Windows port of Alex v8 code
Message boards :
Number crunching :
Windows port of Alex v8 code
Message board moderation
Previous · 1 . . . 9 · 10 · 11 · 12 · 13 · 14 · 15 . . . 50 · Next
| Author | Message |
|---|---|
 David David Send message Joined: 19 May 99 Posts: 411 Credit: 1,426,457 RAC: 0 
|
Heck, no way! I really want to get my hands on the new MKWA version (Mac Killing Whale App) and give some of the Mac's a run for their money lol Lol. The next few Intel processors look like nice performers, so it will be interesting to see how they go in real life. I'll be stuck with the poor old Q6600 for a while now - I think the Mrs would shoot me if I upgraded so soon :( 
ID: 732693 · |
|
SATAN Send message Joined: 27 Aug 06 Posts: 835 Credit: 2,129,006 RAC: 0 
|
My Mrs is already threatening to walk out if I spend any more money on Mac's between now and next April. She'll kill me when the import bill for the recent RAM purchase arrives. Think I better find somewhere to hide. 
ID: 732696 · |
|
Seaking57 Send message Joined: 14 Nov 01 Posts: 12 Credit: 76,220,481 RAC: 4 
|
Anyone running JDWhale app. or Jason Gee app. on the Phenom to see if AMD improved on there instruction sets for SSE3 or to test the new SSE4a? I can set mine to stock speed if anyone is interested. I'd just like to thank all the ppl. working on this. Great job! 
ID: 732706 · |
|
JDWhale Send message Joined: 6 Apr 99 Posts: 921 Credit: 21,935,817 RAC: 3
|
So, I'm running WhalePort v0.2 on 4 hosts now, 2 x q6600, 1 x e4500, 1 x p4D-820 I like the charts that Fred W. & plots that archae86 have been posting so much I thought I'd give it a personal touch and tell you a little story of what's in the works for the next 2 weeks. All you with the bigger and faster quads & octos will have your day soon enough, I hope that you don't mind if I get the jump on you and share my experience. One common factor affects my Core2 hosts depicted below. On Mar 08 I suffered MoBo failure. Probably pushing the box a bit too hard. Q6600 running at ~3600MHz (405x9) with DDR-1066 memory pushed to ~1200MHz. Then along the "firebreathing" WU from ehll and took out the MoBo (that's my story and I'm sticking to it, Pilot is my corroborator, check the NC board about that time, you'll see ;-) Next morning was the MoBo/CPU shuffle, thus the behavior changes evident in the charts at that time. Hosts changed names, WU's were ghosted and detatched, clock rates changed, etc...I won't bore you with all the details, but the charts bear witness to the changes in host configurations.  