comfortably. The staff were aware of the problem at least as early as November 4, that's why Dr. Anderson tried turning off "Resend lost results" which is a very heavy database load. (Think back, before Mark Sattler's funding drive allowed Oscar and Carolyn to be purchased, that resend feature was not possible here.) The fact that reducing database load failed to cure the problem is useful information, though the side effect that the number of ghosts grew during that time adds to the discomfort. Joe ID: 1306624 · |
|
juan BFP Send message Joined: 16 Mar 07 Posts: 9786 Credit: 572,710,851 RAC: 3,799
|
Now getting it onto the project can be slow, especially if people are away in China, or touring the world playing Music, and the ones still here are snowed in under an avalanche of other problems, Thanks for the info. But i can´t agree with the words "is working fine", a car with a misfiring cylinder never works fine. Why they not try to stop the AP-spliter on Synergy (keep the ones at Lando working) and look what hapennig? That could easely check the ACK theory and maybe give us some peaceful days with MB/AP WU still generated until Matt returns and realy fix the problem?. If that not works is simply to restart the tasks on Synergy. That will not take more than few minutes to try and Richard check the results on the other side of the world.
ID: 1306630 · |
|
Grant (SSSF) Send message Joined: 19 Aug 99 Posts: 13736 Credit: 208,696,464 RAC: 304 
|
And my hosts are holding their 100WU caches without needing a proxy. There's no rhyme or reason to it. So i decided to get rid of the proxy on one of my systems. First Scheduler request (for work, no reporting) timed out (as is normal for now). Next request for work (no reporting) got a response- took about 2min. Next request for work (this time reporting tasks) got a response & allocated work- once agin about 2 min. Download speed around 10-15kB/s. With the proxy it's 50kB/s or better, and Scheduler responses are ususally within 20 seconds. EDIT- just had a look at the graphs- AP work still going out, work still being split. However the databse is down to around 700 queries/s whereas it has been sitting around the 1,000/s. Although in the past even when doing 2,500/s+ it hasn't had any effect on the Scheduler. Another EDIT- just to add to the confusion, both my systems are now running without the proxy. Apart from the initial timeout, they're reporting & getting work. Figure that one out. Grant Darwin NT ID: 1306690 · |
|
tbret Send message Joined: 28 May 99 Posts: 3380 Credit: 296,162,071 RAC: 40
|
Kind-of fun, isn't it? I'm being absolutely serious. Trying to figure-out what the problem might be is kind-of fun. I just wish we had all the facts and resources necessary to figure it out. Nah, then it might look like work. ID: 1306693 · |
|
Richard Haselgrove Send message Joined: 4 Jul 99 Posts: 14650 Credit: 200,643,578 RAC: 874
|
Indeed, it's fun. 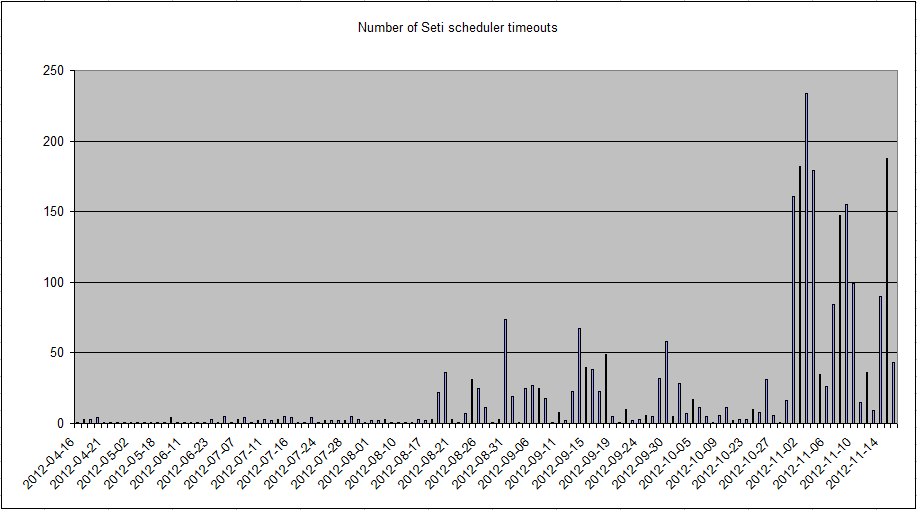 Those are the scheduler timeouts per day across five machines here, for the last six months. Looking at the raw data, the current problems seemed to start shortly before 20:30 UTC on 31 October. Ideas? Edit - the other significant date, when 20 or more per day started, is 19 August. ID: 1306740 · |
|
juan BFP Send message Joined: 16 Mar 07 Posts: 9786 Credit: 572,710,851 RAC: 3,799
|
Try to look if anyone make some modification on the lab or the settings in the servers on that day. Long time ago we have here a some similar situation, the problem was located on a bad configurated/faulty router. Switch it off, remake all the conections and reset the router firmware then reprogram it and... after some prays... turn it on again then... everything returns to normal, and works until them, realy never find the exact cause, but who cares? works with no problem after that for all this time. That´s a long long shoot. But... I realy belive you need to test the ACK theory first... is a better explantion...
