Gasping for Air (May 14 2007)
Message boards :
Technical News :
Gasping for Air (May 14 2007)
Message board moderation
Previous · 1 · 2 · 3 · 4 · 5 · 6 · Next
| Author | Message |
|---|---|
|
HachPi Send message Joined: 2 Aug 99 Posts: 481 Credit: 21,807,425 RAC: 21 
|
Thank you. I am glad we are back up. I am sure that this was a nightmare for all of you involved in the recovery. Still it was strange out here. After running this for so long, it was like the disappearance of an old friend. I check in a couple times per week for updates. It was kind of interesting to note how I missed the routine. Are you kidding, .... we are NOT back up, we are still crawling out of the gutter... Proof 5/15/2007 6:24:56 PM|SETI@home|Backing off 2 hr 23 min 1 sec on upload of file 18fe05aa.26345.3009.617326.3.200_0_0 5/15/2007 6:24:56 PM|SETI@home|[file_xfer] Started upload of file 18fe05aa.26345.3009.617326.3.195_0_0 5/15/2007 6:24:59 PM||Access to reference site succeeded - project servers may be temporarily down. 5/15/2007 6:25:19 PM||Project communication failed: attempting access to reference site 5/15/2007 6:25:19 PM|SETI@home|[file_xfer] Temporarily failed upload of 18fe05aa.26345.3009.617326.3.195_0_0: system connect 5/15/2007 6:25:19 PM|SETI@home|Backing off 3 hr 24 min 25 sec on upload of file 18fe05aa.26345.3009.617326.3.195_0_0 5/15/2007 6:25:19 PM|SETI@home|[file_xfer] Started upload of file 16fe05ab.10775.2368.859632.3.32_0_0 5/15/2007 6:25:21 PM||Access to reference site succeeded - project servers may be temporarily down. 5/15/2007 6:25:41 PM||Project communication failed: attempting access to reference site 5/15/2007 6:25:41 PM|SETI@home|[file_xfer] Temporarily failed upload of 16fe05ab.10775.2368.859632.3.32_0_0: system connect 5/15/2007 6:25:41 PM|SETI@home|Backing off 3 hr 6 min 45 sec on upload of file 16fe05ab.10775.2368.859632.3.32_0_0 5/15/2007 6:25:41 PM|SETI@home|[file_xfer] Started upload of file 18fe05aa.26345.3009.617326.3.199_0_0 5/15/2007 6:25:43 PM||Access to reference site succeeded - project servers may be temporarily down. 5/15/2007 6:26:03 PM||Project communication failed: attempting access to reference site 5/15/2007 6:26:03 PM|SETI@home|[file_xfer] Temporarily failed upload of 18fe05aa.26345.3009.617326.3.199_0_0: system connect 5/15/2007 6:26:03 PM|SETI@home|Backing off 2 hr 11 min 17 sec on upload of file 18fe05aa.26345.3009.617326.3.199_0_0 5/15/2007 6:26:04 PM||Access to reference site succeeded - project servers may be temporarily down. 5/15/2007 6:26:48 PM||Project communication failed: attempting access to reference site 5/15/2007 6:26:48 PM|SETI@home|[file_xfer] Temporarily failed upload of 11fe05aa.24379.10048.978420.3.132_0_0: http error 5/15/2007 6:26:48 PM|SETI@home|Backing off 1 hr 48 min 57 sec on upload of file 11fe05aa.24379.10048.978420.3.132_0_0 5/15/2007 6:26:49 PM||Access to reference site succeeded - project servers may be temporarily down. 5/15/2007 6:47:44 PM|SETI@home|Sending scheduler request: Requested by user 5/15/2007 6:47:44 PM|SETI@home|(not requesting new work or reporting completed tasks) Greetings, HP ;-)) ID: 568017 · |
 Francesco Forti Francesco Forti Send message Joined: 24 May 00 Posts: 334 Credit: 204,421,005 RAC: 15 
|
I don't know what is, but yesterday I have downloaded some work (luky) and now I have finished it But I can't upload the results. So the system thinks that I have also a lot of work to do and if I ask for new RUs I get this msg: (not requesting new work or reporting completed tasks So I can't dowload new work. And the communication process is trying, minute after minute, to retry the uploads. I suggest (if possible): a) stop download ad accept only upload for 5~6 hours. b) stop upload and accept only download for 8~10 hours. Tomorrow we can see if things are goin better. Bye, Franz ID: 568018 · |
|
TimeLord04 Send message Joined: 9 Mar 06 Posts: 21140 Credit: 33,933,039 RAC: 23 
|