Host = Lovey: E4500 Host = Lovey: E4500This is the mighty E4500 @ 2420Mhz left running WhalePort v0.1 while I was in Las Vegas Mar 23-27 and switched to v0.2 on Mar 28  Host = Wrongway: Q6600 Host = Wrongway: Q6600This host is Q6600 @ 2520MHz switched from SSSE3 R2.4V to WhalePort v0.2 on Mar 28  Host = Thurston: Q6600 Host = Thurston: Q6600This host is Q6600 @ 3200MHz I guess it didn't report results on Mar 27 explaining the deep V before switching to WhalePort v0.2 on Mar 28. This is the host that I have hopes for reaching RAC ~6500 before the next 2 weeks, be warned that I might employ "creative schedueling" if necessary. I will be unhiding hosts as it approaches being the top Q6600 in the "Top Hosts" list in the next couple days, though I'm sure that you can find it in the "Top Hosts" list if you look hard enough. It is also the host that I do development, testing, benchmarking, and browsing on and am using now to compose this message, so I don't feel too guilty about employing that "creative schedueling" to level the playing field a bit. No, I will not be cancelling results for this run to the top, just some results might stray a bit from the default processing order. It's out in the open, I'm telling what I'm going to do, you be the judge.  Host = Skipper: P4D-820 Host = Skipper: P4D-820Lastly we see P4D-820 SSE3 chart, note it's very erratic and with it's just losing its 10 day cache will probably remain that way as Pending Credits will be rising. Thus, this chart bears no witness to the WhalePort effect as the others do. I'm really upset about blowing the cache away yesterday, I think this host could have shown the largest relative benefit, judging from what Fred W. has charted so far. Anyone guess the theme of my LAN/Workgroup ? Kind regards, JDWhale ID: 732728 · |
|
zoom3+1=4 Send message Joined: 30 Nov 03 Posts: 65738 Credit: 55,293,173 RAC: 49
|
So, I'm running WhalePort v0.2 on 4 hosts now, 2 x q6600, 1 x e4500, 1 x p4D-820 Ok Gilligan, You did It again, We're stranded on an Island. BTW: Wrongway(Captain Peachfuzz) should be the Skipper really. Gilligan's Island. The T1 Trust, PRR T1 Class 4-4-4-4 #5550, 1 of America's First HST's 
ID: 732731 · |
|
David Send message Joined: 19 May 99 Posts: 411 Credit: 1,426,457 RAC: 0
|
My Mrs is already threatening to walk out if I spend any more money on Mac's between now and next April. Strictly speaking the NEXT April is tomorrow :D Well it is for Us in Oz - might not quite be the 31st there yet lol)
ID: 732732 · |
|
JDWhale Send message Joined: 6 Apr 99 Posts: 921 Credit: 21,935,817 RAC: 3
|
