Script for Affinity & Priority Management
Message boards :
Number crunching :
Script for Affinity & Priority Management
Message board moderation
Previous · 1 · 2 · 3 · Next
| Author | Message |
|---|---|
 Karsten Vinding Karsten Vinding Send message Joined: 18 May 99 Posts: 239 Credit: 25,201,931 RAC: 11 
|
Don't mind, read my next post. ID: 1346212 · |
|
Karsten Vinding Send message Joined: 18 May 99 Posts: 239 Credit: 25,201,931 RAC: 11
|
After looking at Raistmers results I decided to try it with 8 cores active with no affinity, and with GPU affinity set to core 0 (with Prolaso). I got this: 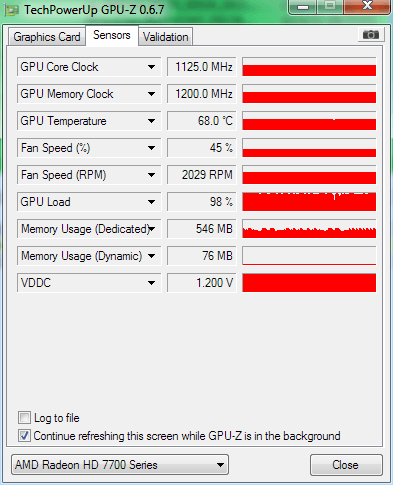 With 7 cores active, affinity set to cores 1-7, and GPU on 0 I got this. 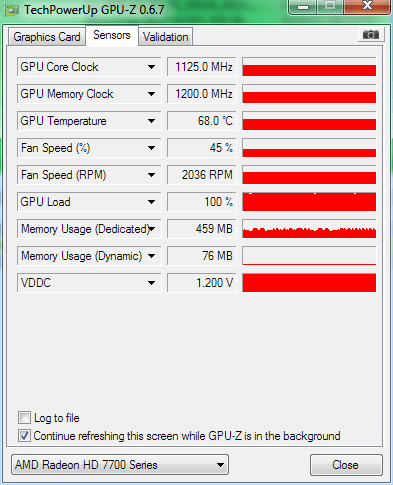 There is a _small_ difference. Probably 3-4% This is a much better result than what I saw yesterday, probably because yesterday I locked the GPU to core 1 instead of core 0. Probably because I misunderstood something in the process. Now I havent seen a heavy blanked WU yet, or seen if the GPU usage bug rears it head again, but if this keeps looking this good, I will probably be crunching on all cylinders again. And be happy doing it :) It must be said that these are AP WU's being crunched, I dont know how MB will react. ID: 1346218 · |
|
Raistmer Send message Joined: 16 Jun 01 Posts: 6325 Credit: 106,370,077 RAC: 121 
|
My benchmark was on MB app. But much more statistic required cause the real problem with full CPU loaded were intermittent slowdowns. Time to time app execution time increased considerably, in times. That was called "low GPU usage bug". If app performance will remain steady then yes, full CPU load with such affinity settings would be attractive config. Also, currently I run (mostly AP) in config 1 free CPU core + 2 AP tasks at once (on Q9450 + HD6950 host). And host RAC goes up as a rocket, even no sign of stabilization still. Perhaps each GPU app should be pinned to different CPU core, not both to core0. How to test this with ProcessLasso - not quite clear. cov_route, could you post example of your script config for this particular case, please? 4 CPU cores, 2 GPU app instances, each instance pinned to own core, CPU apps affinity unspecified. SETI apps news We're not gonna fight them. We're gonna transcend them. ID: 1346228 · |
|
cov_route Send message Joined: 13 Sep 12 Posts: 342 Credit: 10,270,618 RAC: 0 
|
Raistmer: change the names of the apps as required. The CPU app must be first, the GPU second. Each GPU will get it's own core 0-3, CPU's will all be 0,1,2,3. All priorities below normal.
$pri_names = @( `
"Idle",`
"BelowNormal",`
"Normal",`
"AboveNormal",`
"High",`
"RealTime")
$proc_names = @( `
"AK_v8b2_win_sse3_amd",`
"MB7_win_x86_SSE_OpenCL_ATi_HD5_r1764")
$pri_actv = @( `
@(1,1), `
@(1,1))
$pri_inac = @( `
@(1,1), `
@(1,1))
$aff_actv = @( `
@(15), `
@(1,2,4,8))
$aff_inac = @( `
@(15), `
@(1,2,4,8))
If you want CPU priority idle and GPU priority below normal use:
$pri_actv = @( `
@(0,0), `
@(1,1))
$pri_inac = @( `
@(0,0), `
@(1,1))
For extra fanciness if you want the CPU priority to be below normal except when it shares a core with the GPU job when it should be idle, use:
$pri_actv = @( `
@(1,0), `
@(1,1))
$pri_inac = @( `
@(1,0), `
@(1,1))
ID: 1346348 · |
|
cov_route Send message Joined: 13 Sep 12 Posts: 342 Credit: 10,270,618 RAC: 0
|
A fix for a possible bug that prevents setting priorities and added configuration instructions. https://www.box.com/s/ir2hx9e08k88kz3tq77p ID: 1346717 · |
|
Karsten Vinding Send message Joined: 18 May 99 Posts: 239 Credit: 25,201,931 RAC: 11
|
Well, sadly today the performance according to GPU-z was down again to between 85 and 92%, and never reached 100%. Removing one CPU thread helped a little. But to get back to 100% GPU usage I had to go back to crunching on 6 cores, and give GPU 2 free cores. Now I'm at 99-100% again. Its a little frustrating that the system reacts so differently from day to day, and I dont see any pattern to it. ID: 1346757 · |
|
Horacio Send message Joined: 14 Jan 00 Posts: 536 Credit: 75,967,266 RAC: 0 
|
Well, sadly today the performance according to GPU-z was down again to between 85 and 92%, and never reached 100%. What about the crunching times? I mean, Is that extra 15% on GPU usage worth enough to loose 2 CPU cores? 
