Panic Mode On (79) Server Problems?
Message boards :
Number crunching :
Panic Mode On (79) Server Problems?
Message board moderation
Previous · 1 . . . 8 · 9 · 10 · 11 · 12 · 13 · 14 . . . 22 · Next
| Author | Message |
|---|---|
|
Horacio Send message Joined: 14 Jan 00 Posts: 536 Credit: 75,967,266 RAC: 0 
|
What I think is that besides the underlying issue, the current limits are not helping as they should. My hosts, even the one that has a core 2 duo and an old gt9500, is doing a request every five minutes, and Im sure that the same happens in hughe number of active host so, they changed a few long queries by a lot of short ones. And, while the need of a certain limit is out discussion, unless until they can solve the underlying issue, may be a slightly higher limit can give a beter trade of between the duration of the queries and the number of them... 
ID: 1310500 · |
 HAL9000 HAL9000 Send message Joined: 11 Sep 99 Posts: 6534 Credit: 196,805,888 RAC: 57 
|
Quick script to provide the percentage of failures on your machine. At the moment this will work correctly if the stdoutdae.txt only contains the current months information. Otherwise matching day information for other months & years will be included. Dealing with dates in a .bat file can be a pain. I might have to go with .vbs to make things easier. I did update it to separate the dates & allow users to enter the number of days they wish to view. 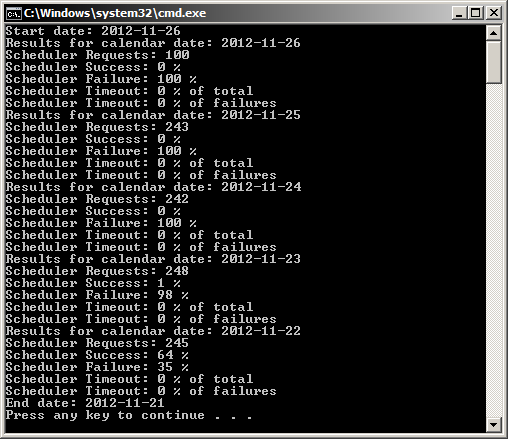 If anyone wishes to use it you can find it here: http://www.hal6000.com/seti/_com_check_full.txt Right click & save, depending on your browser, rename to .bat. Then place in the folder where your stdoutdae.txt is located, or modify the script to point to the location of the file. Change the number on the line "set check_days=" for the number of days you wish to view. If you wish you can remove the line "del sched_*-%computername%_*.txt" to save the daily information. You can then use this script, http://www.hal6000.com/seti/_com_check_day_calc.txt, to run each day separately by entering the date from the command line in YYYY-MM-DD format. So entering, _com_check_day_calc.bat 2012-11-26, with the sched_*-PCNAME_2012-11-26.txt files present would give you that days information. SETI@home classic workunits: 93,865 CPU time: 863,447 hours  Join the [url=http://tinyurl.com/8y46zvu]BP6/VP6 User Group[ Join the [url=http://tinyurl.com/8y46zvu]BP6/VP6 User Group[
ID: 1310509 · |
Richard Haselgrove  Send message Joined: 4 Jul 99 Posts: 14650 Credit: 200,643,578 RAC: 874 
|
I've been aggregating the stdoutdae.txt files from five computers, and splitting them up into batches by date. First, covering the period from 01 Nov to 20 Nov inclusive - near enough, from when the acute problems started, to when Eric switched to the Campus network last Wednesday. Scheduler Requests: 10334 Scheduler Successes: 7341 Scheduler Failures (Connect): 221 Scheduler Failures (Peer data): 62 Scheduler Failures (Timeout): 2659 Scheduler Success: 71 % Scheduler Failure: 28 % Scheduler Connect: 7 % of failures Scheduler Peer data: 2 % of failures Scheduler Timeout: 88 % of failures Then, on Saturday morning (Berkeley time), the scheduler came back online, but back on the old HE/PAIX IP address. Since then... Scheduler Requests: 1109 Scheduler Successes: 349 Scheduler Failures (Connect): 597 Scheduler Failures (Peer data): 131 Scheduler Failures (Timeout): 28 Scheduler Success: 31 % Scheduler Failure: 68 % Scheduler Connect: 78 % of failures Scheduler Peer data: 17 % of failures Scheduler Timeout: 3 % of failures So, it's actually been easier to get work here over the weekend than for several weeks past - there have been more errors in total, but the vast majority have been of the 20-second 'Connect' variety, instead of the 5-minute 'Timeout' variety. And with a 'connect' failure, the database knows nothing about your attempt, so no ghosts are created. ID: 1310519 · |
|
Grant (SSSF) Send message Joined: 19 Aug 99 Posts: 13732 Credit: 208,696,464 RAC: 304 