Wrongway and Lovey swapped CPUs back on that ill-fated March 9 CPU shuffle, we'll call that the morning after the shipwreck. The USB sticks they boot from have the names embedded and are matched to the MoBo, not the CPU. Yes, Lovey was the "naked" PC that there have been pictures posted on the internet. Her MoBo was donated to Thurston when his failed, while her processor is mounted to Wrongway. and the new Lovey was born from the spare parts bin and has since gone thru a number of operations, but she is still naked and likely to become a quad soon (Frys has the Q6600 for $190 in some parts of the country.) Other hosts have included Ginger, MaryAnn, Stubby, and Thurston was once up a time called Professor when I was trying out Ubuntu-64bit. You do remember Stubby, don't you? ID: 732742 · |
|
zoom3+1=4 Send message Joined: 30 Nov 03 Posts: 65738 Credit: 55,293,173 RAC: 49
|
Sorry I don't. The T1 Trust, PRR T1 Class 4-4-4-4 #5550, 1 of America's First HST's
ID: 732743 · |
|
David Send message Joined: 19 May 99 Posts: 411 Credit: 1,426,457 RAC: 0
|
You do remember Stubby, don't you? I do, but I didnt think he was in the original series. Stubby the Monkey was a character in The New Adventures Of Gilligan, an animates series from the late 70's. I think the voice was Lou Scheimer. I cant remember exactly, but I THINK he was Gilligan's pet monkey... That was a LONG time ago lol
ID: 732746 · |
|
[AF>france>pas-de-calais]symaski62 Send message Joined: 12 Aug 05 Posts: 258 Credit: 100,548 RAC: 0 
|
 no cruncher GenuineIntel Intel(R) Pentium(R) Dual CPU E2160 @ 1.80GHz [x86 Family 6 Model 15 Stepping 13] :) SETI@Home Informational message -9 result_overflow with a general handicap of 80% and it makes much d' efforts for the community and s' expimer, thank you d' to be understanding. ID: 732747 · |
|
archae86 Send message Joined: 31 Aug 99 Posts: 909 Credit: 1,582,816 RAC: 0
|
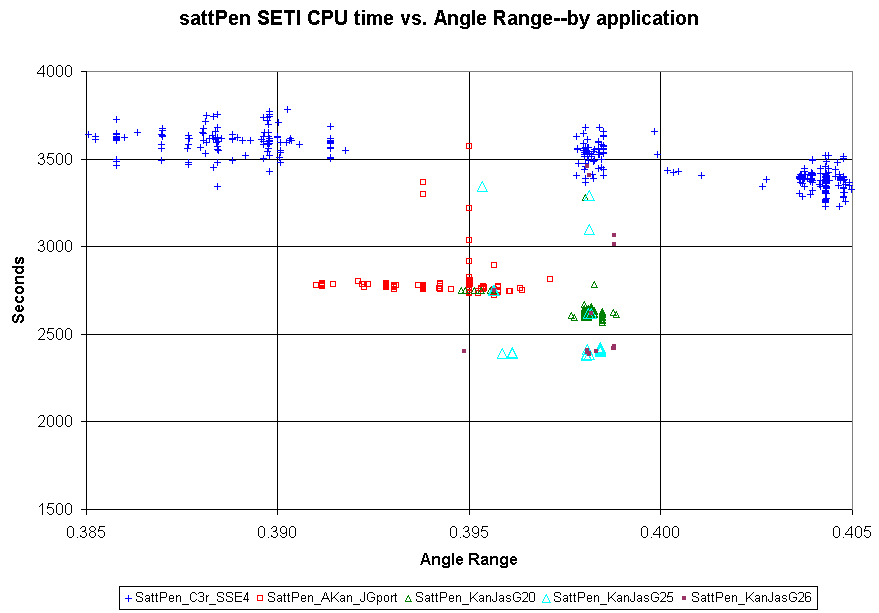
Still running for a few hours.....please do update it....this is amazing stuff.....Before Mark stopped running Jason ports for the day version 25 gave way to version 26. I've updated the two graphs I posted for msattlers "frozen Penny" host running various Jason ports on my Photobucket site, so if you refresh your browser you can see them in their original posts, if you like, or just follow these links: Ports on SatPenn log scale Ports on SatPenn, linear scale near .39 (if you use these direct links, but have view the thread before this post, you may need to refresh your browser after clicking to the link target to get the current version) The version 25/26 CPU times were quite convincingly faster than version 20. On a very limited sample, 26 timings were not obviously different than 25. Version 20 did run a batch down at Angle Range near .01, where it outpointed Chicken ap very convincingly. I've made a new expanded view linear graph for