A Modest Proposal for Easy FREE Bandwidth Relief
Message boards :
Number crunching :
A Modest Proposal for Easy FREE Bandwidth Relief
Message board moderation
| Author | Message |
|---|---|
Cruncher-American  Send message Joined: 25 Mar 02 Posts: 1513 Credit: 370,893,186 RAC: 340 
|
I think that the main reason SETI uses so much bandwidth is the number of shorties that we are inundated with lately. Without that, we would be using much less BW. Example: my 2 crunchers. Each has 2 GTX 460s running two threads each, so I am crunching 8 WUs at once. On my machines, a shortie takes roughly 5 minutes, so I do about 100/hour. So I cause d/l of about 36MB/hour when doing shorties - 10KB/sec just for me. So I am using roughly 1/100 of the available BW all by myself. No wonder things get clogged up! When I do regular WUs (15-20 minutes each) I use 1/3 to 1/4 that much BW. So here's a proposal for a BW workaround: send shorties only to CPUs, just like VLARs! Then they will take much longer to do, so the BW becomes less choked. It can't be much of a programming change, since the servers are aware that shorties are shorties, by estimated GFLOPs. Alternatively, or in addition, they could be stored for sending when things are less hectic - a 2TB drive could hold > 5 million of them in reserve. The amount of science being done (measured by GFLOPs) wouldn't change, just the use of BW. What do you think? ID: 1334639 · |
|
Josef W. Segur Send message Joined: 30 Oct 99 Posts: 4504 Credit: 1,414,761 RAC: 0
|
It's probably a reasonable idea for a temporary workaround. Note however that even before there was an Astropulse application or any GPU crunching a shortie storm caused problems. That was likely with Thumper and Jocelyn doing BOINC database duties, Oscar and Carolyn have better capabilities (but so do the CPUs on users' hosts). The other negative point is there would likely be times when GPUs would run dry because all tapes being split were producing only VLAR or VHAR tasks. Joe ID: 1334670 · |
|
Cruncher-American Send message Joined: 25 Mar 02 Posts: 1513 Credit: 370,893,186 RAC: 340
|
In that case, if all MB WUs being produced were shorties, at least they wouldn't be fighting with other MB WUs for use of the BW. Surely, the servers could detect this situation ("we have no more stuff for GPUs") and allow some shorties to flow to graphics cards. ID: 1334673 · |
|
Tom* Send message Joined: 12 Aug 11 Posts: 127 Credit: 20,769,223 RAC: 9
|
Thank you JRavin for an eminently sensible but temp idea, until we can get co-located or procure more bandwidth. As far as running out of GPU tasks We do that all the time with our current problems. Bill ID: 1334676 · |
|
Cruncher-American Send message Joined: 25 Mar 02 Posts: 1513 Credit: 370,893,186 RAC: 340
|
IIRC, more bandwidth is more a political problem at Berkeley than a technical one, so it may not happen for a LONG time. That's why I thought this up. And: you're welcome! ID: 1334702 · |
 Link Link Send message Joined: 18 Sep 03 Posts: 834 Credit: 1,807,369 RAC: 0 
|
Example: my 2 crunchers. Each has 2 GTX 460s running two threads each, so I am crunching 8 WUs at once. On my machines, a shortie takes roughly 5 minutes, so I do about 100/hour. So I cause d/l of about 36MB/hour when doing shorties - 10KB/sec just for me. So I am using roughly 1/100 of the available BW all by myself. No wonder things get clogged up! When I do regular WUs (15-20 minutes each) I use 1/3 to 1/4 that much BW. This ratio is about the same for CPUs, "normal" AR WU takes about 3-4 times longer than VHAR. If we consider the total available computing power constant, sending shorties to CPUs won't help with anything, you will download less data for your GPUs and more for the CPUs. 
