Kryten woes (Jan 31 2007)
Message boards :
Technical News :
Kryten woes (Jan 31 2007)
Message board moderation
| Author | Message |
|---|---|
 Matt Lebofsky Matt Lebofsky Send message Joined: 1 Mar 99 Posts: 1444 Credit: 957,058 RAC: 0 
|
Our usual database backup outage yesterday was a bit longer than usual because we were doing some experimenting with a new network route. More info to come about that at a later date. Let's just say this is something we've been working on for a year and once it comes to fruition we can freely discuss it. Anyway, there's a usual period of catch-up during which kryten (the upload server) drops TCP connections. Usually the rate of dropped connections decreases within an hour or so. Not the case this time. While most transactions were being served the past 20 hours, there were still a non-zero amount of dropped connections as of this morning. This was due to our old nemesis - the dropped NFS mount issue. To restate once again: kryten loses random NFS mounts around the network - this has something to do with its multiple ethernet connections but we still haven't really tracked down the exact cause. Since a simple reboot fixes the problem, this isn't exactly a crisis compared to other things. And since we were uploading results just fine for the most part during the evening, no alarms went off. Plus, frankly, this problem isn't very high priority as it will sort of just "time out" at some point in the future (kryten will be eventually replaced I imagine). [edit: we are now doing some more network testing, so the upload/servers will be going up and down for brief periods of time over the next hour or two] - Matt -- BOINC/SETI@home network/web/science/development person -- "Any idiot can have a good idea. What is hard is to do it." - Jeanne-Claude ID: 511311 · |
|
Pooh Bear 27 Send message Joined: 14 Jul 03 Posts: 3224 Credit: 4,603,826 RAC: 0
|
This was noticed by several people having issues finishing uploads and or downloads that were pending during the outage. I had a couple of machines that seemed to stall those transfers, while other transfers were fine (might be a bug in BOINC we have found?). It's almost like the one transfer had a DNS cache that would not let go. A stop and start of the BOINC program resolved this issue. So another thing for you to look into. The clients are all 5.8 and above on my systems that exhibited this error, but it looks like 5.4 clients did, also. ID: 511318 · |
|
Benher Send message Joined: 25 Jul 99 Posts: 517 Credit: 465,152 RAC: 0
|
So Matt, I see all 4 of the validators are running as processes on Kryten (the system you mentioned). Kryten has 4 CPUs so this should be ok depending on RAM bandwidth, etc. a. Would the NFS dropping cause one (or more) of the validator instances to claim it was "not running" b. Would spreading the validator instances across multiple servers slow it down, speed it up, or be the same in performance? Thanks, =Ben ID: 511323 · |
|
Fuzzy Hollynoodles Send message Joined: 3 Apr 99 Posts: 9659 Credit: 251,998 RAC: 0 |
So Matt, Kryten is in a bad state and they are looking for a replacement for it. Please check out the donation threads. "I'm trying to maintain a shred of dignity in this world." - Me 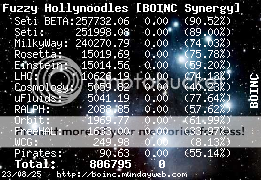
ID: 511326 · |
|
Matt Lebofsky Send message Joined: 1 Mar 99 Posts: 1444 Credit: 957,058 RAC: 0
|
a. Would the NFS dropping cause one (or more) of the validator instances to claim it was "not running." Yep. It seems over 90% of the time the NFS problems only affect the BOINC back end processes, and not uploads. This is because these processes link against libraries or read project configurations from a central location on our network. If these disappear, random things happen. b. Would spreading the validator instances across multiple servers slow it down, speed it up, or be the same in performance? Under normal operations there are hundred of thousands of uploaded results that are being processed by our back end processes (the validator, assimilators, and deleters). These processes *have* to be running on the same machine where the results are physically located or else the additional random-access NFS traffic would grind things to a halt. We tried it. It would be good to figure out what the problem is, but we'll hopefully just get a modern server replacement instead. It may just be this technology (which was state of the art circa 2000, and was cobbled together from used, donated parts) is showing signs of old age. - Matt -- BOINC/SETI@home network/web/science/development person -- "Any idiot can have a good idea. What is hard is to do it." - Jeanne-Claude ID: 511330 · |
|
Matt Lebofsky Send message Joined: 1 Mar 99 Posts: 1444 Credit: 957,058 RAC: 0
|
Update: Had to reboot it for the second time today. Sigh. - Matt -- BOINC/SETI@home network/web/science/development person -- "Any idiot can have a good idea. What is hard is to do it." - Jeanne-Claude ID: 511429 · |
|
zoom3+1=4 Send message Joined: 30 Nov 03 Posts: 65746 Credit: 55,293,173 RAC: 49
|
Update: Had to reboot it for the second time today. Sigh. It's too bad Sidius couldn't be used to replace Kryten. Have a good day. The T1 Trust, PRR T1 Class 4-4-4-4 #5550, 1 of America's First HST's 
ID: 511436 · |
|
littlegreenmanfrommars Send message Joined: 28 Jan 06 Posts: 1410 Credit: 934,158 RAC: 0 
|
Downloads don't seem to be a problem, inasmuch as they (intermittently) actually download. That at least means I haven't run out of work here. However, uploads to S@h are a continuing problem. BOINC also reports no connection. This is all going to be part of the process of getting things going again. Patience! The thing that worries me is my router seems to be misbehaving quite badly, and I have had to reboot it numerous times per day since the outage began. There seems to be nothing wrong, configuration-wise, so it makes me wonder if BOINC is doing something to my system as it tries to access the project. Whatever happens, I take my hat off to the people at S@h, as they obviously are working their bums off to fix poor old Kryten. 