this region: 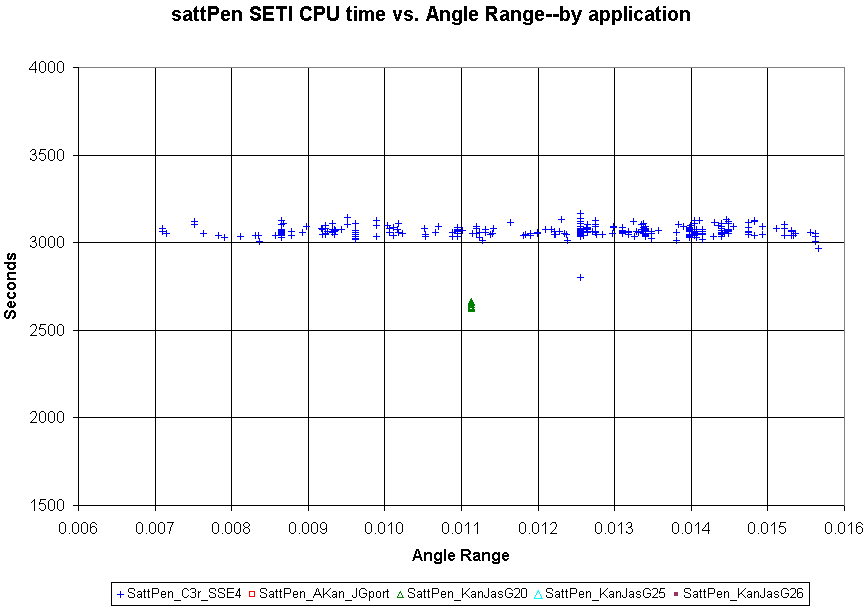 The rev 25 and rev 26 ports, if one ignores the stragglers which almost certainly are ap transition artifacts, have remarkably tight distributions of CPU timings at a given angle range. Possibly this tight distribution is an unusual attribute of the work such as ultra-low noise. But I suspect it may reflect a superiority of the aps use of memory, possibly lowering the time loss to memory or cache contention. ID: 732785 · |
|
archae86 Send message Joined: 31 Aug 99 Posts: 909 Credit: 1,582,816 RAC: 0
|
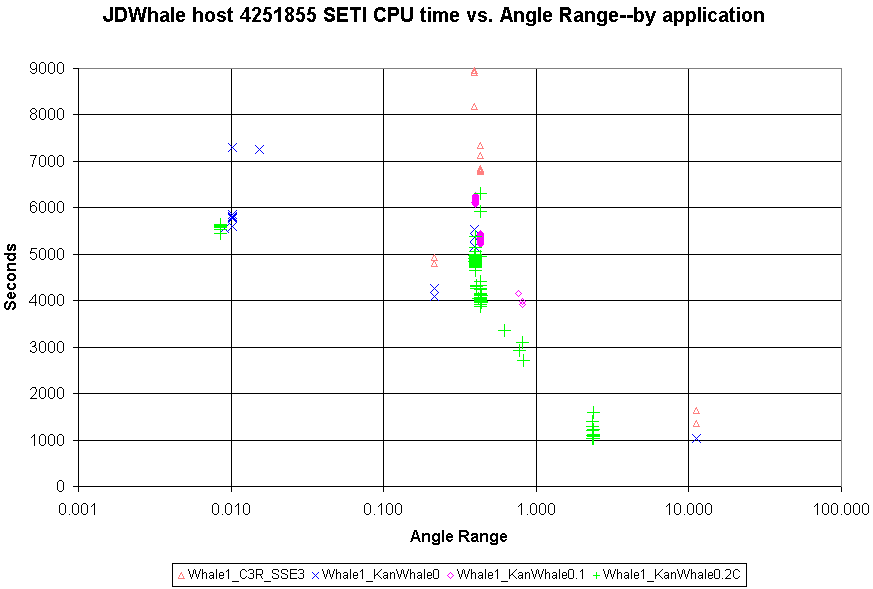
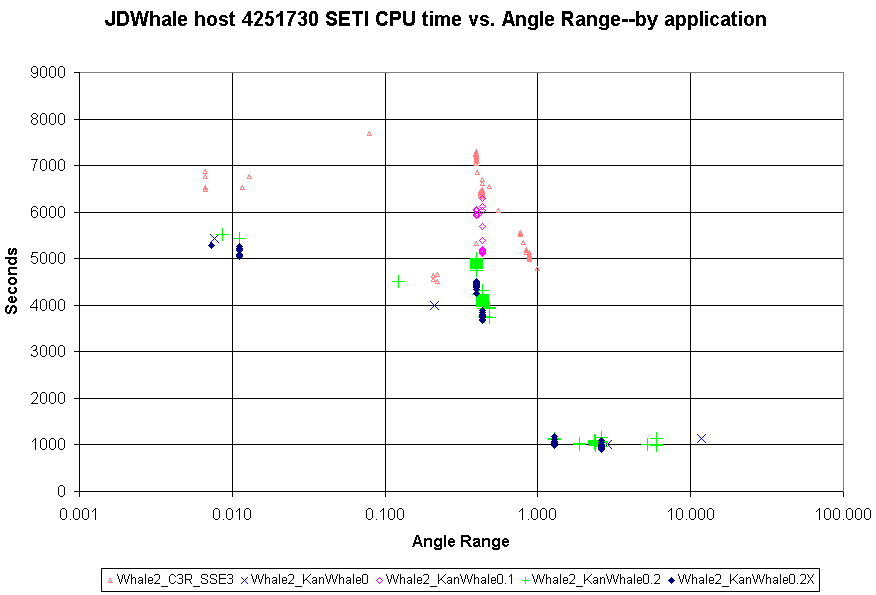
JDWhale said is Message 732256:
I've called this host Whale3 in the graph legend. Before that new graph in this post, let me mention that I've updated these graphs for Whale1 and Whale2 in situ so they'll display in their original messages on refresh. Or you can follow these links and refresh on arrival: Whale1 CPU vs. AR by ap Whale2 CPU vs. AR by ap The updated Whale1 and Whale2 graphs now include a useful amount of results near Angle Range 2.35. They also have a very clear different in scatter, with the E4500 results much more varied in CPU time at a given Angle Range than the Q6600. Finally, here is the new graph for the Smithfield host, for which I certainly concur that this version of the port is showing a very nice speedup. 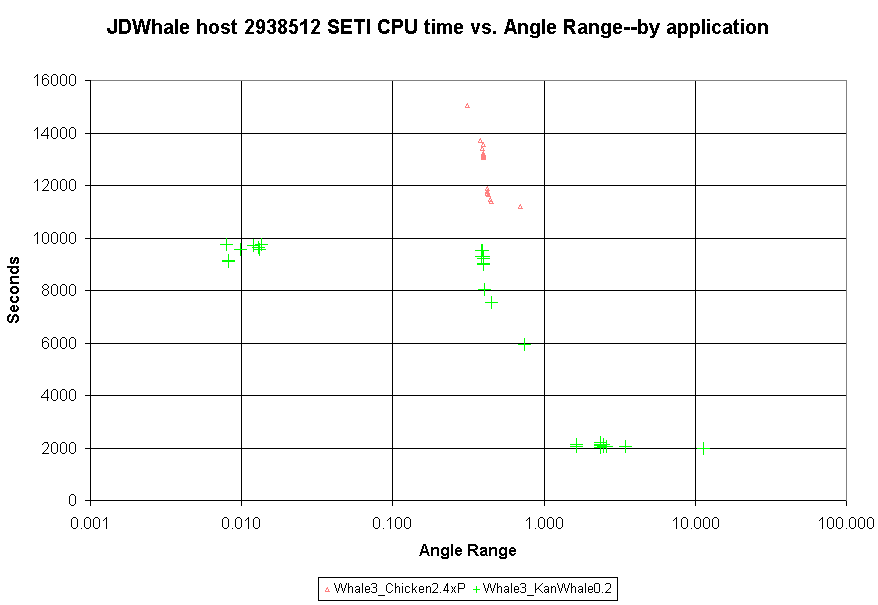 ID: 732790 · |
|
David Send message Joined: 19 May 99 Posts: 411 Credit: 1,426,457 RAC: 0
|
Finally, here is the new graph for the Smithfield host, for which I certainly concur that this version of the port is showing a very nice speedup. ARGH, STOP TEASING US! ;) OK that over, it sure looks like a fairly even spread of times for each of the WU ranges, and the 0.2 version looks like a nice update on what we thought was a really good 0.1 version! Definately need a wider beta test for this soon :D
ID: 732801 · |
|
JDWhale Send message Joined: 6 Apr 99 Posts: 921 Credit: 21,935,817 RAC: 3
|
archae86 wrote: The updated Whale1 and Whale2 graphs now include a useful amount of results near Angle Range 2.35. They also have a very clear different in scatter, with the E4500 results much more varied in CPU time at a given Angle Range than the Q6600. Thanks archae86, for collecting the data and generating the scatter plots. I've got a comment to make about the variation in CPU times being witnessed, especially pertaining to VHAR WUs on Whale1. I am scheduling these VHAR WUs to run one at a time vs. WUs of other ARs, there was one instance when I purposely ran two of these WUs concurrently, this can be seen when the CPU times came in near 1800sec