ID: 1306741 · |
|
cdemers Send message Joined: 18 May 99 Posts: 30 Credit: 17,235,002 RAC: 0 
|
I saw the network problem myself about a week ago and tried an experiment. Figured there was a misconfiguration with Windows 7 default TCP settings for slow links. So just ran speedguide's TCPoptimizer and selected the optimize setting, and changed nothing else. (Don't play with the settings unless you know what they do.) And have been having very little trouble accessing work units now since then. They were piling up. Increased TCP window helped alot so the lost ACK and other packets don't get lost. http://www.speedguide.net/tcpoptimizer.php http://www.speedguide.net/downloads.php ID: 1306767 · |
|
Richard Haselgrove Send message Joined: 4 Jul 99 Posts: 14650 Credit: 200,643,578 RAC: 874
|
I saw the network problem myself about a week ago and tried an experiment. Figured there was a misconfiguration with Windows 7 default TCP settings for slow links. So just ran speedguide's TCPoptimizer and selected the optimize setting, and changed nothing else. (Don't play with the settings unless you know what they do.) And have been having very little trouble accessing work units now since then. They were piling up. Increased TCP window helped alot so the lost ACK and other packets don't get lost. That's (possibly) another source of clues to the symptoms. But what we really need is one network optimisation (for Linux) at the lab end, not 130,000 individual remote Windows optimisations, and another 20,000 remote (manual) optimisations by the users of non-Windows OSs. ID: 1306776 · |
|
juan BFP Send message Joined: 16 Mar 07 Posts: 9786 Credit: 572,710,851 RAC: 3,799
|
I try and see the results... 16/11/2012 12:56:21 SETI@home Sending scheduler request: Requested by user. 16/11/2012 12:56:21 SETI@home Reporting 4 completed tasks, requesting new tasks for CPU and GPU 16/11/2012 12:56:23 SETI@home Finished download of 03se12ac.8448.22562.140733193388047.10.33 16/11/2012 12:56:23 SETI@home Started download of 03se12ac.8448.23789.140733193388047.10.24 16/11/2012 12:56:27 SETI@home Scheduler request completed: got 4 new tasks The compleate cycle takes less than 6 secs. But i agree with Richard, thats is a "band-aid" solution, an excelent one of course, but we need a real final solution. On the other had that put the ACK theory on the top of the list.
ID: 1306780 · |
 Fred E. Fred E. Send message Joined: 22 Jul 99 Posts: 768 Credit: 24,140,697 RAC: 0
|
Those are the scheduler timeouts per day across five machines here, for the last six months. Looking at the raw data, the current problems seemed to start shortly before 20:30 UTC on 31 October. Ideas? It seems like a long shot, but Jeff Cobb announced a new 1GB switch for the lab in this post on Aug. 20th. I don't know if or when it was installed, or whether other changes were made at the time. Another Fred Support SETI@home when you search the Web with GoodSearch or shop online with GoodShop. 