ID: 1346768 · |
|
Mike Send message Joined: 17 Feb 01 Posts: 34257 Credit: 79,922,639 RAC: 80 
|
If you read readme text from the OpenCL apps its a known fact that on new drivers its necessary to free at least one CPU core. I also have to free 2 cores on my FX 8150. Yes it is worth. I did long run tests and it is confirmed. With each crime and every kindness we birth our future. ID: 1346787 · |
|
Raistmer Send message Joined: 16 Jun 01 Posts: 6325 Credit: 106,370,077 RAC: 121
|
Do you account for different input data patterns for app itself? It's known fact that not all input data can be processed evenly good with current GPU apps. SETI apps news We're not gonna fight them. We're gonna transcend them. ID: 1346790 · |
|
Karsten Vinding Send message Joined: 18 May 99 Posts: 239 Credit: 25,201,931 RAC: 11
|
I don't and I don't think I can. It's not a criticism of the apps or the work the developers do. It's frustration over the fact that you cannot get your crunching up to the _full_ potential, because of some obscure bug or decission made by the driver developers. I have to run with two cores disabled to have the highest throughput on average. But I'm convinced that if the AMD (and nVidia) developers worked on this, this problem could be removed or at least reduced to a point where we could use all cores, and stil have full GPU utilization. ID: 1346865 · |
|
Claggy Send message Joined: 5 Jul 99 Posts: 4654 Credit: 47,537,079 RAC: 4 
|
He means the Angle Range (or % of Blanking for AP) of the Wu in Question, you can find that out by looking at the Result once you're reported it. For AP, GPU load is heavily related to the % of Blanking, the more Blanking the less the GPU load and the longer the Wu will take. (The Blanking portion of the task is carried out on the CPU, which slows everything down). Claggy ID: 1346884 · |
|
cov_route Send message Joined: 13 Sep 12 Posts: 342 Credit: 10,270,618 RAC: 0
|
It may (or may not) be possible to wring the last 10% of performance out of a GPU with the task assigned to a single core, I don't know. On my machine I run like that with all cores processing CPU jobs and GPU utilization is consistently 96-100%. But it's only one (slightly dated) machine. (Note that I had to experiment to find the right app and driver combination -r1764 + 12.8- to make it work so well, so it's not just a matter of core config). If things work out, the real benefit will be fixing the GPU utilization bug, not optimization. As things are now under the default settings a user might see his GPU drop to very low utilizations, like 10% (I've had that). And many or most of those users will never know it because they don't check and don't know HOW to check. They just expect SAH to work out of the box. If the GPU app default settings could get the utilization up over, say, 70% all the time that would be a big change for the positive in my opinion. ID: 1346890 · |
|
Horacio Send message Joined: 14 Jan 00 Posts: 536 Credit: 75,967,266 RAC: 0
|
If you read readme text from the OpenCL apps its a known fact that on new drivers its necessary to free at least one CPU core. I know that, but they are testing a different approach using the affinities to avoid reserving cores. And while Im skeptic about this approach, I think that using only the GPU utilization as parameter its not a good meassurement of its efficacy...