vs. the 1000-1250sec when run one at a time. We know from past experience that the E4500 chip with it's 1MB L2 cache per core causes a severe performance penalty when these WUs run concurrently. Since these WUs typically come in bunches and often run concurrently at "high priority" due to the shortened deadlines, the data in the graph might be a bit misleading from what your "typical" user can expect. I'm controling Whale2 similarly, but have not allowed more than one to run at a time yet. That is going to change right now. I'm kicking off 4 VHAR WUs to run at the same time, so when the next datas are presented we should see some data points at the "worst case" location for the Q6600 Whale2. I do not expect as much variation as Whale1, but we should be able to see some variation from the 1050sec seen in the current plot. I'm sorry if by controlling what WUs are free to crunch at any given time is not entirely up to the BOINC scheduler, but I feel that I can get better throughput by taking some control to prevent known bottlenecks and raise overall performance. So, am I manipulating the data? Maybe yes, but I'm at least telling you about it, and why. Finally, here is the new graph for the Smithfield host, for which I certainly concur that this version of the port is showing a very nice speedup. <img snipped> To help fill in the blanks, I've just set Whale3 back to running KWSN_2.4_SSE3-Intel-P4_MB while there is some variation of ARs in the queue. This should help to paint the overall picture a bit better. I won't let it go for very long, just long enough to get some more data points for comparison. Regards, JDWhale ID: 732803 · |
|
David Send message Joined: 19 May 99 Posts: 411 Credit: 1,426,457 RAC: 0
|
I'm sorry if by controlling what WUs are free to crunch at any given time is not entirely up to the BOINC scheduler, but I feel that I can get better throughput by taking some control to prevent known bottlenecks and raise overall performance. So, am I manipulating the data? Maybe yes, but I'm at least telling you about it, and why. Maybe we need a JDWhale Boinc update to minimise the issues caused by these known bottlenecks (Big grin). Actually getting boinc to only run 1 (or 2???) VHAR WU at a time for multicore processors, provided the delaying wont cause problems with the deadline, might be a nice feature. It might mean that we cant all have a low WU queue, but since many of us run a 2 or 3 day queue anyway, moving the order slightly might not be a big issue. I guess your in the right seat to test what a Q6600 can handle in order to see where the limit lies - 1, 2, 3 or 4 VHAR WU's at a time before we see a real drop in speed.
