Panic Mode On (10) Server problems
Message boards :
Number crunching :
Panic Mode On (10) Server problems
Message board moderation
Previous · 1 · 2 · 3 · 4 · 5 · 6 · 7 · 8 . . . 13 · Next
| Author | Message |
|---|---|
 zoom3+1=4 zoom3+1=4 Send message Joined: 30 Nov 03 Posts: 65740 Credit: 55,293,173 RAC: 49 
|
Regarding boinc's underlying premise, you allude to, I don't pay much attention to it frankly. Getting more Matts, Hmm, It'll Have to be done outside the USA as Cloning Humans is illegal here currently. Otherwise We may as well have a bunch of Fred Flintstone clones saying "Yaba Daba Do" all the time. ;) The T1 Trust, PRR T1 Class 4-4-4-4 #5550, 1 of America's First HST's 
ID: 824059 · |
|
Uli Send message Joined: 6 Feb 00 Posts: 10923 Credit: 5,996,015 RAC: 1 
|
Three weeks out and Seti is going in Panic mode. What details do you need? Pluto will always be a planet to me.  Seti Ambassador Not to late to order an Anni Shirt ID: 824853 · |
|
[B^S] madmac Send message Joined: 9 Feb 04 Posts: 1175 Credit: 4,754,897 RAC: 0 
|
Can someone explain what happenned here please. 30/10/2008 11:58:01|SETI@home|Sending scheduler request: Requested by user. Requesting 0 seconds of work, reporting 4 completed tasks 30/10/2008 12:00:52||Project communication failed: attempting access to reference site 30/10/2008 12:00:53||Internet access OK - project servers may be temporarily down. 30/10/2008 12:00:56|SETI@home|Scheduler request failed: Failed sending data to the peer The next minutes the schedular worked and the four were acknowledged. 
ID: 824890 · |
|
Byron S Goodgame Send message Joined: 16 Jan 06 Posts: 1145 Credit: 3,936,993 RAC: 0
|
Looks like a connection failure. Appears it's the luck of the draw, because just two minutes before your connection failure, I reported 9 WU. Your luck of the draw must have come a few minutes later. Edit: guess when it comes to the replacement DL's, which are in retry mode, my luck of the draw will come later as well. ID: 824891 · |
Richard Haselgrove  Send message Joined: 4 Jul 99 Posts: 14650 Credit: 200,643,578 RAC: 874
|
Just looks like one of the regular download spikes on the Cricket graphs. Every thime there's a download spike, the general cacophany of network traffic means that other messages can't get themselves heard over the noise. As soon as the downloads start to ease off, expect any remaining uploads or reports to go through sweet as pie, with a corresponding spike in upload traffic. Matt reckons he's on to something in Oh no! Bruno!, but I don't think he's quite got it yet. ID: 824895 · |
|
PhonAcq Send message Joined: 14 Apr 01 Posts: 1656 Credit: 30,658,217 RAC: 1
|
It's getting worse, in my opinion. I'm now getting bunches of "refused- result already reported as success" errors in my logs. Is anybody getting p---ed off about these network issues yet? (truly p---ed off, I mean, with a little passion???) ID: 824899 · |
|
Richard Haselgrove Send message Joined: 4 Jul 99 Posts: 14650 Credit: 200,643,578 RAC: 874
|
It's getting worse, in my opinion. I'm now getting bunches of "refused- result already reported as success" errors in my logs. No, it's driving me to put my thinking cap on and try some dispassionate analysis, to try and help Matt find where the problem lies so that he can fix them properly: no point in just buying him ever bigger rolls of duct tape. Have a look at my new post in Oh no! Bruno! and see if you can see any flaws in my logic. I'm a bit worried about the --> (reporting?) --> link: I don't see any cause for that, except an over-reliance on Crunch3r's v6.1.0 client. ID: 824901 · |
kittyman  Send message Joined: 9 Jul 00 Posts: 51468 Credit: 1,018,363,574 RAC: 1,004
|
It's getting worse, in my opinion. I'm now getting bunches of "refused- result already reported as success" errors in my logs. Sorry, my friend.......but my passion is for the project. Getting p'd off won't help anything......and unless someone wins the lottery and helps Seti buy a bunch of new hardware, things are likely to continue in a bit of a less than smoothly fashion. It's not like they are not trying very hard to make what they have run as smoothly as possible.......keep reading Matt's technical news posts....it's not like they are sitting on their haunches waiting for the servers to heal themselves. And your 'already reported as success' messages are something I have seen before, not a real big issue. It just means that the WU was reported, and the final handshaking with the server was not completed when the connection was interrupted, usually due to very high bandwidth at the time. So on the next connection, your Boinc client tries to report the WU again, and the server tells you it already has it. No problem really. If you check your completed results for the WUs you see that error message on, you should see them reported all safe and sound. "Freedom is just Chaos, with better lighting." Alan Dean Foster 