ID: 1334706 · |
|
HAL9000 Send message Joined: 11 Sep 99 Posts: 6534 Credit: 196,805,888 RAC: 57
|
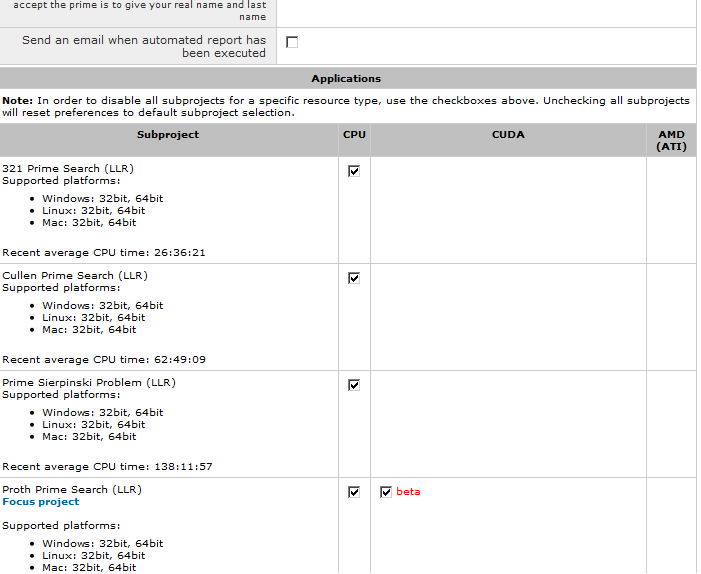
Perhaps they could tag tasks as VHAR like they do with VLAR & then setup sub projects for each type. I'm thinking something like how Primegrid works. Example for those that don't run that project. http://www.hal6000.com/seti/images/pg_subs.png Then users could disable/enable their hardware for each type. Seti@Home Enhanced VHAR Seti@Home Enhanced Seti@Home Enhanced VLAR Seti@Home v7 VHAR Seti@Home v7 Seti@Home v7 VLAR SETI@home v7 large workunits Astropulse v6 This might be useful if we hit another issue like Nvidia cards choking on VLAR work. Then that selection could be removed/disabled or something along those lines. SETI@home classic workunits: 93,865 CPU time: 863,447 hours  Join the [url=http://tinyurl.com/8y46zvu]BP6/VP6 User Group[ Join the [url=http://tinyurl.com/8y46zvu]BP6/VP6 User Group[
ID: 1334708 · |
|
Cruncher-American Send message Joined: 25 Mar 02 Posts: 1513 Credit: 370,893,186 RAC: 340
|
Example: my 2 crunchers. Each has 2 GTX 460s running two threads each, so I am crunching 8 WUs at once. On my machines, a shortie takes roughly 5 minutes, so I do about 100/hour. So I cause d/l of about 36MB/hour when doing shorties - 10KB/sec just for me. So I am using roughly 1/100 of the available BW all by myself. No wonder things get clogged up! When I do regular WUs (15-20 minutes each) I use 1/3 to 1/4 that much BW. No - because work on CPUs is much slower than GPUs (by a factor of roughly 10:1 in my case). So fewer shorties will be needed to be sent to CPUs per unit time, and more normal WUs will go to GPUs, but the ratios should be more favorable. Example: On my machines, shorty is 5 minutes on GPU, 50 minutes on CPU, normal WU is roughly 2 hours on CPU but 12 minutes on GPU. Say 4 cores of CPU and 4 threads of GPU. Then, in an hour (now) 100 shorties on GPU, 2 normals on CPU. If we reverse that, we have about 5 shorties on CPU and 20 normals on GPU, so we need to send only about 1/4 the total amount of data. Of course, YMMV. The problem is that most shorties seem to be marked for GPU, not CPU, which is causing the BW problem. ID: 1334711 · |
|
bill Send message Joined: 16 Jun 99 Posts: 861 Credit: 29,352,955 RAC: 0
|
(snippage) Not all Nvidia cards choke on VLARs. It would be nice people that should know better would quit regurgitating this untruth. ID: 1334712 · |
|
Cruncher-American Send message Joined: 25 Mar 02 Posts: 1513 Credit: 370,893,186 RAC: 340
|
Perhaps they could tag tasks as VHAR like they do with VLAR & then setup sub projects for each type. I'm thinking something like how Primegrid works. Except that more casual users might be confused by too many options. But certainly a future possibility, and I like it. My idea is simply to (for now) bias where shorties are sent, so big crunchers (helloooo msattler) don't suck up all the BW because they fly through shorties on their GPUs. ID: 1334715 · |
|
Link Send message Joined: 18 Sep 03 Posts: 834 Credit: 1,807,369 RAC: 0
|
Example: On my machines, shorty is 5 minutes on GPU, 50 minutes on CPU, normal WU is roughly 2 hours on CPU but 12 minutes on GPU. Say 4 cores of CPU and 4 threads of GPU. Then, in an hour (now) 100 shorties on GPU, 2 normals on CPU. If we reverse that, we have about 5 shorties on CPU and 20 normals on GPU, so we need to send only about 1/4 the total amount of data. Yes, 1/4 to your computer, but the remaining 95 shorties have to be done by CPUs, which will download 4x more compared to crunching normal WUs. So globally you don't gain anything, that's simply impossible. The amount of data stays the same, the available computing power stays the same, unless we consider idle GPUs in case of VHAR+VLAR storm. Remember that the splitters stop generating new work if enough WUs are available, so if we also stop sending VHARs to GPUs, they will have to wait more often untill the CPUs finished all GPU-incompatible tasks. I don't think you want that.