|
So, it's actually been easier to get work here over the weekend than for several weeks past - there have been more errors in total, but the vast majority have been of the 20-second 'Connect' variety, instead of the 5-minute 'Timeout' variety. And with a 'connect' failure, the database knows nothing about your attempt, so no ghosts are created. Things are certainly better than they were, but not as good as when the campus network was being used. At least most of the time- we're back in one of those major network traffic dives, hoping for yet again another recovery. Grant Darwin NT ID: 1310527 · |
|
Horacio Send message Joined: 14 Jan 00 Posts: 536 Credit: 75,967,266 RAC: 0
|
So, it's actually been easier to get work here over the weekend than for several weeks past - there have been more errors in total, but the vast majority have been of the 20-second 'Connect' variety, instead of the 5-minute 'Timeout' variety. And with a 'connect' failure, the database knows nothing about your attempt, so no ghosts are created. Which gives sense to my guess that we are overloading the scheduller with more requests than it's able to handle... (my raw estimation is that if 20% of the active hosts are trying to do a RPC every 6 mins, the scheduller should be able to process 120 RPCs per second... I guess that no matter if a lot of people spells BOINC as BIONIC anyway we don't have the technology... (neither the six million dollars)
ID: 1310529 · |
|
Richard Haselgrove Send message Joined: 4 Jul 99 Posts: 14650 Credit: 200,643,578 RAC: 874
|
So, it's actually been easier to get work here over the weekend than for several weeks past - there have been more errors in total, but the vast majority have been of the 20-second 'Connect' variety, instead of the 5-minute 'Timeout' variety. And with a 'connect' failure, the database knows nothing about your attempt, so no ghosts are created. If you look carefully at the SSP, you'll see that the AP splitter processes have gone walkabout to Vader, Marvin, GeorgeM... I think the traffic dive may be to do with reconfigurations in progress. ID: 1310536 · |
|
Grant (SSSF) Send message Joined: 19 Aug 99 Posts: 13732 Credit: 208,696,464 RAC: 304
|
So, it's actually been easier to get work here over the weekend than for several weeks past - there have been more errors in total, but the vast majority have been of the 20-second 'Connect' variety, instead of the 5-minute 'Timeout' variety. And with a 'connect' failure, the database knows nothing about your attempt, so no ghosts are created. Possibly- it's now bottommed out, which it hadn't done on the previous dives it recovered from. Grant Darwin NT ID: 1310538 · |
juan BFP  Send message Joined: 16 Mar 07 Posts: 9786 Credit: 572,710,851 RAC: 3,799 
|
Finaly they start to do what we tell them to do about 2 weeks ago..... Unload some tasks from the poor overloaded Synergy! At least now we see a light on the end of the tunnel... 
ID: 1310554 · |
|
kittyman Send message Joined: 9 Jul 00 Posts: 51468 Credit: 1,018,363,574 RAC: 1,004
|
Finaly they start to do what we tell them to do about 2 weeks ago..... Let's just hope that it's not the light from another oncoming train....LOL. "Freedom is just Chaos, with better lighting." Alan Dean Foster 
ID: 1310555 · |
|
rob smith Send message Joined: 7 Mar 03 Posts: 22190 Credit: 416,307,556 RAC: 380
|
It certainly looks as if some serious re-knitting is being done. Here's to hoping it is a success. Bob Smith Member of Seti PIPPS (Pluto is a Planet Protest Society) Somewhere in the (un)known Universe? ID: 1310556 · |
|
juan BFP Send message Joined: 16 Mar 07 Posts: 9786 Credit: 572,710,851 RAC: 3,799
|
Finaly they start to do what we tell them to do about 2 weeks ago..... Unless you are a Coyote you don´t need to worry! At least i hope... i´m tired with all this... At least i´m happy all hands report no problem with the yesterday power loss... now i´m going to drink few cold beers...
