APU load influence on total device throughput, MultiBeam
Message boards :
Number crunching :
APU load influence on total device throughput, MultiBeam
Message board moderation
| Author | Message |
|---|---|
 Raistmer Raistmer Send message Joined: 16 Jun 01 Posts: 6325 Credit: 106,370,077 RAC: 121 
|
There were discussions on this some time ago. Here are fresh data, based on multiBeam app now: http://lunatics.kwsn.info/index.php/topic,1735.msg61151.html#msg61151 Seems for SETI computations 4-cores AMD APU devices just fake ones. Should be marked as 2 cores with some sort of HT analogue, not as 4-cores ones. Will see if GPU part can improve situation or not, but CPU part just pathetic :/ SETI apps news We're not gonna fight them. We're gonna transcend them. ID: 1824985 · |
|
Mike Send message Joined: 17 Feb 01 Posts: 34258 Credit: 79,922,639 RAC: 80 
|
Since all AMD APU`s are based on FX CPU, 1 module are 2 CPU cores which have to share one FPU. So in fact 2 CPU cores but just 1 FPU. A quad core has 2 modules, 4 CPU cores and 2 FPU`s and so on. With each crime and every kindness we birth our future. ID: 1825002 · |
|
Raistmer Send message Joined: 16 Jun 01 Posts: 6325 Credit: 106,370,077 RAC: 121
|
To see how APU behaves under integer load is next stage. Though I need some integer-only project with quite homogenious tasks for that. Direct comparison: http://lunatics.kwsn.info/index.php?action=dlattach;topic=1735.0;attach=11478;image SETI apps news We're not gonna fight them. We're gonna transcend them. ID: 1825004 · |
|
Keith Myers Send message Joined: 29 Apr 01 Posts: 13164 Credit: 1,160,866,277 RAC: 1,873 
|
Had a discussion with Ray Hinchcliffe about how his monitoring program should handle the AMD FX architecture. He said it behaves more like an Intel processor with Hyperthreading based on its low level diagnostics within SIV so he changed how it is reported in SIV a few revisions ago. He still prints out AMD official naming of the processor but in the actual description of the CPU he shows it as CPUs 8 cores 4X2 with the balloon tech tip showing CPU-0 having 8 execution units, 4 cores each of which run 2 threads. 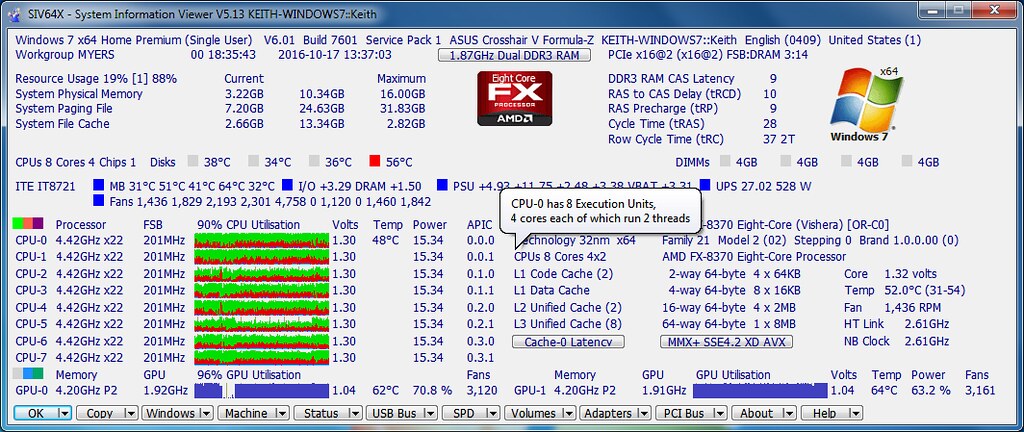 SIV FX balloon by Keith Myers, on Flickr[/img] SIV FX balloon by Keith Myers, on Flickr[/img]Seti@Home classic workunits:20,676 CPU time:74,226 hours   A proud member of the OFA (Old Farts Association) ID: 1825005 · |
|
Mike Send message Joined: 17 Feb 01 Posts: 34258 Credit: 79,922,639 RAC: 80
|
Just for Info. Here is a good explanation about AMD module design. https://www.reddit.com/r/buildapc/comments/1e8226/discussion_amds_module_architecture_the_fx_8350/ With each crime and every kindness we birth our future. ID: 1825009 · |
|
Raistmer Send message Joined: 16 Jun 01 Posts: 6325 Credit: 106,370,077 RAC: 121
|
Pity that times of Athlon XP is gone. Paradigma changed and need to change expectations too. For future purchases at least. AMD anticipated CPUs being tasked primarily with integer calculations and GPGPU cores tasked primarily with highly paralleled floating point arithmetic. Well, in a few days I'll do corresponding tests of GPU part. Will see how it behaves in useful practice (useful is MB performance of course, at least on these forums). SETI apps news We're not gonna fight them. We're gonna transcend them. ID: 1825011 · |
|
Keith Myers Send message Joined: 29 Apr 01 Posts: 13164 Credit: 1,160,866,277 RAC: 1,873
|
Maybe good times ahead for AMD in light of your Athlon XP comment. The upcoming Zen architecture looks very interesting. We will have to wait till next spring to find out I guess. Seti@Home classic workunits:20,676 CPU time:74,226 hours A proud member of the OFA (Old Farts Association) ID: 1825014 · |
|
Raistmer Send message Joined: 16 Jun 01 Posts: 6325 Credit: 106,370,077 RAC: 121
|