ID: 1306787 · |
|
cdemers Send message Joined: 18 May 99 Posts: 30 Credit: 17,235,002 RAC: 0
|
The only way to fix the problem so you don't need to patch everyone would be to reduce latency. Either though more bandwidth and faster response from the servers. Or the possibly the remotely locating download servers at other locations on the net. ID: 1306788 · |
|
Tom* Send message Joined: 12 Aug 11 Posts: 127 Credit: 20,769,223 RAC: 9
|
ET's told us what the problem was back in 1996 in Mars Attacks. Ack Ack Trivia - " The writers weren't sure what the Martians should sound like so the script read "ack, ack, ack, ack" for all of their lines of dialogue. This became the actual words spoken by the Martians in the film." ID: 1306790 · |
|
Horacio Send message Joined: 14 Jan 00 Posts: 536 Credit: 75,967,266 RAC: 0 
|
I saw the network problem myself about a week ago and tried an experiment. Figured there was a misconfiguration with Windows 7 default TCP settings for slow links. So just ran speedguide's TCPoptimizer and selected the optimize setting, and changed nothing else. (Don't play with the settings unless you know what they do.) And have been having very little trouble accessing work units now since then. They were piling up. Increased TCP window helped alot so the lost ACK and other packets don't get lost. I have used the TCP optimizer and still I need to use a proxy to not get the timeouts... But as Ive said before, once the host reaches the limits, it works without using the proxy until for some reasson one single RPC fails and then the next RPC reports and requests more WUS and then it gets the timeout... once this is triggered I need to use the proxy again and so on... 