ID: 1310572 · |
|
David S Send message Joined: 4 Oct 99 Posts: 18352 Credit: 27,761,924 RAC: 12
|
What I think is that besides the underlying issue, the current limits are not helping as they should. I never thought the current limit scheme made sense. To have any real effect on network traffic, wouldn't it have to limit tasks over a specific time period rather than just "at a time"? I hate to say that, despite what the higher-crediting Einstein units are doing for my overall Boinc stats (and even with 99 Einstein units "aborted by user," which I certainly didn't do), but to me it's the only thing that will achieve the desired outcome. David Sitting on my butt while others boldly go, Waiting for a message from a small furry creature from Alpha Centauri. ID: 1310589 · |
|
David S Send message Joined: 4 Oct 99 Posts: 18352 Credit: 27,761,924 RAC: 12
|
The next big question is, why can't I get page 2 of this thread to load completely? David Sitting on my butt while others boldly go, Waiting for a message from a small furry creature from Alpha Centauri. ID: 1310591 · |
|
HAL9000 Send message Joined: 11 Sep 99 Posts: 6534 Credit: 196,805,888 RAC: 57
|
What I think is that besides the underlying issue, the current limits are not helping as they should. They are not trying to effect the network traffic. The limits were put in place to reduce the size of the result and host tables. As they had grown to large to complete in a timely fashion. Hopefully they will come up with a long term solution. Hopefully by breaking up the tables into sizes that can be quickly searched. SETI@home classic workunits: 93,865 CPU time: 863,447 hours Join the [url=http://tinyurl.com/8y46zvu]BP6/VP6 User Group[
ID: 1310597 · |
|
dancer42 Send message Joined: 2 Jun 02 Posts: 455 Credit: 2,422,890 RAC: 1
|
After reading what everyone has been saying here I watched the log file over night and noticed that the boinc manager poled the scheduler several times an hour far more often then would seem to make any since. If instead of polling 10 to 50 times an hour perhaps a line could be added to preferences to set a minimum number of unit's before reporting we could then set that number higher when high traffic threatened to bring the scheduling server down. I am thinking the unnecessary polling for 150,000 machines would add a lot two the traffic problems does seti really need to know every signal time I start finish or change any thing? ID: 1310609 · |
|
Horacio Send message Joined: 14 Jan 00 Posts: 536 Credit: 75,967,266 RAC: 0
|
After reading what everyone has been saying here I watched the log file over night and noticed that the boinc manager poled the scheduler several times an hour far more often then would seem to make any since. If instead of polling 10 to 50 times an hour perhaps a line could be added to preferences to set a minimum number of unit's before reporting we could then set that number higher when high traffic threatened to bring the scheduling server down. I am thinking the unnecessary polling for 150,000 machines would add a lot two the traffic problems does seti really need to know every signal time I start finish or change any thing? The clients are not calling the scheduler to report every task, they are calling often because due to the limits their caches are not filled and then they try to get more work to fill them. Of course when the contact is made the already crunched units are reported, but thats just collateral, on normal circumstances and if there is no need for more work, the client will call the scheduler only once every 24 hours to report tasks.