And here is a puzzle. So, taking out AVX, 2 FPUs for 2 cores inside module? App in my benchmark used SSE3 only (though FFTW could use AVX too). And still such performance drop versus IvyBridge... And in prev tests I saw AVX performance even worse than SSE3 one. Seems I need to do similar tests with another A10 with non-AVX OS installed to exclude this AVX uncertainty. That article claimed single non-AVX (128-bit, SSE one!) FPU per CPU... The module’s cores, in addition to the shared FPU, share L1 instruction cache, fetch, decode, and L2 cache. Once again, a big reason for this was to minimize cost while the engineers anticipated minimal performance loss from this design. Ha! Savings on L1/L2 caches... That will kill performance much more than any AVX could do! Such a pity those "engineers" don't participate in SETI (seems they don't participate in any other computational-intencive project) To save on cache in times where almost all computations are memory constrained.. OMG... Interesting, what will be if I pin 2 separate CPU instances to 2 separate "real" cores (that is, CPU1 and CPU3 for example)? ... Windows 8 and the W7 Patch Ups... So how CPU# to cores mapped then?... Time to implement -cpu_lock for AMD CPU builds?... SETI apps news We're not gonna fight them. We're gonna transcend them. ID: 1825017 · |
|
Keith Myers Send message Joined: 29 Apr 01 Posts: 13164 Credit: 1,160,866,277 RAC: 1,873
|
That's exactly the experiment that Ray Hinchcliffe and I conducted. Normal performance seen if WU locked onto CPU1 and CPU3. Fairly obvious reduction in performance if tasks were run on the logical CPU2 or CPU4 etc. The same reduction in performance was observed on Intel processors if HT enabled. So that is why he decided to describe the AMD FX processor as a 4 core CPU executing two threads at a time. Seti@Home classic workunits:20,676 CPU time:74,226 hours A proud member of the OFA (Old Farts Association) ID: 1825081 · |
|
Marco Franceschini Send message Joined: 4 Jul 01 Posts: 54 Credit: 69,877,354 RAC: 135 
|
http://www.realworldtech.com/sandy-bridge/6/ AVX implementation details in Sandy Bridge vs. Bulldozer. And a page on github describing new simd support under fftw 3.3.5. https://github.com/FFTW/fftw3/blob/master/NEWS https://github.com/FFTW/fftw3/tree/master/simd-support Marco. ID: 1825213 · |
|
Raistmer Send message Joined: 16 Jun 01 Posts: 6325 Credit: 106,370,077 RAC: 121
|
Thanks for links will read. Small remark about FFTW+AVX: checked wisdom file on Trinity host - no single AVX codelet. All either register or SSE2 (!) no higher! EDIT: to be sure checked wisdom on IvyBridge host too... and found same only register/SSE2 codelets for x64 app's wisdom. Checked GPU app's one (GPU app is x86 32-bit binary) - there are AVX codelets! So, from one side it makes Trinity vs IvyBridge comparison more fair (same FFTW performance level), but from other could mean that distributed x64 FFTW DLL just doesn't know about AVX support. Need to check this thoroughly after work. SETI apps news We're not gonna fight them. We're gonna transcend them. ID: 1825317 · |
|
Marco Franceschini Send message Joined: 4 Jul 01 Posts: 54 Credit: 69,877,354 RAC: 135
|
Small remark about FFTW+AVX: checked wisdom file on Trinity host - no single AVX codelet. All either register or SSE2 (!) no higher! This could be an SIMD autodetection issue. https://github.com/FFTW/fftw3/blob/master/simd-support/amd64-cpuid.h ID: 1825357 · |
|
Raistmer Send message Joined: 16 Jun 01 Posts: 6325 Credit: 106,370,077 RAC: 121
|
I added picture for Loveland C-60 APU http://lunatics.kwsn.info/index.php/topic,1735.msg61154.html#msg61154 Much (!) better picure. Though device is weak, it's performance scales with load just great. Fully loaded device provides much better performance than underloaded one. Instead of Trinity with AMD's FPU/cache cheating architecture. SETI apps news We're not gonna fight them. We're gonna transcend them. ID: 1826256 · |
|
Raistmer Send message Joined: 16 Jun 01 Posts: 6325 Credit: 106,370,077 RAC: 121
|