ID: 732807 · |
|
archae86 Send message Joined: 31 Aug 99 Posts: 909 Credit: 1,582,816 RAC: 0
|
Thanks archae86, for collecting the data and generating the scatter plots.You are welcome, and I'll mention again that Fred W created the VBA I use to gather the data. I'm sorry if by controlling what WUs are free to crunch at any given time is not entirely up to the BOINC scheduler, but I feel that I can get better throughput by taking some control to prevent known bottlenecks and raise overall performance. So, am I manipulating the data? Maybe yes, but I'm at least telling you about it, and why.I have no illusions that my graphs, and their perfect representation of typical user experience, are the only target of your work, nor the most important. But thanks for letting us know. The whole topic of the interaction of multiple aps running on multi-CPU (or even multi-virtual CPU) systems is complex enough that I doubt most simple answers. I do know that on a non-tampered long-term comparison, my Q6600 and E6600 (Dual and Quad core) running at the same clock rate and RAM settings on virtually identical systems have drastically different CPU time scatter--especially in the VHAR range. The Q6600 variation, is much, much higher. I've just assumed that more severe memory contention is the short-hand reason. In this graph, Stoll3 is an E6600 host, and Stoll4 a Q6600, both moderately overclocked to 3.006 GHz, on the same motherboard and RAM settings. 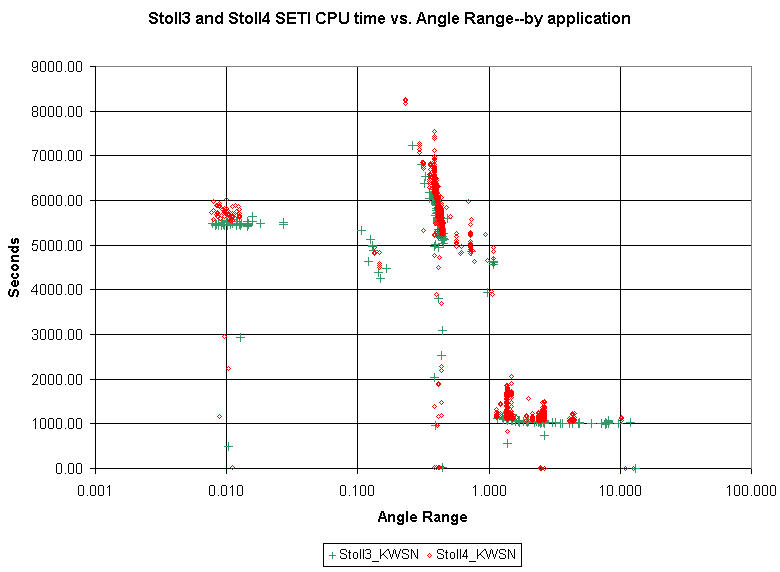 ID: 732811 · |
W-K 666  Send message Joined: 18 May 99 Posts: 19048 Credit: 40,757,560 RAC: 67
|
snip... I also have E6600 and Q6600 and at VHAR the E6600 nearly always does them in under 1200 sec, but on the Q6600 the times vary from 1150 to 1500 sec, using crunch3r apps. Plus the Q6600 has DDR3 1066 RAM compared to DDR2 800 on the duo. edit] Forgot to say that we appriciate all the work you guys are doing to get the V8 app ported to Windows. ID: 732813 · |
|
JDWhale Send message Joined: 6 Apr 99 Posts: 921 Credit: 21,935,817 RAC: 3
|
The 4 simultaneous VHAR WUs on Whale2 completed and posted. I'm happy to report only ~10% performance hit from running them one at a time on that particular host. Much less impact than running 2 simultaneous on Whale1 where the performance drop was closer to 70%. I am leaning to the smaller L2 cache per core being the culprit since Whale1 is actually running faster memory on a newer[better?] chipset and only feeding 2 cores. Whale1: Gigabyte GA-P35-DS3L & E4500 @ 2420MHz & DDR2-800 Whale2: Asus P5B-MX & Q6600 @ 2520MHz & DDR2-800 (though MoBo limited DDR2-667)I know the MoBo & CPUs are mismatched, catastrophic events of 8 March, remember? "WinterKnight" wrote:
In your case as with archae86 the issue might be more bandwith related as you're trying to feed 4 cores vs. 2 cores. I'm thinking that this "memory bottleneck" will likely disappear with the enhanced use of SIMD instructions offered up by Alex. Of course many H/W variables also come into play as we're seeing with Whale1 and it's limited L2 cache cause it's own issues. We are really seeing that all clock speeds are not created equal, even within the Allendale/Conroe chips. Of course, I might not have a clue since I'm really more of a coding hack than a hardware expert. What can I say, "Opinions are cheap" ;-) "David" wrote:
'Tis a bit funny that you raise that point. My original intent was to download the BOINC code and investigate implementing a different scheduling mechanism to raise "overall" performance, as well as adding some features to the Boinc Manager UI to make it easier to control groups of tasks. I never got around to anything more than building the libraries/executable when the challenge to port Alex-v8 code to Windows was made. I do hope to get back to the original intent some day soon, though since I'm only interrested in running S@H, any changes I make to Boinc scheduling code will likely have limited practical value away from S@H, thus will probably remain private :-( We'll see, I haven't had a chance to "look" into the Boinc code yet, beyond building it that is. Cheers, JDWhale ID: 732834 · |
|
David Send message Joined: 19 May 99 Posts: 411 Credit: 1,426,457 RAC: 0
|
In your case as with archae86 the issue might be more bandwith related as you're trying to feed 4 cores vs. 2 cores. I'm thinking that this "memory bottleneck" will likely disappear with the enhanced use of SIMD instructions offered up by Alex. Of course many H/W variables also come into play as we're seeing with Whale1 and it's limited L2 cache cause it's own issues. We are really seeing that all clock speeds are not created equal, even within the Allendale/Conroe chips. Of course, I might not have a clue since I'm really more of a coding hack than a hardware expert. What can I say, "Opinions are cheap" ;-) Wow I didnt think that Alex's additions would really make that much of a difference with the Quads, but you make it sound like the performance hit from running a few Very High Angle WU's might not be as bad as it currently is, so thanks to Alex (and everyone else - I know it's very much a group effort). We'll see, I haven't had a chance to "look" into the Boinc code yet, beyond building it that is. Thats OK we can wait a few weeks (Grin). Seriously though, getting the S@H application working more efficiently is, in my opinion, the first and most important step. Any Boinc updates may not really help other projects, but because I crunch 100% S@H at this time then anything that helps S@H is good ;)
ID: 732836 · |
|
Sutaru Tsureku Send message Joined: 6 Apr 07 Posts: 7105 Credit: 147,663,825 RAC: 5 
|
Thanks to all for the work!!  I don't have so much time to read every day this long thread..  I hope the final release of the new apps will be publish in the New Optimized Apps Links -- READ ONLY THREAD that all can profit from it..  
ID: 732859 · |
{kind=link}
{kind=link}
{kind=link}
{kind=link}

©2024 University of California
SETI@home and Astropulse are funded by grants from the National Science Foundation, NASA, and donations from SETI@home volunteers. AstroPulse is funded in part by the NSF through grant AST-0307956.