ID: 1310616 · |
|
arkayn Send message Joined: 14 May 99 Posts: 4438 Credit: 55,006,323 RAC: 0
|
Start date: 2012-11-26 Results for calendar date: 2012-11-26 Scheduler Requests: 117 Scheduler Success: 53 % Scheduler Failure: 46 % Scheduler Timeout: 3 % of total Scheduler Timeout: 7 % of failures Results for calendar date: 2012-11-25 Scheduler Requests: 106 Scheduler Success: 44 % Scheduler Failure: 55 % Scheduler Timeout: 4 % of total Scheduler Timeout: 8 % of failures Results for calendar date: 2012-11-24 Scheduler Requests: 11 Scheduler Success: 9 % Scheduler Failure: 90 % Scheduler Timeout: 0 % of total Scheduler Timeout: 0 % of failures Results for calendar date: 2012-11-23 Scheduler Requests: 2 Scheduler Success: 0 % Scheduler Failure: 100 % Scheduler Timeout: 0 % of total Scheduler Timeout: 0 % of failures Results for calendar date: 2012-11-22 Scheduler Requests: 52 Scheduler Success: 75 % Scheduler Failure: 25 % Scheduler Timeout: 0 % of total Scheduler Timeout: 0 % of failures End date: 2012-11-21 Press any key to continue . . . 
ID: 1310617 · |
|
ivan Send message Joined: 5 Mar 01 Posts: 783 Credit: 348,560,338 RAC: 223
|
I find these files in my BOINC area: ----------+ 1 Compaq_Owner None 388941 Nov 26 23:46 sched_request_setiathome.berkeley.edu.xml ----------+ 1 Compaq_Owner None 46092 Nov 26 23:48 sched_reply_setiathome.berkeley.edu.xml From comments I have seen it would appear that the former is sent with each request, to inform the scheduler which workunits the computer thinks it has, to be compared with the master database (to identify ghost units, for example) and the latter must be the reply sent out after a successful request. My question is if these are sent "in the clear" or compressed? I was involved in sending configuration data to and from the configuration database for the MICE experiment two years ago, and I found that XML data is so redundant that it compresses well. Even gzip was great but bz2 doubled the compression ratio on the data I was sending. Trying gzip on the above two files I find: ----------+ 1 Compaq_Owner None 15665 Nov 26 23:46 sched_request_setiathome.berkeley.edu.xml.gz ----------+ 1 Compaq_Owner None 3432 Nov 26 23:57 sched_reply_setiathome.berkeley.edu.xml.gz i.e. compression ratios of up to 25:1. Given that these are for a system with a current 100+100 WU limit, and when it was unfettered it had a stash of a few thousand WUs, the amount of data being transferred can be enormous, if uncompressed. So, are these files transferred for each request? And are they being transferred as-is or with some compression?   
ID: 1310629 · |
|
Richard Haselgrove Send message Joined: 4 Jul 99 Posts: 14650 Credit: 200,643,578 RAC: 874
|
So, are these files transferred for each request? And are they being transferred as-is or with some compression? For each request? Yes, one in each direction. Are they compressed? You would need to ask David Anderson, but I believe not. Remember to factor in the time overhead for compressing and decompressing. At the volunteer's end? It doesn't matter, we provide the hardware and the time. At the server end? Choose an algorithm which runs efficiently on Linux. It might make more sense to compress the request files than the reply files, given the sizes. ID: 1310634 · |
|
ivan Send message Joined: 5 Mar 01 Posts: 783 Credit: 348,560,338 RAC: 223
|
So, are these files transferred for each request? And are they being transferred as-is or with some compression? OK, so I'm not completely barking up the wrong tree.
Yes that's an obvious question to ask. At the moment "some" of us are more convinced that the problem is with network congestion rather than hardware response, so it might be that the reduction in network traffic outweighs the extra computation. Hard to say until you set up a test case. It might make more sense to compress the request files than the reply files, given the sizes. Undoubtedly, go for the lowest-hanging fruit first! Unfortunately the code I worked with for MICE was rather gnarly; I don't remember how much of that was to do with the libraries involved and how much was about the transfer protocols. I can probably recover it (it might even be Googlable[1] if anyone cares) if there's interest. [1] In fact this looks publicly available: http://indico.cern.ch/getFile.py/access?contribId=94&sessionId=6&resId=1&materialId=slides&confId=116711 Apologies if it isn't.
ID: 1310641 · |


©2024 University of California
SETI@home and Astropulse are funded by grants from the National Science Foundation, NASA, and donations from SETI@home volunteers. AstroPulse is funded in part by the NSF through grant AST-0307956.