AHA!!! So, we have a clue now!!! So, what is the answer, (on Berkeley's end of things), to permanently clear things pertaining to this "round robin" and "load balancing" that I and others are experiencing on Windows machines? (I for one am on Win XP Pro SP-2.) We cannot be expected to have to issue the "ipconfig /flushdns" command to release the browser freezes and hangs in the SETI@Home and Beta/Astropulse Forums for time and eternity upon the continuing intermittent Browser hangs caused by the random and ongoing Berkeley Server IP Switching? Especially since the Cogent connection has been replaced by Hurricane; yet, a Traceroute command by James L Neil posted in here indicates that the Cogent connection still exists and that the Hurricane Tracerute has issues and is "unreacheable"...? Can we get anymore confusing here??? Doesn't James L Neil's Traceroute indicate that this may be a culprit if not the culprit in our connectivity issues? With Kryten physically removed from the pitcture as of late this past weekend; was another Server put in place, (or software patched), to perform "load balancing", and is this why we need the "round robin" patching? I am just a simple IT Hardware specialist; not a programmer, and definitely not a DNS expert... Software issues and DNS problems just make my brain hurt like I'm being forced to solve a Geometry problem... (I failed Geometry; twice, just can't understand it...) It is beyond me... Do I need some sort of 3Rd Party DNS Program to circumnavigate around Time Warner's, (yes I'm still having those issues, too), and Berkeley's random IP switching? If so; I know of only one product line on the market that might come close to clearing this up... A company in Iceland has specific DNS software, (primarily for MAC; however, some Windows Product, too), that may be the answer... The Company is Men and Mice. Does anyone here have personal experience with this or other "like" products? That is, would a strictly DNS only program smooth the conflict of connectivity between my computer, Time Warner's flawed DNS connections via the Los Angeles Trunk, and Berkeley with the errant reflecting Cogent link being "round robin"-ed to the Hurricane connection? Or, am I still missing something here? Even taking away the Time Warner issues from the equation; I still had browser issues at my Parents' place. They are in the San Francisco East Bay on Comcast. Comcast DNS Servers seem to be free of the problems that Time Warner has in my area. However; my Parents' system encounters the same Browser hangs and freezes as my system when attempting to maintain connection to SETI@Home and Beta/Astropulse... Thereby showing me that there is an issue at Berkeley that a DNS Specific Software package installed on my machine and my Parents' machine might fix for the Windows platform environment - yes/no??? If "yes" to my last question; then that just leaves the Bruno issue... Is this the last key to the SETI issue(s) of Uploading and Downloading WUs? If "no" to my last question; then what next? TimeLord04 Have TARDIS, will travel... Come along K-9! Join Calm Chaos ID: 568021 · |
|
1mp0£173 Send message Joined: 3 Apr 99 Posts: 8423 Credit: 356,897 RAC: 0
|
If there is one thing I know, it's DNS. Round Robin DNS is not the cause of your problem, and no action with regard to DNS will "fix" the issue. Just in case it wasn't clear: Round Robin DNS is your friend. and my comments about Microsoft's DNS server (and resolver) was just a grumble about how Lazy Programmers in Redmond should have done something, and didn't. Microsoft's broken resolver doesn't help, but Berkeley's competent DNS servers don't need help from broken resolvers. There is no reason to /flushdns. This also has nothing to do with uploads or downloads. Those don't go to setiathome.ssl.berkeley.edu, they go to setiboincdata.ssl.berkeley.edu. That machine is at 208.68.240.16, on Hurricane Electric. There is only one A record: setiboincdata.ssl.berkeley.edu. 300 IN A 208.68.240.16 Note the number "300" -- this is the maximum number of seconds that this record should be cached -- five minutes. Resolvers should discard the record and do a new lookup if the record is more than five minutes old. That said, this zone hasn't changed since the 9th, so any outdated info (from the Cogent move) should be long gone. Either way, their DNS is not broken. As to problems with uploads and downloads, we're clearly seeing the same issue we always see after an outage -- too many machines trying to connect all at once, probably made worse by people hitting the "update" button or the "retry" button over and over. Each time one machine completes a transaction (upload, download, or scheduler), the load goes down a little bit. The overall excessive load goes down a little bit, and more transactions complete during the next second. Things should be getting a tiny bit better with each passing minute. The solution is to relax. Fix yourself a nice beverage, lean back and enjoy the day. If the problem is still around on Friday morning, then look at what might be done to fix it.