Interesting, that for Trinity 4CPU with idle GPU and 3CPU+working GPU the same overall device throughput measured http://lunatics.kwsn.info/index.php?action=dlattach;topic=1735.0;attach=11481;image. Fully loaded device has worse performance. Though additional measurements with locked affinity required to be sure in that 5th dot. Also, looking for separate GPU and CPU throughput behavior for dots 4 and 5 one can conclude that bottleneck not in computations but somewhere else. Decrease in CPU part allows corresponding increase in GPU part and vise versa. So, they both bottlenecked by data transfers. With shared L1/L2 caches between "cores" no wonder. I would say this AMD architecture very badly fits in SETI processing requirements (for AstroPulse lack of adequate caches even more noticeable). SETI apps news We're not gonna fight them. We're gonna transcend them. ID: 1826271 · |
|
Raistmer Send message Joined: 16 Jun 01 Posts: 6325 Credit: 106,370,077 RAC: 121
|
Small remark about FFTW+AVX: checked wisdom file on Trinity host - no single AVX codelet. All either register or SSE2 (!) no higher! Strange that Richard sees AVX codelets on his devices with very same DLL binary AFAIK. Could you repost link to those DLL binaries built by you? SETI apps news We're not gonna fight them. We're gonna transcend them. ID: 1826273 · |
Richard Haselgrove  Send message Joined: 4 Jul 99 Posts: 14650 Credit: 200,643,578 RAC: 874 
|
The one I'm using (and reported test results from) is the one I put into the installer when we first started using fully versioned file names: the build date (file datestamp) is 15 March 2014. ID: 1826277 · |
|
Raistmer Send message Joined: 16 Jun 01 Posts: 6325 Credit: 106,370,077 RAC: 121
|
And little updated IvyBridge picture: http://lunatics.kwsn.info/index.php?action=dlattach;topic=1735.0;attach=11483;image The main result is: with multiBeam app fully loaded IvyBridge has bigger overall device throughput/performance than with 4 CPU cores only. So, at least for this particular device iGPU OpenCl build is worthwhile. SETI apps news We're not gonna fight them. We're gonna transcend them. ID: 1826279 · |
|
Richard Haselgrove Send message Joined: 4 Jul 99 Posts: 14650 Credit: 200,643,578 RAC: 874
|
I'll maybe try that with my Skylake later this week. What are your units for the 'throughput' axis? Skylake, BTW, has been running for over a week now with the new iGPU build, with no sign of validation problems with the somewhat boring Beta diet. It's been running for the last 15 hours or so under Windows 10 instead of the original Windows 7. I'll check this afternoon that my dual-boot arrangements are working properly, and then set it running with the full rough-and-tumble of Main project tasks. ID: 1826281 · |
|
Raistmer Send message Joined: 16 Jun 01 Posts: 6325 Credit: 106,370,077 RAC: 121
|
So r3541 build should go into installer instead of prev ones. Regarding Y-axis: as denoted, it's in "PG_sets per second" units. That is, as I described in "materials and methods" part: http://lunatics.kwsn.info/index.php/topic,1735.msg61150.html#msg61150 sum all PG tasks elapsed times (in my case there are 3 identical sets of PG tasks so I take mean time) and inverse it (1/time). This will give fraction of PG set that can be done per second. In case with few cores loaded throughputs of each core/subdevice should be summed (cause I measure only 1 core in my case with 3 cores busy throughput of single core multiplied by 3). SETI apps news We're not gonna fight them. We're gonna transcend them. ID: 1826283 · |
|
Richard Haselgrove Send message Joined: 4 Jul 99 Posts: 14650 Credit: 200,643,578 RAC: 874
|
So r3541 build should go into installer instead of prev ones. That was my thinking, yes. But I want to expose it to a fuller range of varied tasks before I fully commit to the update. ID: 1826284 · |

©2024 University of California
SETI@home and Astropulse are funded by grants from the National Science Foundation, NASA, and donations from SETI@home volunteers. AstroPulse is funded in part by the NSF through grant AST-0307956.