ID: 1306791 · |
|
Richard Haselgrove Send message Joined: 4 Jul 99 Posts: 14650 Credit: 200,643,578 RAC: 874
|
Well, here's a curious Wireshark screen. 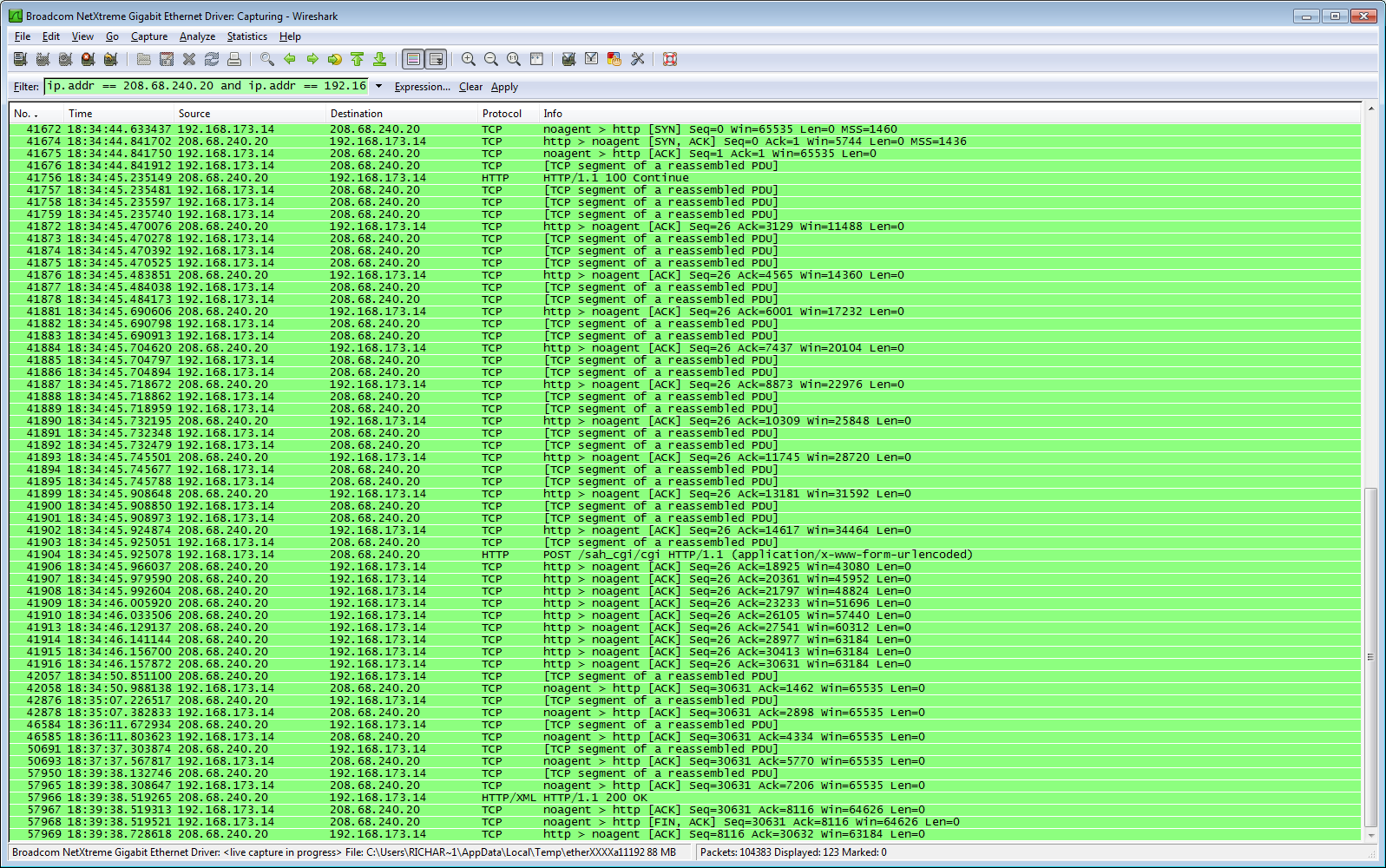 http://i1148.photobucket.com/albums/o562/R_Haselgrove/schednoloss.png I'll add messagelog and comments from another machine in a moment. Here's the local log: 16/11/2012 18:34:58 | SETI@home | [sched_op] Starting scheduler request The curious thing is that the RPC took almost five minutes, but with no packet loss at all. The request I sent to the server (down to the HTTP POST line, a bit over half way) seemed to go smoothly, in just over a second (from 18:34:44.6 to 18:34:45.9 local time). All the ACKs came back from the server in another 0.2 seconds. So far, so good. But the reply - the body of the message is in those [TCP segment of a reassembled PDU] packets - came very slowly: 18:34:50 18:35:07 18:36:11 18:37:37 18:39:38 And I didn't even get a new WU out of it... I'll try this one again when I really do need work. (Edit - I don't guarantee that the clocks on the two computers are exactly synchronised - that'll be why the opening SYN at 18:34:44 doesn't quite match the 'Starting scheduler request' at 18:34:58 - you'll just have to adjust by 14 seconds, throughout) ID: 1306866 · |
|