ID: 568061 · |
|
[AF>France>Chti mi]Bill Send message Joined: 12 Oct 04 Posts: 3 Credit: 8,429 RAC: 0 
|
salut tou le monde dite moi ,moi je participe au projet seti@home pour la science et pas pour faire des bla bla sur les forums donc se serai franchement sympa d'ecrire en claire et caractere gras sur la premiere page du site quand le projet va enfin pouvoir reprendre car sa commence serieusement a etre casse couille vos connerie je comprend parfaitement qu'il peut y avoir des pannes et n'en blame personne mais merde mettez clairement la date de reprise sa evitera au mec comme moi pas tres fort en anglais de tourner en rond comme un con pendant des heures avec des traducteur tous sa pour une date a la con merci ID: 568083 · |
|
HachPi Send message Joined: 2 Aug 99 Posts: 481 Credit: 21,807,425 RAC: 21
|
salut tou le monde dite moi ,moi je participe au projet seti@home pour la science et pas pour faire des bla bla sur les forums donc se serai franchement sympa d'ecrire en claire et caractere gras sur la premiere page du site quand le projet va enfin pouvoir reprendre car sa commence serieusement a etre casse couille vos connerie je comprend parfaitement qu'il peut y avoir des pannes et n'en blame personne mais merde mettez clairement la date de reprise sa evitera au mec comme moi pas tres fort en anglais de tourner en rond comme un con pendant des heures avec des traducteur tous sa pour une date a la con Ils ne savent eux memes quand est que ca peut reprendre. Suggestion ayez s'il vous plait un peu de patience, ils feront de leur mieux, Salutations, From la Belgique, ;-)) HP. ID: 568086 · |
|
[AF>France>Chti mi]Bill Send message Joined: 12 Oct 04 Posts: 3 Credit: 8,429 RAC: 0
|
lol oki merci hachpi ID: 568088 · |
|
[AF>France>Chti mi]Bill Send message Joined: 12 Oct 04 Posts: 3 Credit: 8,429 RAC: 0
|
la patience je l'ai mais je ne comprend rien c'est ca qui m'enerve lol ID: 568089 · |
|
arr25b Send message Joined: 19 Nov 05 Posts: 16 Credit: 14,839,632 RAC: 0 
|
I'd love to be able to upload and download WU's but at this time I can only download some of the time. I know we've had a serious outage and everyone has worked above and beyond the call of duty, but please let me help the project by being able to upload and download all the time ID: 568099 · |
zombie67 [MM]  Send message Joined: 22 Apr 04 Posts: 758 Credit: 27,771,894 RAC: 0
|
Eric's biannual post #6: You can tuna fish, but you can't tune a TCP http://setiathome.berkeley.edu/forum_thread.php?id=39484 Dublin, California Team: SETI.USA 
ID: 568109 · |
|
Conrad Human Send message Joined: 17 Nov 00 Posts: 67 Credit: 2,009,224 RAC: 0 
|
Eric's biannual post #6: You can tuna fish, but you can't tune a TCP
ID: 568114 · |
|
Philadelphia Send message Joined: 12 Feb 07 Posts: 1590 Credit: 399,688 RAC: 0
|
I'm sure this is how they all feel about now :) http://www.trekmania.net/wavs/12hours.wav ID: 568119 · |
|
SilentWarrior Send message Joined: 21 Aug 99 Posts: 1 Credit: 167,081 RAC: 0
|
... Here is a possible concern. I understand the thunder going on with everyone tapping the update key, but I have a work unit that began to upload but only completed 1.81% from the transfer bucket. Why do you think it would begin to accept the file only to drop the connection? I think I got caught in the 'cycling'. Does this impact the WU? BTW.... Do you recommend any particular beverage specifically designed for relaxation? I drink far too many 'wind me up[read: caffeinated] drinks' with 'Diet Mountain Brew' on the top of my list. "Silent Warrior, not being very Silent" ID: 568124 · |