ID: 1334718 · |
|
Wiggo Send message Joined: 24 Jan 00 Posts: 34744 Credit: 261,360,520 RAC: 489 
|
Example: my 2 crunchers. Each has 2 GTX 460s running two threads each, so I am crunching 8 WUs at once. On my machines, a shortie takes roughly 5 minutes, so I do about 100/hour. So I cause d/l of about 36MB/hour when doing shorties - 10KB/sec just for me. So I am using roughly 1/100 of the available BW all by myself. No wonder things get clogged up! When I do regular WUs (15-20 minutes each) I use 1/3 to 1/4 that much BW. A shorty on my 2500K only lasts for 20mins. Cheers. ID: 1334719 · |
|
Lionel Send message Joined: 25 Mar 00 Posts: 680 Credit: 563,640,304 RAC: 597
|
there is also reschedule... ID: 1334723 · |
|
Wiggo Send message Joined: 24 Jan 00 Posts: 34744 Credit: 261,360,520 RAC: 489
|
That's not even going to be considered here, full stop. Cheers. ID: 1334726 · |
|
Vipin Palazhi Send message Joined: 29 Feb 08 Posts: 286 Credit: 167,386,578 RAC: 0 
|
Has anyone considered the options of splitting and distributing the work units from a location other than berkeley? It will then redirect a good amount of 'outbound' data away from these overloaded berkeley bandwidth. The completed WUs will only be reported back to berkeley. ID: 1334744 · |
|
bill Send message Joined: 16 Jun 99 Posts: 861 Credit: 29,352,955 RAC: 0
|
http://setiathome.berkeley.edu/forum_thread.php?id=70718 You might want to read the first post in that thread. ID: 1334750 · |
|
Vipin Palazhi Send message Joined: 29 Feb 08 Posts: 286 Credit: 167,386,578 RAC: 0
|
Thanks for that link bill. However, that means the servers are still located within the berkeley network, clogged by all the politics going on. I do remember reading someone offering to host some of the servers for free. Now, I am no expert in this area, just thinking out loud. Apologies if the above point has already been discussed. ID: 1334754 · |
|
Donald L. Johnson Send message Joined: 5 Aug 02 Posts: 8240 Credit: 14,654,533 RAC: 20
|
Has anyone considered the options of splitting and distributing the work units from a location other than berkeley? It will then redirect a good amount of 'outbound' data away from these overloaded berkeley bandwidth. The completed WUs will only be reported back to berkeley. While Matt's post refers to a possible move to a facility away from teh Space Science Lab but still on the Berkeley campus, the suggestion to move the splitters and Work Unit distribution equipment off-campus has been previously discussed here, and found to be a non-starter for a number of reasons, the two main ones being, IIRC, cost and data security. You'll have to do a Forum search to find the discussion threads, it's been awhile since we last batted the idea around. Donald Infernal Optimist / Submariner, retired ID: 1334755 · |
|
HAL9000 Send message Joined: 11 Sep 99 Posts: 6534 Credit: 196,805,888 RAC: 57
|
(snippage) I am aware it only is an issue for some devices. I was using that as an example because it was a significant issue to cause a change in the project. I would not mind seeing a way to limit or stop or limit VLAR tasks to my 24 core box. As it tends to get rather unresponsive running 24 VLAR's at once. VHAR's it chews through like a mad man. SETI@home classic workunits: 93,865 CPU time: 863,447 hours Join the [url=http://tinyurl.com/8y46zvu]BP6/VP6 User Group[
ID: 1334928 · |
|
bill Send message Joined: 16 Jun 99 Posts: 861 Credit: 29,352,955 RAC: 0
|
(snippage) To me, it just seems wrong to post incorrect information, especially in a science forum. Perhaps if there were more gpus spending more time working on vlars instead of burning through vhars there might be less hammering on the servers. Just a thought. ID: 1334958 · |
{kind=link}

©2024 University of California
SETI@home and Astropulse are funded by grants from the National Science Foundation, NASA, and donations from SETI@home volunteers. AstroPulse is funded in part by the NSF through grant AST-0307956.