Richard Haselgrove Send message Joined: 4 Jul 99 Posts: 14650 Credit: 200,643,578 RAC: 874
|
Here's a more typical (and quicker) scheduler contact: 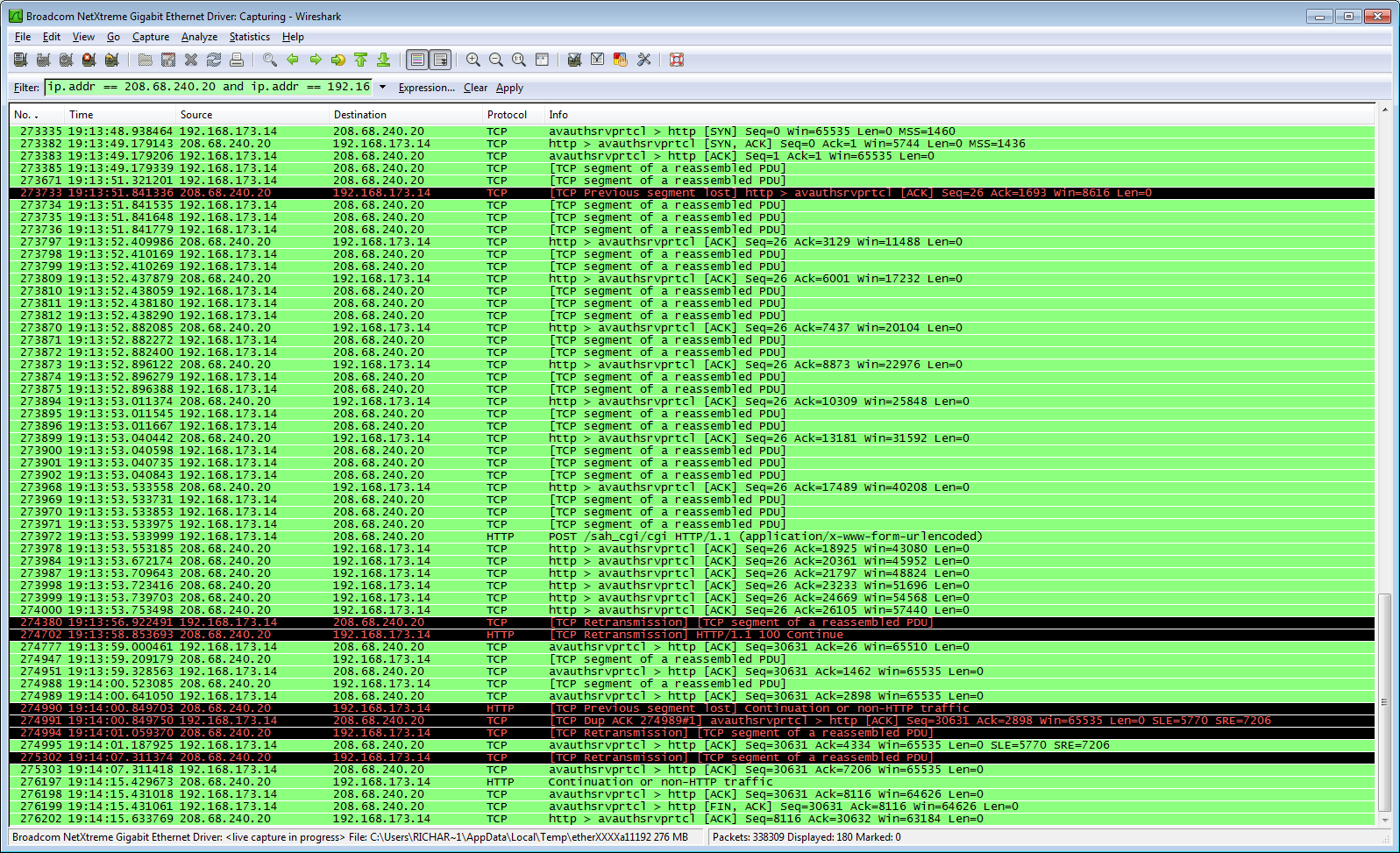 http://i1148.photobucket.com/albums/o562/R_Haselgrove/Schedwithloss.png The dark lines are packet loss, but they didn't interfere - the whole thing was over in 30 seconds. 16-Nov-2012 19:14:02 [SETI@home] [sched_op] Starting scheduler request ID: 1306875 · |
|
Horacio Send message Joined: 14 Jan 00 Posts: 536 Credit: 75,967,266 RAC: 0
|
But the reply - the body of the message is in those [TCP segment of a reassembled PDU] packets - came very slowly: I guess, those are the times in which the packets of the body were really sent... Can it be that they took some time because they had to wait until the pipes have "space" for them?
ID: 1306882 · |
|
Richard Haselgrove Send message Joined: 4 Jul 99 Posts: 14650 Credit: 200,643,578 RAC: 874
|
But the reply - the body of the message is in those [TCP segment of a reassembled PDU] packets - came very slowly: "some time"? You can say that again. Wireshark was timing to the microsecond. And on a gigabit network port, it would expect to see about 100 bytes per microsecond. Two whole minutes feels like a lifetime, at networking speeds. Nothing is that busy. ID: 1306885 · |

©2024 University of California
SETI@home and Astropulse are funded by grants from the National Science Foundation, NASA, and donations from SETI@home volunteers. AstroPulse is funded in part by the NSF through grant AST-0307956.