|
Philadelphia Send message Joined: 12 Feb 07 Posts: 1590 Credit: 399,688 RAC: 0
|
... I don't know why it starts and stops mid flight but it's happened to me many times of late. I do know that when it did eventually go, I checked it out and it was fine, cobblestones awarded. Instead of 'wind me up's', how about 'wind me down's'. This Bud's for you.  ID: 568127 · |
|
KWSN THE Holy Hand Grenade! Send message Joined: 20 Dec 05 Posts: 3187 Credit: 57,163,290 RAC: 0
|
... Some fava beans and a nice Chianti do it for me... (snicker...) .  Hello, from Albany, CA!... ID: 568129 · |
|
TimeLord04 Send message Joined: 9 Mar 06 Posts: 21140 Credit: 33,933,039 RAC: 23
|
OK - Follow up on DNS issues... I read Ned Ludd's last post in reply to mine; combined with that, I spoke with a friend of mine who works at Men and Mice. Unfortunately the programs that Men and Mice carry won't support/assist me as an End User; however, should the SETI Crew be interested, (of course for $$$ that the SETI Crew/Project doesn't have), Men and Mice carry many programs that are "Business End User" related for Servers... That said; after explaining my plight and what I've been seeing and experiencing via Time Warner/Road Runner and the vast changes at Berkeley switching from Cogent to Hurricane, my friend helped me to make some changes to the "hosts" file on Excalibur, (my Primary Cruncher), as well as changes to my Router, (changes that correlate to changes suggested by many of you here over the past few months that I couldn't make because they were "locked out" to me by the Router), that have now got me doing an essential "end run" around Time Warner to get to Berkeley... The aforementioned "locked out" Router configurations are now accessible; I had my friend "Remote Login" to my Router, (with temporary priveleges), and I believe he had the Router update its firmware. From there; the previously "locked out" DNS area is now accessible, so, we then entered in the DNS Values of "4.2.2.1", "4.2.2.2". Then rebooted the cable modem, router, and computer. SUCCESS!!! Between the changes to the "hosts" file, and the changes to the Router, now the "hanging" in the Browser for SETI@Home and Beta/Astropulse is resolved. My friend further states that now I should no longer need to continually "ipconfig /flushdns" the way I've had to for months due to the Time Warner DNS issues. He has recommended that I keep my Command Prompt open for another day and monitor the connectivity and if my connectivity remains stable and the Browser no longer hangs then I can close out the Command Prompt. < breathing now... > Now; just like the rest of you, I await the stabilization of Bruno by Matt and crew. Once Bruno is running the way the want and expect, then I will switch SETI@Home and Beta/Astropulse from "No New Tasks" to "Allow New Tasks" and let BOINC 5.4.11 do its thing. Oh, one other thing I need to do... I need to replicate the "4." DNS values on my Wife's Laptop and on my other Tower Systems. Then, I'm done... < again, breathing... > NOTE: With the changes made to my "hosts" file and the Router; the last "automated" update from SETI@Home and one manual update to Beta/Astropulse yielded this: From SETI: 5/15/2007 3:37:36 PM|SETI@home|Sending scheduler request to http://setiboinc.ssl.berkeley.edu/sah_cgi/cgi 5/15/2007 3:37:56 PM|SETI@home|Sending scheduler request to http://setiboinc.ssl.berkeley.edu/sah_cgi/cgi 5/15/2007 3:37:56 PM|SETI@home|Reason: To fetch work 5/15/2007 3:37:56 PM|SETI@home|Requesting 8640 seconds of new work 5/15/2007 3:38:01 