ID: 824916 · |
|
PhonAcq Send message Joined: 14 Apr 01 Posts: 1656 Credit: 30,658,217 RAC: 1
|
passion-->project-->missing the point or deflecting. Let's have some passionate problem solving based on dispassionate analysis and problem solving. I can't help with the 6.1 stuff; I'm totally ignorant about the specific details of these versions. Yet the question sounds reasonable. At some level of connections, bruno as the sole upload server must become the bottleneck. Are we there yet? What would be the problem of putting a second parallel server into service for that purpose? Has this been done before? Or is there any sort of buffering parameter that can be adjusted for increased loads? I'm not a network expert but the behavior seems a lot like what I experienced using DOS and typing too fast. Is there any progress on changing the top-off cache policy discussed elsewhere? Because of the number of hosts out there, I would think there is a large multiplier available there to resolve some of the bandwidth blockades, if we simply didn't frequently pester the server for 28 seconds of work (times 300K hosts). ID: 824923 · |
|
Richard Haselgrove Send message Joined: 4 Jul 99 Posts: 14650 Credit: 200,643,578 RAC: 874
|
One of the problems with analysing SETI problems is that the problem keeps changing, and the solution to one problem won't solve (and may even cause) another problem. But focussing on the issue of the day: I don't think it's an upload problem, so I don't think duplicating the upload functions of Bruno would help in this case. Evidence? When I was monitoring the traffic graphs this morning, I saw a more-than-doubling of the upload traffic (10Mb to 22.75Mb) exactly as the download traffic came down a mere 2% from its peak. Bruno isn't involved in downloads, and can clearly handle peak upload rates way above the baseline average: so my feeling is that this particular problem has a network (router or WAN) source. Why is the network maxxed out? Sometimes it's because Matt is splitting shorties, or we're playing catch-up after an outage: at those times, we as a community are actually able to crunch more than the pipe can supply. It's bound to be maxxed out: the only solution would be a fatter pipe. Matt has re-opened negotiations to increase the bandwidth above 100Mb nominal / 96Mb practical - let's wish him the best of luck. At other times, the network is able to handle the average community demand, but can't handle the peak demand - those strange traffic spikes. Obviously, the 'fat pipe' solution would help here too, but it would also help if the flow was more even - squash the spikes and fill the troughs. I don't think there's much we can do at our end to solve that one. The spikes are too frequent, but too irregular, to be able to schedule a 'spike miss' for our download requests (I got caught out myself when today's 7am spike followed much sooner than I was expecting after the 5am spike). It probably would help to avoid the network congestion if BOINC's automatic download retries backed off further and faster if they were balked by network congestion: but I can see that being unpopular, and possibly even causing as many problems as it solves. Ned's variable p-Persistence, imposing a variable degree of back-off according to a project-specified measure of congestion, sounds like the nearest approach so far. I'm also persuaded by Josef's analysis that the spikes occur because the MB splitters do, but the Astropulse splitters don't, pause when the workunit storage is getting full. That accounts satisfactorily for my personal observation that I'm much more likely to be allocated an AP task if I do a work request during a download traffic spike. ID: 824926 · |
|
Josef W. Segur Send message Joined: 30 Oct 99 Posts: 4504 Credit: 1,414,761 RAC: 0
|