ID: 511523 · |
|
Joe Court Send message Joined: 2 Sep 06 Posts: 5 Credit: 957,949 RAC: 0 
|
It's got to the stage where work has run out. I hope you get it sorted soon. ID: 511575 · |
|
Darth Dogbytes™ Send message Joined: 30 Jul 03 Posts: 7512 Credit: 2,021,148 RAC: 0
|
It's got to the stage where work has run out. I hope you get it sorted soon. Increase the size of your cache in your preferences. Account frozen... ID: 511576 · |
|
Joe Court Send message Joined: 2 Sep 06 Posts: 5 Credit: 957,949 RAC: 0
|
It's got to the stage where work has run out. I hope you get it sorted soon. It's currently set at 50GB. Is this not enough? ID: 511579 · |
|
littlegreenmanfrommars Send message Joined: 28 Jan 06 Posts: 1410 Credit: 934,158 RAC: 0
|
It's got to the stage where work has run out. I hope you get it sorted soon. Set "Connect to network about every" to 4 days is usually enough, although you can set this up to 10 days. You'll find it under general prefs
ID: 511581 · |
|
Joe Court Send message Joined: 2 Sep 06 Posts: 5 Credit: 957,949 RAC: 0
|
It's got to the stage where work has run out. I hope you get it sorted soon. I have it set to connect every 0.5 days. Is this too often for a system online 24/7? ID: 511583 · |
|
Kim Vater Send message Joined: 27 May 99 Posts: 227 Credit: 22,743,307 RAC: 0 
|
In that way you won't have many WU to crunch if servers are down. It's a bit tricky with that WU-cache. The more days you set - the more WU's you will get. Lets say you have a computer that finnished a WU in 2 hrs. It will return the result immidiatly. I've set the work-cache to 10 days and that gives me aprox 6 days of work with optimized clients. Kiva Greetings from Norway   Crunch3er & AK-V8 Inside ID: 511584 · |
|
Joe Court Send message Joined: 2 Sep 06 Posts: 5 Credit: 957,949 RAC: 0
|
Thanks for that. I've now set prefs for 10 days. All I need now is to actually download the work units it's listed. I suspect there is a network problem somewhere between my computer and seti's ID: 511589 · |
|
littlegreenmanfrommars Send message Joined: 28 Jan 06 Posts: 1410 Credit: 934,158 RAC: 0
|
S@h seems to have the situation under control, since a few hours ago. Hitting the update button on BOINC Manager should get your machine downloading 10 days' worth of WUs. Good luck!
ID: 511603 · |
|
Joe Court Send message Joined: 2 Sep 06 Posts: 5 Credit: 957,949 RAC: 0
|
I had got the list of WUs OK, but just could not download them. I've now started using a webcache and managed to download them all. It appears to be an issue on blueyonder network in UK that is cause of problem. People are reporting similar problems with other sites, such as Google, etc. Thanks for all help, at least I'll not be short of WUs now. ID: 511630 · |
|
mikey Send message Joined: 17 Dec 99 Posts: 4215 Credit: 3,474,603 RAC: 0
|
I had got the list of WUs OK, but just could not download them. Now you need to go to the Number Crunching Thread and click on the links to download an Optimized version. This should give you about a 20% boost in workunit output and a resultant boost in your RAC. Of course since Boinc can't quite figure out the workunit cache, this will mean your 10 day cache will drop to about 6 days or so. The numbers will still be at 10 days, but the units will only last about 6 using the optimized version. YES Berkeley supports the use of this, they do not provide Tech Support, but the site does that very well. I personally use Chicken's version, but there are others. 
ID: 511839 · |
|
PhonAcq Send message Joined: 14 Apr 01 Posts: 1656 Credit: 30,658,217 RAC: 1
|
I'm not sure this is the correct thread to reply to, but it is my theory that those who have more or less constant internet access should each pick a short queue, such as 1 day or less. Doing so would reduce the temporary storage requirements at CentralCommand because the results would come back faster (rather than be pending on a client machine for 10 days). For the case that Seti is down, we should also pick a backup project to do. For example, on one of my machines I select Einstein and give it an 8 resource share. This way Seti gets most of my cpu time (my choice); I 'minimize' the drag on the seti computers (at least storage); and I'm mostly covered for times kryten or someone is ill. May this Farce be with You ID: 512657 · |
|
mikey Send message Joined: 17 Dec 99 Posts: 4215 Credit: 3,474,603 RAC: 0
|
I'm not sure this is the correct thread to reply to, but it is my theory that those who have more or less constant internet access should each pick a short queue, such as 1 day or less. Doing so would reduce the temporary storage requirements at CentralCommand because the results would come back faster (rather than be pending on a client machine for 10 days). For the case that Seti is down, we should also pick a backup project to do. For example, on one of my machines I select Einstein and give it an 8 resource share. This way Seti gets most of my cpu time (my choice); I 'minimize' the drag on the seti computers (at least storage); and I'm mostly covered for times kryten or someone is ill. There was a study done a while back and it was determined that most units are not granted credit for almost 4 days. That is how long it took for the 'average' unit from the time it was sent out to come back and get credit for everyone that crunched it. Having a 1 day cache is okay but not necessarily ideal. For those that crunch multiple projects a 1 day or even less cache can be preferable. That way if one project is down the others will just pick up the slack and it will balance out later on, Boinc is DESIGNED to do that. If you only crunch for Seti, or any other project, and only have a 1 day cache and that project has problems, you will likely be out of work. For some that is unacceptable, hence the longer caches.
ID: 512759 · |

©2024 University of California
SETI@home and Astropulse are funded by grants from the National Science Foundation, NASA, and donations from SETI@home volunteers. AstroPulse is funded in part by the NSF through grant AST-0307956.