PM|SETI@home|Scheduler request succeeded 5/15/2007 3:38:01 PM|SETI@home|No work from project 5/15/2007 3:38:01 PM|SETI@home|Deferring scheduler requests for 1 minutes and 0 seconds That's when I set it once again to "No New Tasks" From Beta/Astropulse: 5/15/2007 3:39:37 PM|SETI@home Beta Test|Sending scheduler request to http://setiboinc.ssl.berkeley.edu/beta_cgi/cgi 5/15/2007 3:39:37 PM|SETI@home Beta Test|Reason: Requested by user 5/15/2007 3:39:37 PM|SETI@home Beta Test|(not requesting new work or reporting completed tasks) 5/15/2007 3:39:42 PM|SETI@home Beta Test|Scheduler request succeeded 5/15/2007 3:39:42 PM|SETI@home Beta Test|Message from server: Project is temporarily shut down for maintenance 5/15/2007 3:39:42 PM|SETI@home Beta Test|Project is down NOTE 2: Notice that NOW neither SETI@Home nor Beta/Astropulse are reporting the "http error" that I was getting since the demise of the original Thumper! AHA!!! Major improvement... With all of the above in mind; may I now assume that once Bruno is up and running that I am "OK" and should receive actual WUs? Thanks in advance. Sincerely, TimeLord04 Have TARDIS, will travel... Come along K-9! Join Calm Chaos ID: 568143 · |
|
1mp0£173 Send message Joined: 3 Apr 99 Posts: 8423 Credit: 356,897 RAC: 0
|
You may need to be careful about your HOSTS file. What this does is completely replace DNS for names that are in the hosts file, so if Berkeley moves a machine to a new IP, your system(s) will not change. I'd take out the entries in a few days, once things are stable and you can see what changes do. Also, note that 4.2.2.1 and 4.2.2.2 belong to Verizon, if enough non-Verizon customers use those they'll probably configure them so they don't resolve outside their networks. You could run your own name server.... ID: 568159 · |
|
roguebfl Send message Joined: 21 May 99 Posts: 129 Credit: 223,953 RAC: 0 
|
It would see to me the fact the downloades are getthing thow slowlly whil uploads aren't is just making the situation worse? and it only increased the number of uploads in the back log. uninstall dyslexica.o : Permission denied 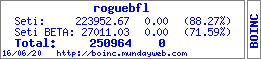 AMD Athlon 64 3000+ w/Windows AMD Athlon 1800+ w/Linux ID: 568172 · |
|
Odysseus Send message Joined: 26 Jul 99 Posts: 1808 Credit: 6,701,347 RAC: 6 
|
[…] I have a work unit that began to upload but only completed 1.81% from the transfer bucket. […]Does this impact the WU? When things are running normally, no: next time BOINC makes a good connection it’ll resume or start over. If the server got confused enough it may think your result has already been received, or otherwise lose track of it, but those events have been pretty rare during previous outage-recoveries.  ID: 568213 · |
|
musikman38 Send message Joined: 28 Feb 03 Posts: 2 Credit: 33,186 RAC: 0
|
for the last 39 hours i have been getting the same message: 5/15/2007 10:27:23 PM||Project communication failed: attempting access to reference site 5/15/2007 10:27:24 PM||Access to reference site succeeded - project servers may be temporarily down. 5/15/2007 10:27:27 PM|SETI@home|Scheduler request failed: couldn't connect to server 5/15/2007 10:27:27 PM|SETI@home|Deferring scheduler requests for 1 minutes and 0 seconds PLUS i have been getting this HTTP ERROR what gives my stats are droping not happy ID: 568294 · |
{kind=link}

©2024 University of California
SETI@home and Astropulse are funded by grants from the National Science Foundation, NASA, and donations from SETI@home volunteers. AstroPulse is funded in part by the NSF through grant AST-0307956.