For the last day (or the last week), Cricket is showing an average of about 74 Mbps on the download side, and over 10 Mbps on the upload side. The average size of a Setiathome_Enhanced result on my hosts is just over 26000 bytes, adding 3% for the overhead of uploading with added XML gives 26780 bytes. That's just about 1/14 the size of a S_E WU, so the portion of the upload bandwidth which is being used by uploads would be 74/14 ~= 5.3 Mbps. The other ~5 Mbps may be mostly requests to the Scheduler. Those requests can be small, but adding in the information for reporting completed work, and the information on other work queued on the host, can easily make such a request considerably larger than an uploaded result. If either an upload or a request to the Scheduler fails with an http error, it is tried again a minute or more later. I think I've seen, but cannot be sure because I'm using dial-up, that such errors are far more likely as soon as the download bandwidth is saturated with AP work. If so, successful retries may be a large part of the peak in upload bandwidth which follows an AP burst. Joe ID: 824984 · |
|
1mp0£173 Send message Joined: 3 Apr 99 Posts: 8423 Credit: 356,897 RAC: 0
|
For the last day (or the last week), Cricket is showing an average of about 74 Mbps on the download side, and over 10 Mbps on the upload side. The average size of a Setiathome_Enhanced result on my hosts is just over 26000 bytes, adding 3% for the overhead of uploading with added XML gives 26780 bytes. That's just about 1/14 the size of a S_E WU, so the portion of the upload bandwidth which is being used by uploads would be 74/14 ~= 5.3 Mbps. Which is why some sort of mechanism to "cool down" the BOINC client would be useful -- especially if there was a way for the BOINC servers to broadcast some kind of "speed" metric. ID: 825000 · |
|
Jim Volfan Send message Joined: 22 May 99 Posts: 52 Credit: 24,239,706 RAC: 90
|
The scheduler processes on anakin are disabled, no work being reported or being sent out. The Cricket graphs have almost flat-lined. Wonder if they were turned off, since they say disabled and not "not running"? Anakin is up, the feeder.i686 process is running normally. Results received in the last hour is at zero, so it has been this way for a little while. I don't expect anything to happen on the Berkeley front for another 8 1/2 hours or so. Be patient folks, it will happen. PS, at least the Results waiting for DB purging is draining...  
ID: 825204 · |
|
Crystallize Send message Joined: 20 May 99 Posts: 16 Credit: 4,428,996 RAC: 0 
|
. I hope it wont take all weekend   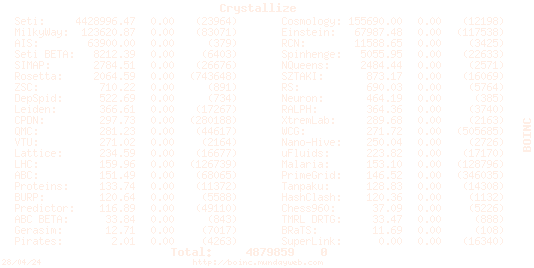
ID: 825218 · |
|
Fred J. Verster Send message Joined: 21 Apr 04 Posts: 3252 Credit: 31,903,643 RAC: 0 
|
For now, Anakin, the scheduler function is still disabled. Also get my forum pages half in German (HEADERS) and English (TEXT)? Anyone having a similar kind off problem, read in another thread someone got his in Japanese? This 'language error', happens ONLY on my VISTA host(1) 
ID: 825226 · |
|
petros Send message Joined: 10 Jul 03 Posts: 72 Credit: 141,587 RAC: 0 
|
For now, Anakin, the scheduler function is still disabled. hi there, it doesn't have to do with your operating system cause the same happens to me too. Im clicking the header <community> and then on the bottom the option < Languages> ,even when im choosing English the site comes out in half English and half German. SETI ID: 825229 · |
|
arkayn Send message Joined: 14 May 99 Posts: 4438 Credit: 55,006,323 RAC: 0
|
Somebody should be in in about 2 hours or so and kick whatever server is freaking out this time. 
ID: 825260 · |
|
kittyman Send message Joined: 9 Jul 00 Posts: 51468 Credit: 1,018,363,574 RAC: 1,004
|
Ringgggggg Ringgggggggg Ringggggggggggg.... Heloo.....have I reached the party to whom I am speaking? Calling Seti Central......uploads still failing...... Please kick once if you can hear me..... Kick twice if you cannot. Kick harder if you cannot read this post...LOL. "Freedom is just Chaos, with better lighting." Alan Dean Foster
ID: 825343 · |
|
kittyman Send message Joined: 9 Jul 00 Posts: 51468 Credit: 1,018,363,574 RAC: 1,004
|
Hmmmmmmmmmm...no answer yet..... "Freedom is just Chaos, with better lighting." Alan Dean Foster
ID: 825372 · |
|
Richard Haselgrove Send message Joined: 4 Jul 99 Posts: 14650 Credit: 200,643,578 RAC: 874
|
Hmmmmmmmmmm...no answer yet..... All you can do is wait until the Cricket graph stops flatlining at 95 megabits.... ID: 825377 · |

©2024 University of California
SETI@home and Astropulse are funded by grants from the National Science Foundation, NASA, and donations from SETI@home volunteers. AstroPulse is funded in part by the NSF through grant AST-0307956.