ID: 1346906 · |
|
Raistmer Send message Joined: 16 Jun 01 Posts: 6325 Credit: 106,370,077 RAC: 121
|
Agree. To not slowdown improvements and testing because my own lack of time I will provide CPUlock with changed (to 1 core instead of 2) logic soon. Then all can test this approach more easely, just by setting corresponding switch. And if testing will be positive this switch will be on by default on next stock update. SETI apps news We're not gonna fight them. We're gonna transcend them. ID: 1347260 · |
|
Raistmer Send message Joined: 16 Jun 01 Posts: 6325 Credit: 106,370,077 RAC: 121
|
Here is build with new CPUlock behavior. Also, new option added to bind to the same CPU instead of different ones. Look ReadMe for usage info. Please test if it can help with GPU load on fully loaded CPU (switches usage required, CPUlock is OFF by default for now). https://dl.dropbox.com/u/60381958/AP6_win_x86_SSE2_OpenCL_ATI_r1785.7z SETI apps news We're not gonna fight them. We're gonna transcend them. ID: 1348089 · |
|
cov_route Send message Joined: 13 Sep 12 Posts: 342 Credit: 10,270,618 RAC: 0
|
Thank you Raistmer I will get to it tonight. ID: 1348111 · |
|
cov_route Send message Joined: 13 Sep 12 Posts: 342 Credit: 10,270,618 RAC: 0
|
I tried using -cpu_lock with 2 instances and it ran with affinity 1,2,3,4. Are there other switches I need to set? ID: 1348327 · |
|
Raistmer Send message Joined: 16 Jun 01 Posts: 6325 Credit: 106,370,077 RAC: 121
|
I tried using -cpu_lock with 2 instances and it ran with affinity 1,2,3,4. Are there other switches I need to set? yes, per Readme another switches are needed too. But here: https://dl.dropbox.com/u/60381958/AP6_win_x86_SSE2_OpenCL_ATI_r1786.7z simplified version. Now -cpu_lock needs only -instances_per_device N if more than 1 task per GPU and -cpu_lock_fixed_cpu N doesn't need additional switches at all. Try this binary. SETI apps news We're not gonna fight them. We're gonna transcend them. ID: 1348433 · |
|
cov_route Send message Joined: 13 Sep 12 Posts: 342 Credit: 10,270,618 RAC: 0
|
Couldn't get on last night to post my findings. 1786 doesn't work on my machine, it exits after a few seconds. However I was able to observe the affinity behaviour during that brief time. -cpu_lock doesn't seem to work for me. I always get 1,2,3,4. Tried with and without -instances_per_device. -cpu_lock_fixed_cpu does work. Here is part of the bench output for -cpu_lock: AP6_win_x86_SSE2_OpenCL_ATI_r1786.exe -cpu_lock / short_ap_21oc08ab_B2_P0_00081_20081130_08605.wu : AppName: AP6_win_x86_SSE2_OpenCL_ATI_r1786.exe AppArgs: -cpu_lock TaskName: short_ap_21oc08ab_B2_P0_00081_20081130_08605.wu Started at : 21:28:37.231 Ended at : 21:28:42.237 4.912 secs Elapsed 0.641 secs CPU time ref-AP6_win_x86_SSE2_OpenCL_ATI_r1761.exe-short_ap_21oc08ab_B2_P0_00081_20081130_08605.wu.res: <ap_signal>40,<pulses>30,<best_pulses>10 result-AP6_win_x86_SSE2_OpenCL_ATI_r1786.exe-short_ap_21oc08ab_B2_P0_00081_20081130_08605.wu.res: <ap_signal>0,<pulses>0,<best_pulses>0 All Signals: Weakly similar or Different. Pulses: pulse at signal 0 has no match (direction -->) Weakly similar or Different. Best Pulses: Weakly similar or Different. -(.\testDatas\ref\ref-AP6_win_x86_SSE2_OpenCL_ATI_r1761.exe-short_ap_21oc08ab_B2_P0_00081_20081130_08605.wu.res)- Reportable Single Pulses: 0 [OK], 0 above threshold*THRESHOLD_FUDGE Reportable Repeating Pulses: 30 [Weak] Single Pulses (Best): 0 [OK], 0 above threshold*THRESHOLD_FUDGE -(.\testDatas\result-AP6_win_x86_SSE2_OpenCL_ATI_r1786.exe-short_ap_21oc08ab_B2_P0_00081_20081130_08605.wu.res)- Reportable Single Pulses: 0 [OK], 0 above threshold*THRESHOLD_FUDGE Reportable Repeating Pulses: 0 [Weak] Single Pulses (Best): 0 [OK], 0 above threshold*THRESHOLD_FUDGE [ stderr ] 21:28:37 (3304): Can't open init data file - running in standalone mode CPU affinity adjustment enabled 21:28:37 (3304): Can't open init data file - running in standalone mode Priority of worker thread raised successfully Priority of process adjusted successfully, below normal priority class used 21:28:37 (3304): Can't open init data file - running in standalone mode OpenCL platform detected: Advanced Micro Devices, Inc. WARNING: BOINC supplied wrong platform! BOINC assigns device 0 WARNING: BOINC failed to provide OpenCL device, using own enumeration abilities Used GPU device parameters are: Number of compute units: 6 Single buffer allocation size: 256MB max WG size: 256 Info: CPU affinity mask used: 0 ID: 1348939 · |
|
Raistmer Send message Joined: 16 Jun 01 Posts: 6325 Credit: 106,370,077 RAC: 121
|
Ok, thanks for info. I thought it should work in such config. Please try also with this cmd line: -cpu_lock -gpu_lock -instances_num 1 SETI apps news We're not gonna fight them. We're gonna transcend them. ID: 1348979 · |

©2024 University of California
SETI@home and Astropulse are funded by grants from the National Science Foundation, NASA, and donations from SETI@home volunteers. AstroPulse is funded in part by the NSF through grant AST-0307956.